预训练模型性能提升策略及代码实战
写在前面
自从BERT出现以来,越来越多的优秀的预训练模型如雨后春笋般层出不穷,这给我们处理NLP任务带来了极大的便利,身处这么一个时代,能随意使用这些预训练模型无疑是很舒适的一件事情,但是预训练模型的使用也有着不少技巧,一些好的模型策略甚至能带来显著意义上的性能提升。博主最近也是赋闲在家,闲来无事就去kaggle打了个情感抽取的比赛:Tweet-Sentiment-Extraction,刚好总结一下看到的一些提升性能的策略。
主要参考文献:
1.新手入门 Kaggle NLP类比赛总结:https://zhuanlan.zhihu.com/p/109992475
2.https://www.kaggle.com/c/tweet-sentiment-extraction/notebooks
1.文本处理
1.文本截断。常用的截断的策略有三种:
-
pre-truncate(截断前文)
-
post-truncate(截断末尾)
-
middle-truncate (head + tail,去除中间文本)
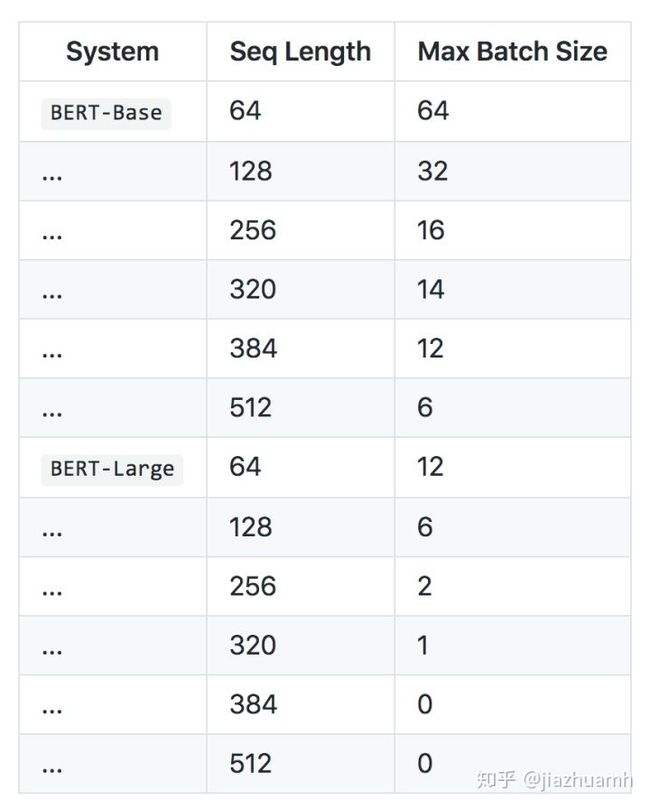
有研究对比了三种策略的效果,head+tail 最优,这也符合我们的直觉,一般文章或段落的开头结尾往往会包含重要信息,截掉中间部分信息丢失最少。当然,这也不是绝对的,建议三种方法都尝试,比较后挑选,或者都保留,后期做融合。附一张Bert输入文本长度和batch size的关系表。
2.文本扩增。NLP 中,文本扩增比较常用且有效的方法是基于翻译的,叫做 back translation。原理非常简单,是将文本翻译成另一种语言,然后再翻译回来。但是由于没有免费好用的翻译工具,所以一般而言可行性并不大。
3.Hard negative sampling。在 NLP 问答任务中,需要从一篇文章中寻找答案,一种常用的建模方法是将文章分割成多个 segment,分别与问题构成句子对,然后做二分类。这时候只有一个正样本,其他都是负样本,如果不对负样本做下采样的话,数据集会非常庞大,并且模型看到的多数都是负例。下采样可以减小数据集规模,从而节省模型训练的时间和资源消耗,这样才有可能尝试更多的模型和策略。这里推荐使用 hard negative sampling, 它的思想是保留那些对模型而言比较“难”的负样本,这样可以增加难度,迫使模型学到更多有用的特征。
