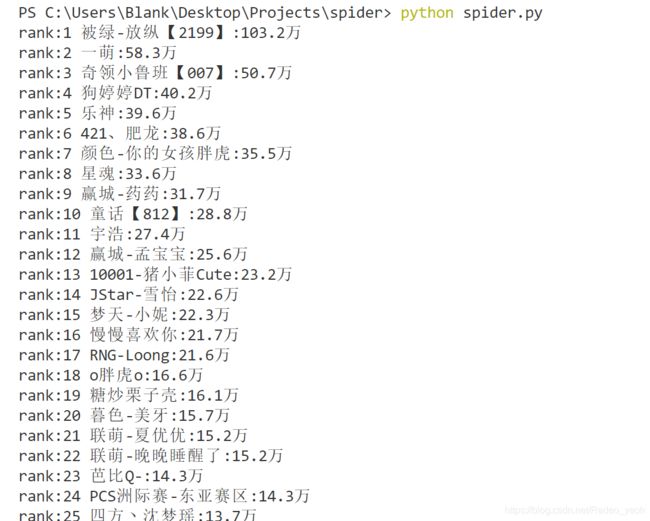
原生爬虫爬取虎牙绝地求生直播热度排行榜
原生爬虫爬取虎牙绝地求生直播热度排行榜
首先需要相应的知识储备:
(1)import 导入方法
(2)面向对象思想
(3)for循环运用
(4)正则表达式
(5)lambda方法的应用
本次原生爬虫爬取信息的相关步骤如下:
一、明确自己想爬取的网页(以虎牙直播绝地求生板块为例)
二、找到想爬取目标的标签

三、模拟HTTP请求:
import re
from urllib import request
class Spider( ):
url = 'https://www.huya.com/g/2793'
四、建立入口方法
def go(self):
htmls=self.__fetch_content() #获取爬取页面htmls
anchors=self.__analysis(htmls) #解析获取页面htmls,寻找到所需姓名和人气
anchors=list(self.__refine(anchors))
anchors=self.__sort(anchors)
self.__show(anchors)
spider=Spider()
spider.go()
五、转化内容格式
def __fetch_content(self): #定义私密实例方法
r=request.urlopen(Spider.url)#类调用类变量
htmls=r.read()
htmls=str(htmls,encoding='utf-8')
return htmls
六、分析所获取的文本
#利用正则表达式匹配需要数据
def __analysis(self,htmls):
root_html=re.findall(Spider.root_pattern,htmls)
anchors=[]
for html in root_html:
七、利用正则表达式进行匹配
#利用正则表达式匹配需要数据
def __analysis(self,htmls):
root_html=re.findall(Spider.root_pattern,htmls)
anchors=[]
for html in root_html:
name=re.findall(Spider.name_pattern,html)#正则表达式返回列表,name列表[('姓名'),('姓名')]
number=re.findall(Spider.number_pattern,html)
anchor={'name':name,'number':number}
anchors.append(anchor)
return anchors
八、用lambda表达式进行提取
#利用正则表达式匹配需要数据
def __analysis(self,htmls):
root_html=re.findall(Spider.root_pattern,htmls)
anchors=[]
for html in root_html:
name=re.findall(Spider.name_pattern,html)#正则表达式返回列表,name列表[('姓名'),('姓名')]
number=re.findall(Spider.number_pattern,html)
anchor={'name':name,'number':number}
anchors.append(anchor)
return anchors
完整代码如下:
import re
from urllib import request
class Spider( ):
url = 'https://www.huya.com/g/2793'
# 正则
root_pattern = '([\s\S]*?)' #结尾并没有包含 人气值,这种情况下需要结尾处再往下找
name_pattern = '([\s\S]*?)' #此时会输出元组,包含两个名字,注意此处的用法
number_pattern='([\s\S]*?)'
#获取要爬取的html
def __fetch_content(self): #定义私密实例方法
r=request.urlopen(Spider.url)#类调用类变量
htmls=r.read()
htmls=str(htmls,encoding='utf-8')
return htmls
#利用正则表达式匹配需要数据
def __analysis(self,htmls):
root_html=re.findall(Spider.root_pattern,htmls)
anchors=[]
for html in root_html:
name=re.findall(Spider.name_pattern,html)#正则表达式返回列表,name列表[('姓名'),('姓名')]
number=re.findall(Spider.number_pattern,html)
anchor={'name':name,'number':number}
anchors.append(anchor)
return anchors
#过滤重复名字以及将anchor和number里内容以字符串输出
def __refine(self,anchors):
l=lambda anchor:{'name':anchor['name'][0][0],'number':anchor['number'][0]}
r=map(l,anchors) #map格式需要转化成list,才能输出
# print(list(r))
return r
# 排序,按照人气值数值大小
def __sort(self,anchors):
anchors=sorted(anchors,key=self.__sort_seed,reverse=True)
return anchors
#将人气值数值取出来,作比较 单个anocher
def __sort_seed(self,anchor):
r=re.findall('[\d.]*',anchor['number'])
number=float(r[0])
if ',' in anchor['number']:
number=number*1000+float(r[2])
if '万' in anchor['number']:
number*=10000
return number
def __show(self,anchors):
for rank in range(0,len(anchors)):
print('rank'+':'+str(rank+1)+' '+anchors[rank]['name']+':'+anchors[rank]['number'])
def go(self):
htmls=self.__fetch_content() #获取爬取页面htmls
anchors=self.__analysis(htmls) #解析获取页面htmls,寻找到所需姓名和人气
anchors=list(self.__refine(anchors))
anchors=self.__sort(anchors)
self.__show(anchors)
spider=Spider()
spider.go()
运行结果: