知识库(主要是标准的QA信息)匹配需求是对已经梳理出的大量标准QA对信息进行匹配,找出最符合用户问题的QA对进行回复,拆分主要的处理流程主要为如下两点:
- 标准QA信息入库索引;
- 通过对用户提出的问题进行处理,与索引库中的所有Q进行相似度计算,根据需要返回得分最高的top k个;
- 基于返回的top k问题有平台根据业务需要选择其中的某个问题的答案回复客服。
在引擎端处理的主要是前两点,即根据需要对索引入库的Q进行预处理,对用户问题进行同样的预处理,而后计算两者之间的相似度,返回得分最高的前几条。处理流程如下图示:
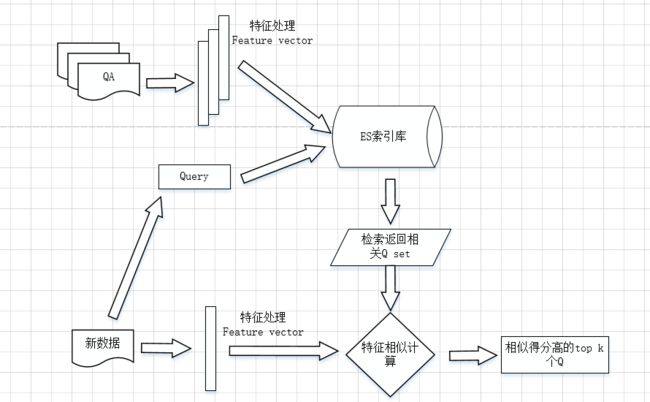
检索原理解析
索引检索这块使用了ES的morelikethis算法,morelikethis相似搜索,是通过tf-idf构建查询语句进而查找与给定语句的相似文档。生成morelikethis的相似查询语句的流程如下图示:
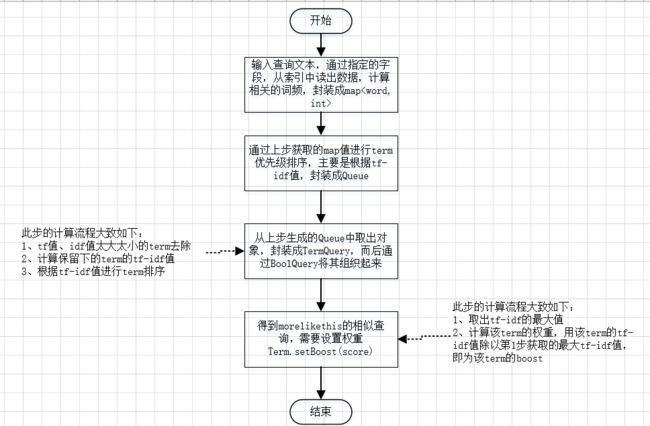
通俗讲,morelikethis相似检索不是传统的通过传入的文本检索索引获取信息,而是先通过类似传统的检索获取指定相似检索字段的所有数据,而后通过对这些数据进行筛选获取排粉较高的一些特征词,而后基于这些特征词生成一个新的查询语句,通过新的查询语句获取相关查询数据。
更进一步可以理解为通过结果找结果。整个的查询流程如下图示:

上述流程得到morelikethis的检索语句后,通过检索既可以获取结果,获取结果后,我们在对这些结果进行下一步的相似计算。
相似计算原理
通过检索我们获取了跟用户提交问题的相似的N个结果,相似计算流程是根据预处理阶段得到的Q指纹编码,通过与用户问题的指纹编码进行编辑距离计算,根据得分进行排序,最终返回最相似的top k。此阶段可以看做是推荐系统中的CTR阶段。
指纹编码选择使用simhash算法,simhash是一种局部敏感哈希算法,相对于传统hash算法对文本的hash是让整个分布更均匀,文本的微小变化就会引起hash值很大的变化;simhash的局部敏感对文本的微小变化感知不强,可以对相似的文本进行判断。
Q1:出了保险如何理赔
Q2:出了保险如何理赔?
simhash计算结果=====
1010111111010100011001100001111101011110111111010100011001101111
1010111111010100011001100001111101011110111111010100011001101111
传统hash计算结果=====
1092027993
-506870522
simhash 的计算流程如下:
- 文本预处理,一般包括分词、去除停用词等操作,获得预处理后的term集合;
- 基于获取的文本term集合,统计词频,去除超高词频(预设的阈值)词,基于分词的此行设置权重weight;
- 对每一个term进行hash转换,得到64位的hash码(0/1码),而后对每一位上基于1/0值进行正负权重转换,1位设置加weight、0位设置减weight;
- 针对文本的所有term的hash值,按照对应位置累加,得到一个64位的权重数组,然后将大于0的位置为1、小于等于0的位置为0,得到64位的0、1数组,作为该文本的新的hash值。
示例图(备注:图来自网络)如下所示:

对入索引的所有QA对的Q经过上述指纹处理后都会获得自己的指纹信息存储到索引字段中,用户新的问题经过预处理后可以得到自己的指纹,经过morelikethis的检索获取N条相似的信息,而后经过用户问题的simhash值域检索返回的N条信息进行汉明距离计算得到差值,选择差值排序小的 k个结果作为返回,而后经过sigmoid函数将差值转换为(0, 1)间的分值,将结果返回给业务方。
sigmoid归一化处理流程说明
通过编辑距离计算出来的距离为int变量,大于等于0,无法与NLU计算的结果在同一个维度上进行比对,为了将两者的结果都转换为(0,1)值之间,我们引入了sigmoid函数将编辑距离归一化处理。
Sigmoid函数可以将负无穷到正无穷的数值限制在0与1之间,为了进行计算,我们采用如下的形式:
函数绘图显示如下所示:
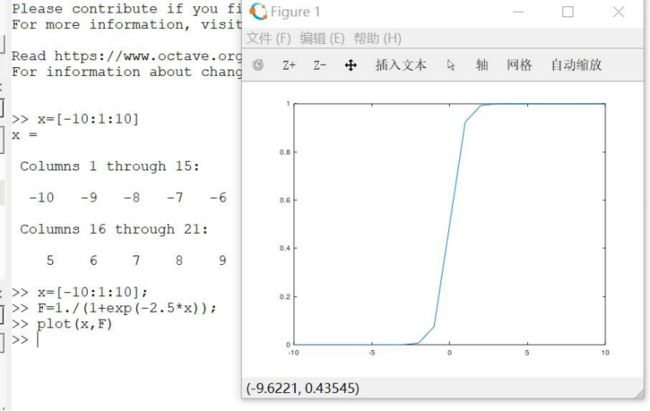
备注:图采用Octae绘制,示例使用代码
>> x=[-10:1:10];
>> F=1./(1+exp(-2.5*x));
>> plot(x,F)
>>
注意,在x=10时已经无限接近于1,结合前面介绍的汉明距离,我们对得出的汉明距离经转换后带入sigmoid函数中进行计算,转换: d = 10/d d不等于0(此处的10选择有待基于训练语料确定)。而后计算此次计算的相似度得分。