周董来一杯莫吉托,爬取B站弹幕,看看周董的新歌《Mojito》,他的粉丝们说了什么
近2个月没写代码了,之前去做短视频去了,本文就当开开荤吧
本文仅供学习与参考,请勿于商用!!!
一、B站弹幕采集
目的地址:https://www.bilibili.com/video/BV1PK4y1b7dt?t=1
1.打开fillder 抓个包

一堆请求,看了头疼,清空,单独把评论区刷新抓包。于是有了它,它,它。。。
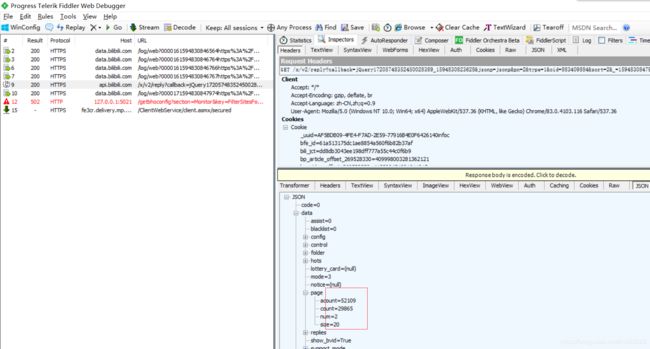


明眼人一看,数据找到了。这时候我们要分析数据源了。
2.数据源解析
多点几页评论(下一页),看看数据,把对应的URL提取出来,并进行分析。

通过分析和尝试请求,把没有用的,与有用都区分出来。得出以下格式 URL
https://api.bilibili.com/x/v2/reply?pn={页码}&type=1&oid={视频cid}&sort={弹幕排序方式}&_={时间戳/毫秒}
3.细节化,再次分析
通过第二步,可以找到评论信息,但是还是存在问题,评论中回复的信息只显示3条,其它的评论中的回复被隐藏了。那再抓包与分析看看。Fiddler清除记录,再刷新回复区。
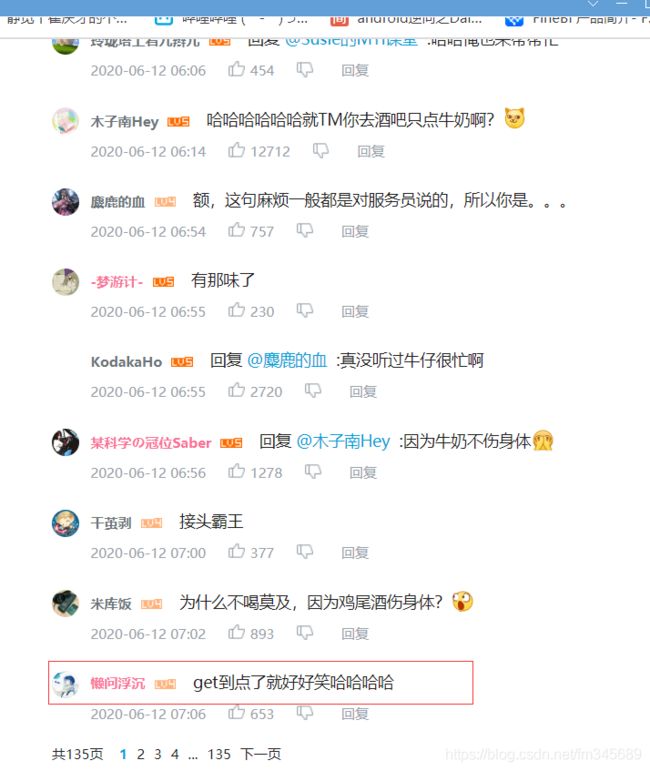

