统计学习方法笔记——感知机
- 简介
- 感知机模型
- 感知机学习策略
- 数据集的线性可分性
- 感知机学习策略
- 感知机学习算法
- 感知机学习算法的原始形式
- 算法的收敛性
- 感知机学习算法的对偶形式
- 总结
简介
感知机(perceptron)是二类分类的线性分类模型,输入为特征向量,输出为+1和-1二值。感知机学习旨在求出将训练数据进行线性划分的分离超平面,属于判别模型。通过导入基于误分类的损失函数,利用梯度下降对损失函数进行极小化,求得感知机模型。感知机学习算法分为原始形式和对偶形式。于1957年由rosenblatt提出,它是神经网络与支持向量机的基础。
感知机模型
定义:假设输入空间(特征空间)是 X⊆Rn X ⊆ R n ,输出空间是 Y=+1,−1 Y = + 1 , − 1 ,输入 x∈X x ∈ X 表示实例的特征向量,对应于输入空间的点;输出 y∈Y y ∈ Y 表示实例的类别。由输入空间到输出空间的如下函数称为感知机:
其中,w和b为感知机模型参数, w∈Rn w ∈ R n 叫做权值或权值向量, b∈R b ∈ R 叫做偏置(bias),sign是 符号函数,即:
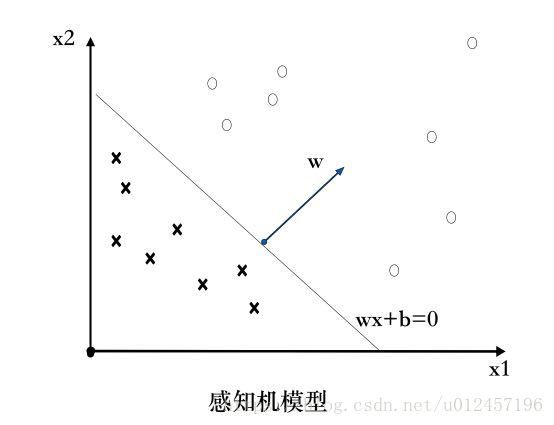
感知机有如下几何解释:线性方程
对应于特征空间中的一个 超平面S,其中w是超平面的 法向量,b是超平面的截距,这个超平面将特征空间划分为两个部分,将特征向量分为正负两类,因此超平面S被称为 分离超平面,如下图所示:
感知机学习策略
数据集的线性可分性
定义:给定义一个数据集T,如果存在某个超平面S
能够将数据集的正负实例点完全正确的分到超平面的两侧,即对所有的 yi=+1 y i = + 1 ,有 w⋅xi+b>0 w ⋅ x i + b > 0 ,反之也成立。则称数据集T为 线性可分数据集。
感知机学习策略
假设数据集是线性可分的,则需要求得一个分离超平面,即确定模型参数w,b,需要一个学习策略,定义(经验)损失函数并将损失函数极小化。
损失函数的一个自然选择是误分类点的总数,但是,这样损失函数不是w,b的连续可导函数,不易优化。所以损失函数选择误分类点到超平面S的总距离。首先写出输入空间 Rn R n 中任意一点到超平面S的距离公式:
其中||w||是w的 L2 L 2 范数。
公式证明:
点 x0 x 0 到超平面S: w⋅x+b=0 w ⋅ x + b = 0 的距离d的计算过程如下:
- 设点 x0 x 0 在超平面S上面的投影为 x1 x 1 ,则 w⋅x1+b=0 w ⋅ x 1 + b = 0
- 由于向量\vec{x_0 x_1}与S平面的法向量w平行,所以:
又有:
所以:
变形抽出d**得证**:
看到网上还有种证明方法也挺有意思的,有兴趣的点击 这里。
对于误分类的数据 (xi,yi) ( x i , y i ) 来说, −yi(w⋅xi+b)>0 − y i ( w ⋅ x i + b ) > 0 成立,因为误分类的数据真实结果 yi y i 和预测值总是符号相反, yi y i 的取址为+1和-1。所以误分类的点到超平面S的距离是:
这样,假设平面的所有误分类点的集合M,到超平面S的总距离为:
不考虑 1||w|| 1 | | w | | ,就得到了感知机学习的损失函数。其中 y(w⋅x+b) y ( w ⋅ x + b ) 称为样本点的函数间隔。至于为什么能够省略 1||w|| 1 | | w | | ,这个是因为我们进行梯度求极小值的时候更新的是参数,省略的项并不会影响到参数的值,最终的参数的结果还是一样的。而且我们的数据集已经假设可以线性可分的了,最终的损失值会为0。
给定数据集T, xi∈X=Rn x i ∈ X = R n , yi∈Y=+1,−1 y i ∈ Y = + 1 , − 1 。感知机 sign(w⋅x+b) s i g n ( w ⋅ x + b ) 学习的损失函数定义为:
显然,损失函数是非负的。若无误分类的点,损失函数的值就是0,且误分类点离超平面越近,损失函数值就越小。
感知机学习算法
感知机学习算法的原始形式
感知机学习问题转化为求解损失函数式(2.4)最优化问题。最优化的方法是随机梯度下降法。求参数w,b(也算选取一个超平面),使其为以下损失函数极小化问题的解:
随机选取一个误分类点,使用梯度下降对w,b进行更新。
算法2.1(原始形式)
输入:训练集T,其中输入是 X⊆Rn X ⊆ R n ,输出空间是 Y=+1,−1 Y = + 1 , − 1 ;学习率 η(0<η≤1) η ( 0 < η ≤ 1 )
输出:w,b;感知机模型 f(x)=sign(w⋅x+b) f ( x ) = s i g n ( w ⋅ x + b )
1. 选取初值 w0,b0 w 0 , b 0
2. 在训练集中选取数据 (xi,yi) ( x i , y i )
3. 若 yi(w⋅xi+b)≤0 y i ( w ⋅ x i + b ) ≤ 0
4. 转至2,直到训练集中没有误分类点。
注:感知机学习算法由于采取不同的初值或者选取不同的误分类点,解可以不同。
算法的收敛性
这个证明说明对于线性可分数据集感知机学习算法原始形式收敛,即经过有限次迭代可以得到一个将训练数据集完全正确划分的分离超平面及感知机模型。
为了方便推导,将偏置b并入权重w,记作 w∧=(wT,b)T w ∧ = ( w T , b ) T ,同样也将输入向量扩充,记作 x∧=(xT,1)T x ∧ = ( x T , 1 ) T ,显然, w∧⋅x∧=w⋅x+b w ∧ ⋅ x ∧ = w ⋅ x + b
定理(Novikoff):假设数据集T是线性可分的,其中 xi∈X=Rn,yi∈Y=−1,+1,i=1,2,...N x i ∈ X = R n , y i ∈ Y = − 1 , + 1 , i = 1 , 2 , . . . N ,则:
(1) 存在满足条件 ||w∧opt||=1 | | w ∧ o p t | | = 1 的超平面 w∧opt⋅x∧=wopt⋅x+bopt=0 w ∧ o p t ⋅ x ∧ = w o p t ⋅ x + b o p t = 0 将数据集完全正确分开;且存在 γ>0 γ > 0 ,对所有的i=1,2…,N
(2) 令 R=max1≤i≤N||x∧i|| R = m a x 1 ≤ i ≤ N | | x ∧ i | | ,则感知机算法(2.1)在训练数据集上面的误分类次数k满足不等式:
这里的证明部分略,在统计学习方法书上写的很详细了,理解也没什么难点。
因此这个定理表明误分类的次数k是有上界的,有限次搜索能够找到分离超平面。换句话说,当数据集可分时,感知机学习算法的原始形式迭代是收敛的。
感知机学习算法的对偶形式
对偶形式的基本思想是:将w和b表示为实例 xi x i 和标记 yi y i 的线性组合的形式,通过求解其系数而求得w和b,可假设初始值 w0,b0 w 0 , b 0 均为0,对误分类点通过
逐步修改w,b,设修改了n次,则w,b关于 (xi,yi) ( x i , y i ) 的增量分别是 αiyixi α i y i x i 和 αiyi α i y i ,这里 αi=niη α i = n i η ,所以最后学习到的w,b可以表示为:
注:当 η=1 η = 1 时,表示第i个实例点由于误分类而进行更新的次数。实例点更新次数越多,代表它距离分离超平面越近,也就越难正确分类。
**算法2.2(感知机学习算法的对偶形式)
输入:线性可分的数据集T,其中输入是 X⊆Rn X ⊆ R n ,输出空间是 Y=+1,−1 Y = + 1 , − 1 ;学习率 η(0<η≤1) η ( 0 < η ≤ 1 ) 。
输出: α,b α , b ;感知机模型 f(x)=sign(∑Nj=1αjyjxj⋅x+b) f ( x ) = s i g n ( ∑ j = 1 N α j y j x j ⋅ x + b ) ,其中 α=(α1α2.....,αN)T α = ( α 1 α 2 . . . . . , α N ) T 。
(1) α←0 α ← 0 , b←0 b ← 0
(2) 在训练集中选取数据 (xi,yi) ( x i , y i )
(3) 如果 yi(∑Nj=1αjyjxj⋅x+b)≤0 y i ( ∑ j = 1 N α j y j x j ⋅ x + b ) ≤ 0 (这个点误分类了),则更新值:
(4) 转至(2)直到没有误分类的数据。
对偶形式中的训练实例仅以内积的形式出现。为了方便,可以预先将训练集实例间的内积计算出来并以矩阵形式存储,这个矩阵就是Gram矩阵:
与原始形式一样,对偶形式的迭代是收敛的,存在多个解。
以上的过程通俗一点的讲法就是从训练集中选取 x1,x2..xn x 1 , x 2 . . x n ,若哪个是误分类点,则更新对应的 xi x i 的 αi α i 和b,然后从头开始选取,直到所有的点都正确分类。这段过程的例子在书上介绍很详细,结合书本看更好。
总结
- 感知机是根据输入实例的特征向量x对其进行二类分类的线性分类模型:
f(x)=sign(w⋅x+b) f ( x ) = s i g n ( w ⋅ x + b )
感知机模型对应于输入空间中的分离超平面 w⋅x+b=0 w ⋅ x + b = 0 - 感知机学习的策略是极小化损失函数:
minw,bL(w,b)=−∑xi∈Myi(w⋅x0+b) m i n w , b L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x 0 + b )
损失函数对应于误分类点到分离平面的总距离 - 感知机学习算法是基于随机梯度下降法的对损失函数的最优化算法,有原始形式和对偶形式。原始形式中,首先任意选取一个超平面,然后用梯度下降法不断极小化目标函数。在这个过程中使用随机梯度下降。最终求出合适的w和b。在对偶形式中,是间接的求w和b,通过将w和b表示为 xi x i 和 yi y i 的线性组合,然后求解它的系数 αi α i 来求出w和b,其中 w=α1x1+α2x2+..αNxN w = α 1 x 1 + α 2 x 2 + . . α N x N
- 当训练集线性可分时,感知机学习算法是收敛的。在训练集上面误分类次数k满足不等式:
k≤(Rγ)2 k ≤ ( R γ ) 2
算法有无穷多个解,根据初值的选取或迭代顺序而不同。