uthash
在软件开发中,不可不免的会使用到hash表,hash表的优点这里就不说了,以下介绍一个hash表的C实现,
uthash是用宏实现的,使用的时候非常方便,只用包含uthash.h即可。
Uthash的三个数据结构:
1. typedef struct UT_hash_bucket {
struct UT_hash_handle *hh_head;
unsigned count;
unsigned expand_mult;
} UT_hash_bucket;
UT_hash_bucket作用提供根据hash进行索引。
2.typedef struct UT_hash_table {
UT_hash_bucket *buckets;
unsigned num_buckets, log2_num_buckets;
unsigned num_items;
struct UT_hash_handle *tail; /* tail hh in app order, for fast append */
ptrdiff_t hho; /* hash handle offset (byte pos of hash handle in element */
unsigned ideal_chain_maxlen;
unsigned nonideal_items;
unsigned ineff_expands, noexpand;
uint32_t signature; /* used only to find hash tables in external analysis */
#ifdef HASH_BLOOM
uint32_t bloom_sig; /* used only to test bloom exists in external analysis */
uint8_t *bloom_bv;
char bloom_nbits;
#endif
} UT_hash_table;
UT_hash_table可以看做hash表的表头。
3. typedef struct UT_hash_handle {
struct UT_hash_table *tbl;
void *prev; /* prev element in app order */
void *next; /* next element in app order */
struct UT_hash_handle *hh_prev; /* previous hh in bucket order */
struct UT_hash_handle *hh_next; /* next hh in bucket order */
void *key; /* ptr to enclosing struct's key */
unsigned keylen; /* enclosing struct's key len */
unsigned hashv; /* result of hash-fcn(key) */
} UT_hash_handle;
UT_hash_handle,用户自定义数据必须包含的结构。
三种数据结构的关系如下:
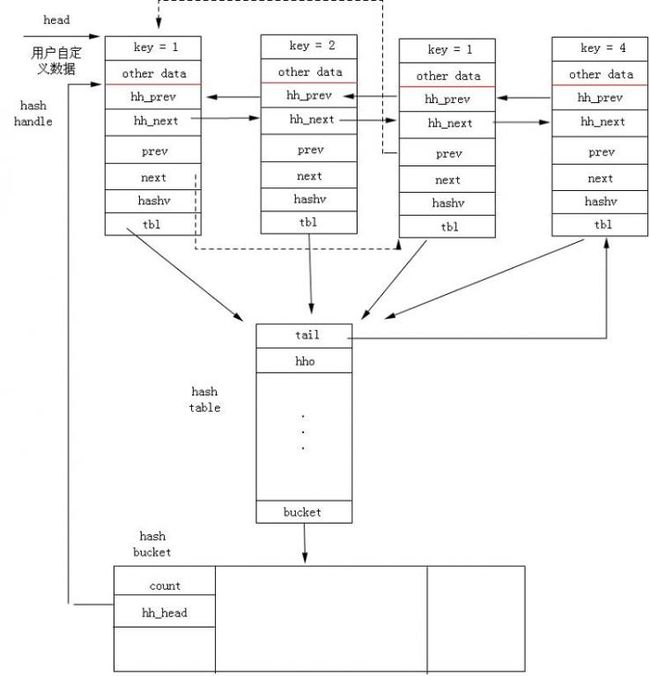
说明:
每一个节点(用户自定义的)必须包含一个UT_hash_handle hh
key:用户自定义,可以是int, string和指针。
hh_prev: 指向前一个UT_hash_handle
hh_next: 指向下一个UT_hash_handle
hashv:根据key计算出的hash值
prev: 指向前一个数据节点(Hash冲突时)
next: 指向下一个数据节点(Hash冲突时)
hho: 数据节点中hh于用户节点首地址的差。
--------------------------------------------我是分割线---------------------------------------
二、uthash的基本用法
由于C语言中,并没有对hash表这类的高级数据结构进行支持,即使在目前通用的C++中,也只支持栈、队列等几个数据结构,对于map,其实是以树结构来实现的,而不是以hash表实现。
uthash是一个C语言的hash表实现。它以宏定义的方式实现hash表,不仅加快了运行的速度,而且与关键类型无关的优点。
uthash使用起来十分方便,只要将头文件uthash.h包含进去就可以使用。
目前,uthash的最新版本(1.9)支持如下平台:
- Linux
- Mac OS X
- Windows using vs2008 and vs 2010
- Solaris
- OpenBSD
通常这足够通用了。唯一的不足是在windows下,在uthash这旧版本中,并不支持vs2008和2010,而是支持MinGW。
uthash支持:增加、查找、删除、计数、迭代、排序、选择等操作。
第一步:包含头文件
- #include "uthash.h"
第二步:自定义数据结构。每个结构代表一个键-值对,并且,每个结构中要有一个UT_hash_handle成员。
- struct my_struct {
- int id; /* key */
- char name[10];
- UT_hash_handle hh; /* makes this structure hashable */
- };
第三步:定义hash表指针。这个指针为前面自定义数据结构的指针,并初始化为NULL。
- struct my_struct *users = NULL; /* important! initialize to NULL */
第四步:进行一般的操作。
增加:
- int add_user(int user_id, char *name) {
- struct my_struct *s;
- s = malloc(sizeof(struct my_struct));
- s->id = user_id;
- strcpy(s->name, name);
- HASH_ADD_INT( users, id, s ); /* id: name of key field */
- }