很容易就找到了。
分析中。。。。
分析中。。。。
分析中。。。。
![]()
得出下面有用的URL
# 注 就叫回复时cid吧 的参数在第二步URL中的数据中找到,rpid_str 参数
https://api.bilibili.com/x/v2/reply/reply?pn={页码}&type=1&oid={视频cid}&ps={回复显示条数}&root={就叫回复时cid吧}&_={时间戳/毫秒}
4.敲代码吧
代码清单:
# -*- coding: utf-8 -*-
# @Time : 2020/7/16 0:28
# @Author : hccfm
# @File : 弹幕爬取.py
# @Software: PyCharm
"""
采集某站中的弹幕信息
"""
import requests
import json
import time
import sys
import logging
import pymongo
class Mojito():
def __init__(self):
self.headers = {
"Host": "api.bilibili.com",
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
"Accept": "*/*",
"Sec-Fetch-Site": "same-site",
"Sec-Fetch-Mode": "no-cors",
"Sec-Fetch-Dest": "script",
"Referer": "https://www.bilibili.com/video/BV1ys411m773",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
}
self.myclient = pymongo.MongoClient("mongodb://localhost:27017/")
self.mydb = self.myclient["bilibili_Mojito"]
self.mycol = self.mydb["revert"]
def download_page(self,url):
"""
下载页面
:return:
"""
response = requests.get(url, self.headers)
if response.status_code == 200:
return response
sys.exit(1)
def parse_data(self,data):
"""
解析数据
:return:
"""
data_list = []
j_data = json.loads(data.content)
replies = j_data.get('data').get('replies')
for review in replies:
uname = review.get('member').get('uname')
sex = review.get('member').get('sex')
content = review.get('content').get('message')
like = review.get('like')
# 评论下的交流
rpid_str = review.get('rpid_str')
re_page_max = review.get('rcount') // 20 + 1
data_list.append([{"uname":uname, "sex":sex, "content":content, "like":like},rpid_str,re_page_max])
return data_list
def save_data(self,data):
"""
存储数据
:return:
"""
# print(data)
self.mycol.insert_one(data)
def main(self,base_url, page_max, mv_cid, revert_url):
"""
main
:return:
"""
for page in range(1, page_max + 1):
time_ = int(time.time() * 1000)
url = base_url.format(page=page, mv_cid=mv_cid, time=time_)
json_data = self.download_page(url)
data_list = self.parse_data(json_data)
for data_ in data_list:
self.save_data(data_[0])
if data_[-1] > 1:
for pn in range(1, data_[-1]):
time_ = int(time.time() * 1000)
re_url = revert_url.format(page=pn,mv_cid=mv_cid,rpid_str=data_[-2],time=time_)
re_json_data = self.download_page(re_url)
re_data_list = self.parse_data(re_json_data)
for re_data in re_data_list:
self.save_data(re_data[0])
print("第"+ str(page) + '页完成')
if __name__ == '__main__':
base_url = 'https://api.bilibili.com/x/v2/reply?pn={page}&type=1&oid={mv_cid}&sort=2&_={time}'
revert_url = 'https://api.bilibili.com/x/v2/reply/reply?pn={page}&type=1&oid={mv_cid}&ps=20&root={rpid_str}&_={time}'
mv_cid = '883409884'
page_max = 1495