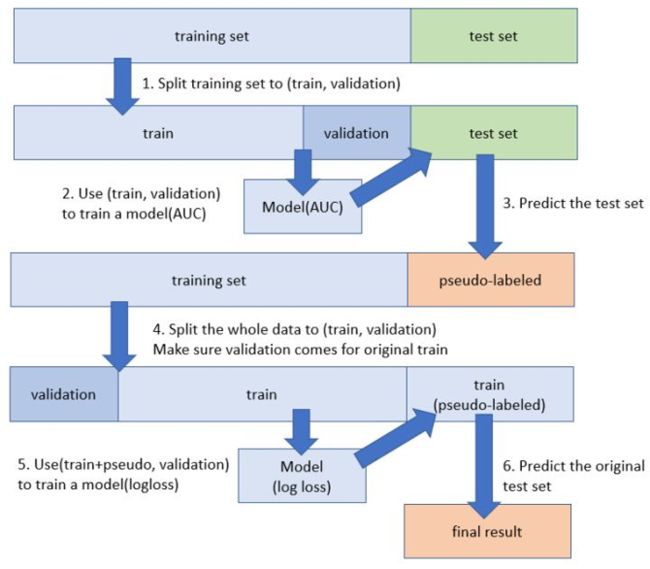
4.Pseudo-labeling。伪标注是一种半监督方法,在众多比赛中被验证有效而广泛使用,步骤如下:
1. 训练集上训练得到 model1; 2. 使用 model1 在测试集上做预测得到有伪标签的测试集; 3. 使用训练集+带伪标签的测试集训练得最终模型 model2;
伪标签数据可以作为训练数据而被加入到训练集中,是因为神经网络模型有一定的容错能力。需要注意的是伪标签数据质量可能会很差,在使用过程中要多加小心,比如不要用在 validation set 中。
5.随机词替换 ( EDA 技术 )。通常是随机地选择文本中一定比例的词,并对这些词进行同义词替换、删除等简单操作,不像回译等模型,需要外部预训练好的模型的辅助。EDA ( Easy data augmentation )主要包含四种操作:同义词替换、随机插入、随机交换和随机删除。
2.预训练模型向量表示
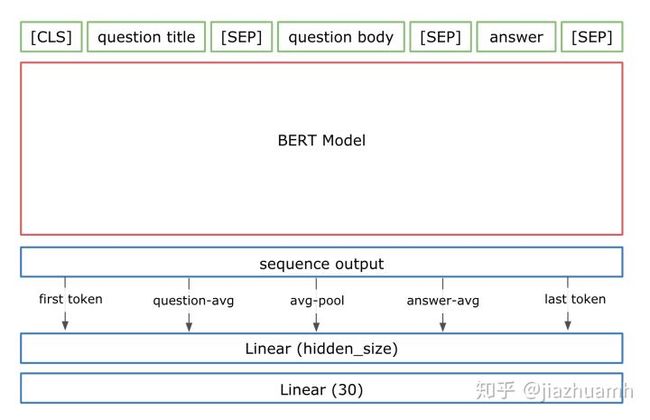
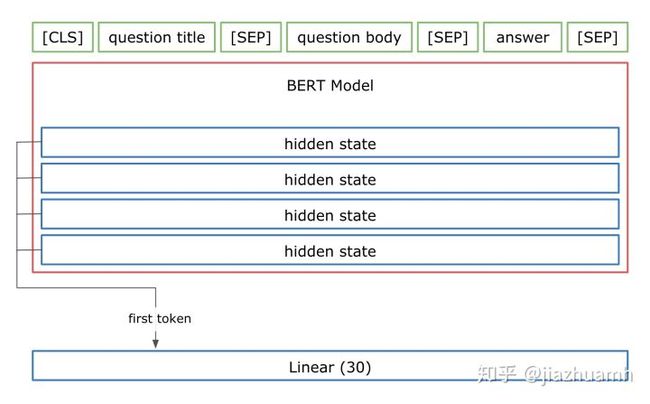
文本特征经过 Encoder 编码后变成了啥?以12层的bert-base为例,我们得到了 transformer 12层的 hidden states,每一层的维度为 B x L x H (B 表示 batch size,L 表示 Seq Length,H 表示 Hidden dim)。一般认为最后一层的第一个 token (也即 [CLS]) 对应的向量可以作为整个句子(或句子对)的向量表示,也即,包含了从文本中提取的有效信息。但在比赛中可以看到各种花式操作,并且都得到了明显的效果提升,比如:
-
取最后一层所有 token 对应的向量做融合;
-
取所有层的第一个 token 对应的向量做融合;
-
取最后四层的所有 token 对应的向量,加权重(可学习)融合;
kaggle 上有个帖子反对直接无脑使用 [CLS] 作为句子的向量表示,给出了一些尝试或改进的方向,值得一看:[ Let's Complicate Things Bert]。
这里直接贴出一些 winner solutions 里用到的结构,大家在使用过程中可以适当借鉴,也可以自定义一些适合自身任务的结构。
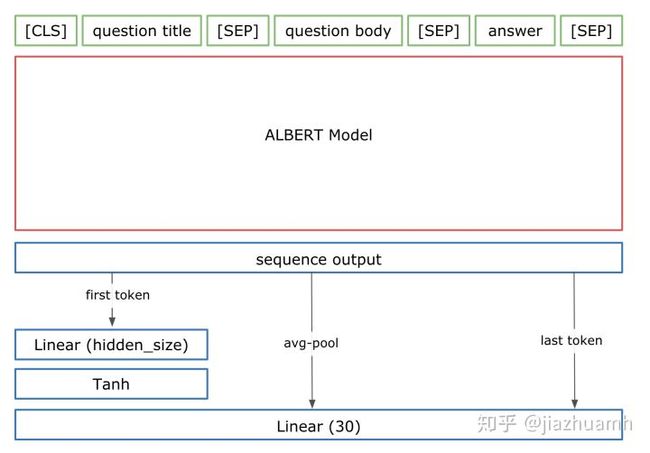

3.分类器
一般为一层或多层的全连接网络,最终把特征的向量表示映射到 label (target) 维度上。这部分比较灵活,可以做很多尝试,比如使用不同的激活函数、Batch Normalization、dropout、使用不同的损失函数甚至根据比赛 metric 自定义损失函数等。这里列出一些广泛使用的小技巧:
1.Multi-Sample Dropout。使用连续的dropout,可以加快模型收敛,增加泛化能力,详细见论文,代码如下:
dropouts = nn.ModuleList([
nn.Dropout(0.5) for _ in range(5)
])
for j, dropout in enumerate(dropouts):
if j == 0:
logit = self.fc(dropout(h))
else:
logit += self.fc(dropout(h))2.辅助任务。多任务学习在 NLP 领域也很常见,通过设计一些与目标任务相关的辅助任务,有时也可以获得不错的提升。在 Jigsaw Unintended Bias in Toxicity Classification 比赛中,第一名就采用了辅助任务的方法。
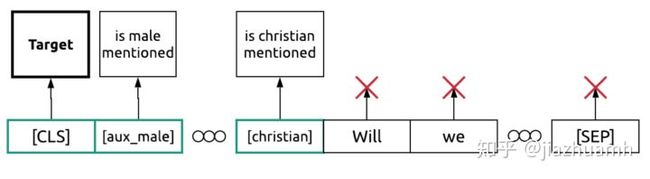
图中 Target 是比赛要预测的目标,is male mentioned、is christian mentioned 等是一些辅助目标,通过这些辅助目标提供的监督信号,也可以对模型的训练和最终效果提供帮助。
3.处理分类类别不均衡问题。调整模型预测结果的概率的阈值(最常见与F1 score问题当中,在Micro F1 score上面做细微调整);
在各类比赛中,最经典的三种微调方法:①对类别较少的样本的预测概率进行排序,取topN的元素作为最终结果;②对同一个样本的每个类的概率进行对比,如果两个类别的预测概率类似(自定义阈值),可以对将预测结果修改为类别个数较少的那个;③对预测结果进行再学习。