查找:
- struct my_struct *find_user(int user_id) {
- struct my_struct *s;
- HASH_FIND_INT( users, &user_id, s ); /* s: output pointer */
- return s;
- }
删除:
- void delete_user(struct my_struct *user) {
- HASH_DEL( users, user); /* user: pointer to deletee */
- free(user); /* optional; it’s up to you! */
- }
计数:
- unsigned int num_users;
- num_users = HASH_COUNT(users);
- printf("there are %u users/n", num_users);
迭代:
- void print_users() {
- struct my_struct *s;
- for(s=users; s != NULL; s=s->hh.next) {
- printf("user id %d: name %s/n", s->id, s->name
- }
- }
排序:
- int name_sort(struct my_struct *a, struct my_struct *b) {
- return strcmp(a->name,b->name);
- }
- int id_sort(struct my_struct *a, struct my_struct *b) {
- return (a->id - b->id);
- }
- void sort_by_name() {
- HASH_SORT(users, name_sort);
- }
- void sort_by_id() {
- HASH_SORT(users, id_sort);
- }
要注意,在uthash中,并不会对其所储存的值进行移动或者复制,也不会进行内存的释放。
--------------------------------------------我是分割线---------------------------------------
uthash使用代码例子
- #include "uthash.h"
- #include <stdlib.h> /* malloc */
- #include <stdio.h> /* printf */
- #include <time.h>
- typedef struct example_user_t {
- int id;
- int cookie;
- UT_hash_handle hh;
- } example_user_t;
- int main(int argc,char *argv[]) {
- int i;
- example_user_t *user, *users=NULL;
- srand((unsigned int)time(NULL));
- /* create elements */
- for(i=0;i<10;i++) {
- if ( (user = (example_user_t*)malloc(sizeof(example_user_t))) == NULL) exit(-1);
- user->id = rand()%100;
- user->cookie = i*i;
- HASH_ADD_INT(users,id,user);
- }
- for(user=users; user != NULL; user=(example_user_t*)(user->hh.next)) {
- printf("user %d, cookie %d\n", user->id, user->cookie);
- }
- return 0;
- }
---------------------------------我是分割线-------------------------------------
4. 其他类型key的使用
本节主要关于key值类型为其他任意类型,例如整型、字符串、指针、结构体等时的用法。
注意:在使用key值为浮点类型时,由于浮点类型的比较受到精度的影响,例如:1.0000000002被认为与1相等,这些问题在uthash中也存在。
4.1. int类型key
前面就是以int类型的key作为示例,总结int类型key使用方法,可以看到其查找和插入分别使用专用接口:HASH_FIND_INT和ASH_ADD_INT。
4.2. 字符指针char*类型key与字符数组char key[100]类型key
特别注意在Strting类型中,uthash对指针char*和字符数组(例如char key[100])做了区分,这两种情况下使用的接口函数时不一样的。在添加的时候,key的类型为指针时使用接口函数HASH_ADD_KEYPTR,key的类型为字符数组时,使用接口函数HASH_ADD_STR,除了添加的接口不一样外,其他的查找、删除、变量等接口函数都是一样的。
4.3.使用地址作为key
在uthash中也可使用地址做key进行hash操作,使用地址作为key值时,其类型为void*,这样它就可以支持任意类型的地址了。在使用地址作为key时,插入和查找的专用接口函数为HASH_ADD_PTR和HASH_FIND_PTR,其余接口是一样的。
4.3.其他非常用类型key
在uthash中还可使用结构体作为key,甚至可以采用组合的方式让多个值作为key,这些在其官方的网站张均有较详细的使用示例。在使用uthash需要注意以下几点:
在定义hash结构体时不要忘记定义UT_hash_handle的变量
需确保key值唯一,如果插入key-value对时,key值已经存在,再插入的时候就会出错。
不同的key值,其增加和查找调用的接口函数不一样,具体可见第4节。一般情况下,不通类型的key,其插入和查找接口函数是不一样的,删除、遍历、元素统计接口是通用的,特殊情况下,字符数组和字符串作为key值时,其插入接口函数不一样,但是查找接口是一样的