mojito = Mojito()
mojito.main(base_url, page_max, mv_cid, revert_url)
5.数据结果
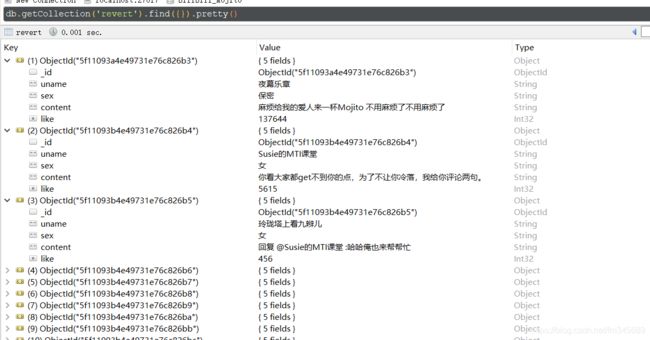
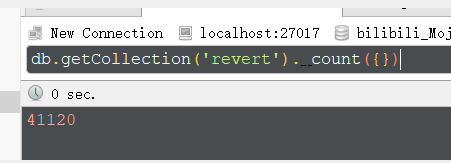
经过核对,基本数据数据没有问题,总弹幕数有41120条。
二、简单做一下图云。
代码清单:
# -*- coding: utf-8 -*-
# @Time : 2020/7/17 11:27
# @Author : hccfm
# @File : 图云制作.py
# @Software: PyCharm
from wordcloud import WordCloud
from matplotlib import pyplot as plt
import matplotlib.font_manager as fm
from PIL import Image
import numpy as np
import jieba_fast as jieba
import pymongo
import re
import pandas as pd
def get_data():
"""
获取评论信息
:return:
"""
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["bilibili_Mojito"]
mycol = mydb["revert"]
# 提取数据
reverts = [x.get('content') for x in mycol.find()]
sex_reverts = [x.get('sex') for x in mycol.find()]
return reverts, sex_reverts
def parse_data(reverts):
"""
清洗信息
:param revers:
:return:
"""
# 清除@别人的数据
revert = [re.sub("回复 @.+ :", "", x) for x in reverts]
# 清除表情、空格、回车等的数据
revert = [re.sub("\[.+\]", "", x).replace("\n", '').replace(' ', '') for x in revert]
# 去掉符号、特殊字符等操作
revert = [re.sub('[^a-zA-Z0-9\u4e00-\u9fa5]', "", x) for x in revert]
seg = [jieba.lcut(x) for x in revert]
r_data_cut = pd.Series(seg)
# 去掉无效词
with open(r"stop_str.txt", encoding="utf-8") as f:
stop_str = f.read()
stop_list = stop_str.split()
words = r_data_cut.apply(lambda x: [i for i in x if i not in stop_list])
return words
def s_parse_data(s_reverts):
"""
清理性别信息
:param s_reverts:
:return:
"""
all_sexs = [x for x in s_reverts]
sex_count = pd.Series(all_sexs).value_counts()
my_font = fm.FontProperties(fname=r'D:\res.TTF')
plt.pie(sex_count, labels=sex_count.keys(), autopct='%.2f%%',
textprops={'fontsize': 12, 'color': 'red', 'fontproperties': my_font})
plt.axis(aspect='equal')
plt.savefig(r'D:\timg2.jpg',dpi=500,bbox_inches = 'tight')
plt.show()
def create_word_cloud(words):
"""
生成词云
:param words:
:return:
"""
# 统计词频
all_words = []
for i in words:
all_words.extend(i)
word_count = pd.Series(all_words).value_counts()
mask = np.array(Image.open(r'D:\timg.jpg'))
wc = WordCloud(font_path=r'D:\res.TTF', background_color='white', max_words=2000, width=720, height=1238, mask=mask)
wordcloud = wc.fit_words(word_count)
wordcloud.to_file(r'D:\timg1.jpg')
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
if __name__ == '__main__':
reverts, sex_reverts = get_data()
words = parse_data(reverts)
create_word_cloud(words)
sexs = s_parse_data(sex_reverts)
结果浏览一下。
男女比例:
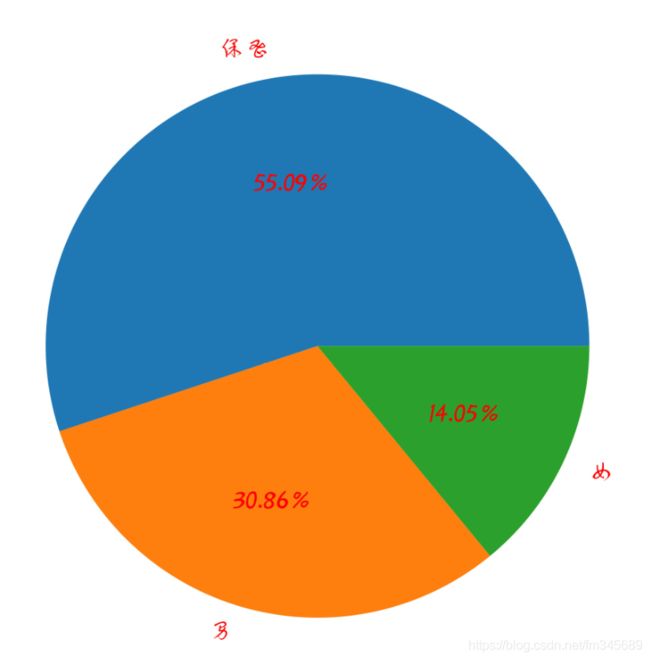
弹幕图云:

当我没说的话
刚开始,我还以为会出现反爬,但是全部弹幕采集下来,也没有看到。
另处,程序代码方面还可以有很多改进,比如,爬虫方面,可以改为多线程,协程,数据清洗过程,也可以加快一点,词云屏蔽词也可以多添加一些。
作为爬虫工程师,我们要合理的去采集数据,能不用多线程之类的快速方法,就别用。体谅别人,也是给自己留后路。。。