4.模型集成
1.模型内部集成。因为神经网络的训练代价较大,为了能用最少的时间来得到最好最鲁棒的结果,我们对我们单个神经网络进行内部集成,通过内部集成,我们的单模型的效果都往往接近模型的最好的结果,细节如下:
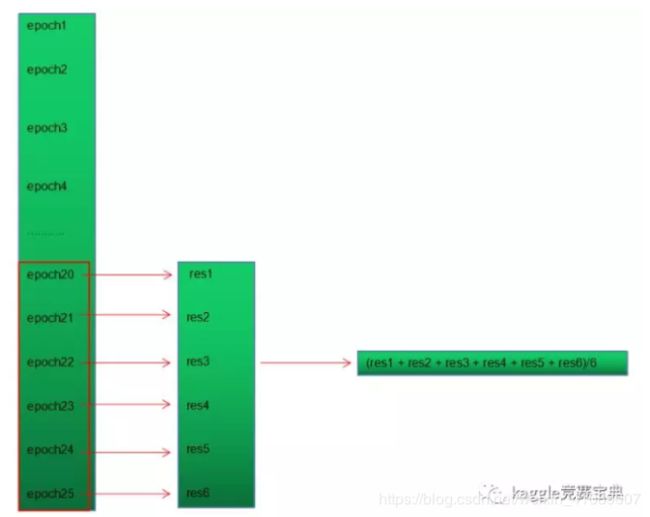
2.模型间集成。
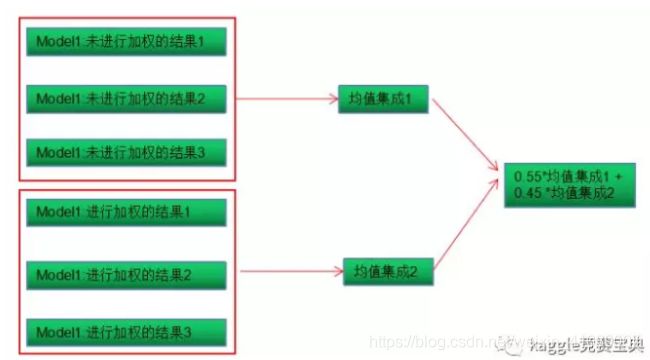
3.模型分段集成。
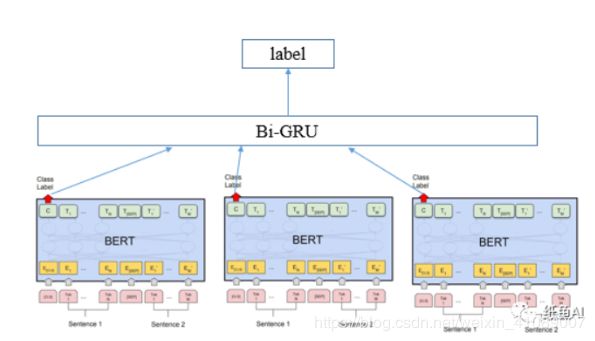
4.使用多折交叉验证,多折交叉验证的效果会明显好于单折。多折交叉和融合往往都能带来一定的稳定性和性能的提升。不过多折也会增加训练的时长,所以往往在先调参确定好模型后再进行多折交叉。
5.All data训练,在之前的训练中会使用一部分作为验证集,但是当你确定了所有超参数后你就可以尝试把所以数据拿过来盲跑,这样训练数据会多一点,不过缺点是拿不到本地的开发集测试结果。
代码实战
这里分享一个上述比赛的代码,同时对某些策略做一个验证。
代码过长,所以放到github上了:https://github.com/ZJUhjx/Tweet-Sentiment-Extracion
首先是直接使用Roberta base,3 epoch,32 batch size,score:0.699
然后使用Roberta base,5折交叉,3 epoch,32 batch size,score:0.712
Roberta-base model,5折交叉,取最后三层hidden输出作为均值,3 epoch,32 batch size,score:0.712
Roberta-base model,伪标签,5折交叉,取最后三层hidden输出作为均值,3 epoch,32 batch size,score:0.711
Roberta-base model,连续dropout,5折交叉,取最后三层hidden输出作为均值,3 epoch,32 batch size,score:0.710
可以看到,有些策略并不是很好用,果然还是要实践出真知~
(模型融合实验部分还在做,应该有提升,但是我的小本已经闻到显卡的香气了。。。)