一.主要思路:
(1).从对应网页中找到"所有的图片标签",
通过url得到对应的html内容。之后通过
BeautifulSoup将其解析成一棵html元素树。
查找所有的"图片标签"
(2).下载图片
通过得到的标签提取出SRC,得到图片地址,下载图片。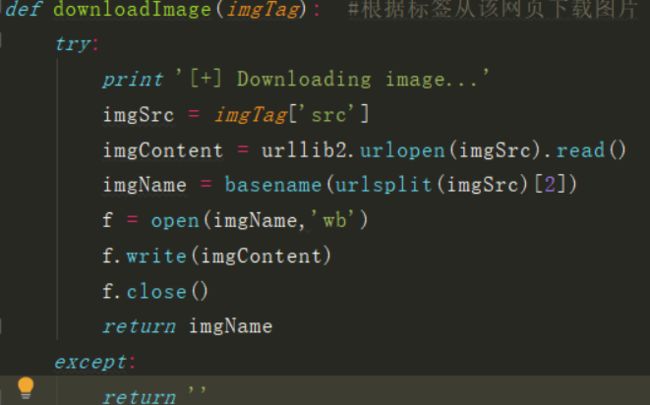
(3).提取元信息exif
将图片通过相应的库实现exif信息的提取,对exif进行遍历,存储到字典变量中。
其中要判断是否存在exif信息(有些不能提取),是否存在GPSInfo信息(有些压缩时
该信息失去,或本来就没有),若是不符合的,删除该图片。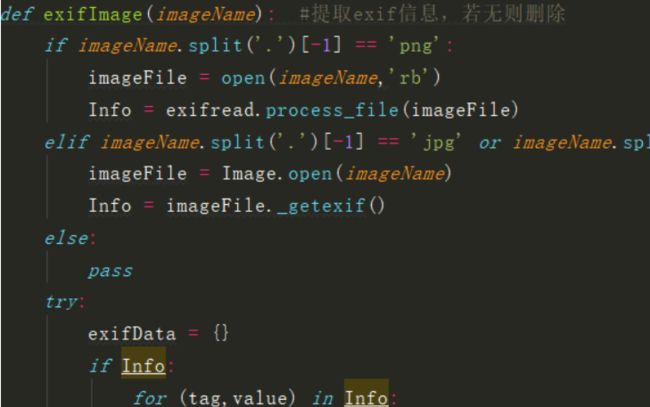
(4).删除图片
利用os的remove功能。只要有对应目录。就可以实现删除。
事实上可以利用os模块实现windows和linux的许多自动化工作。
3.使用模块和方法汇总
urlparse模块
该模块定义了一个标准接口,用于在组件中解析统一资源定位符(URL)字符串(寻址方案,网络位置,路径等),将组件组合回URL字符串,并将“相对URL”转换为 绝对URL给出“基本URL”。
urlsplit函数类似于urlparse
将URL解析为六个组件,返回一个6元组。 这对应于URL的一般结构:scheme:// netloc / path; parameters?query#fragment。 每个元组项都是一个字符串,可能是空的。 组件不会以较小的部分分解(例如,网络位置是单个字符串),并且不会展开%escapes。 如上所示的分隔符不是结果的一部分,除了路径组件中的前导斜杠,如果存在则保留。
os.path.basename(path)
Return the base name of pathname path. where basename for '/foo/bar/' returns 'bar', the basename() function returns an empty string ('').
Beautiful Soup
是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
PIL库官方文档,通常用作图片处理,本程序中用到Image_getexif()方法提取exif,但仅能对jpg和jpeg图片作处理
且不能识别大小写后缀
http://effbot.org/imagingbook/
ExifTags.TAGS(TagName = TAGS.get(tag,tag))
is a dictionary. As such, you can get the value for a given key by using TAGS.get(key). If that key does not exist, you can have it return to you a default value by passing in a second argument TAGS.get(key, val)
Source: http://www.tutorialspoint.com/python/dictionary_get.htm
pip install exifread,本程序中处理png图片的exif信息,利用了
exifread.process_file(imageFile) 方法
通过tags = exifread.process_file(fd) 这个函数读取了图片的exif信息,其下为exif格式
{'Image ImageLength': (0x0101) Short=3024 @ 42,
......
'Image GPSInfo': (0x8825) Long=792 @ 114,
'Thumbnail JPEGInterchangeFormat': (0x0201) Long=928 @ 808,
......
}
4.错误与解决方案
'str' object has no attribute 'read'
事实上是参数本身为一字符串,而参数要求是一个二进制文件,
这是传参是仅仅传了一个文件名字(通过名字打开文件),而非一个文件
'PngImageFile' object has no attribute '_getexif'
该错误是因为_getexif不能提取.png文件
解决方法:
可以使用exifread模块读取,但该模块仅仅可以读取.png文件
依旧有其他BUG存在,尚未解决,但不影响基本使用,不得不说,
原作者写的该部分代码实在是烂,对于现今的网站根本无法使用
5.总结与思考
(1).最终结果依旧没有跑出exif信息,可能是有的加密,或者
部分图片本身未存储exif信息。
(2).有的图片本身格式有gif,JPG,svg等,并没有对此进行严格的过滤。
(3).有的网站本身有反爬机制,不能进行图片的爬取,你如www.qq.com
二.代码
#!/usr/bin/python
# coding: utf-8
import os
import exifread
import urllib2
import optparse
from urlparse import urlsplit
from os.path import basename
from bs4 import BeautifulSoup
from PIL import Image
from PIL.ExifTags import TAGS
def findImages(url): #找到该网页的所有图片标签
print '[+] Finding images of '+str(urlsplit(url)[1])
resp = urllib2.urlopen(url).read()
soup = BeautifulSoup(resp,"lxml")
imgTags = soup.findAll('img')
return imgTags
def downloadImage(imgTag): #根据标签从该网页下载图片
try:
print '[+] Downloading image...'
imgSrc = imgTag['src']
imgContent = urllib2.urlopen(imgSrc).read()
imgName = basename(urlsplit(imgSrc)[2])
f = open(imgName,'wb')
f.write(imgContent)
f.close()
return imgName
except:
return ''
def delFile(imgName): #删除该目录下下载的文件
os.remove('/mnt/hgfs/temp/temp/python/exercise/'+str(imgName))
print "[+] Del File"
def exifImage(imageName): #提取exif信息,若无则删除
if imageName.split('.')[-1] == 'png':
imageFile = open(imageName,'rb')
Info = exifread.process_file(imageFile)
elif imageName.split('.')[-1] == 'jpg' or imageName.split('.')[-1] == 'jpeg':
imageFile = Image.open(imageName)
Info = imageFile._getexif()
else:
pass
try:
exifData = {}
if Info:
for (tag,value) in Info:
TagName = TAGS.get(tag,tag)
exifData[TagName] = value
exifGPS = exifData['GPSInfo']
if exifGPS:
print '[+] GPS: '+str(exifGPS)
else:
print '[-] No GPS information'
delFile(imageName)
else:
print '[-] Can\'t detecated exif'
delFile(imageName)
except Exception, e:
print e
delFile(imageName)
pass
def main():
parser = optparse.OptionParser('-u ')
parser.add_option('-u',dest='url',type='string',help='specify the target url')
(options,args) = parser.parse_args()
url = options.url
if url == None:
print parser.usage
exit(0)
imgTags = findImages(url)
for imgTag in imgTags:
imgFile = downloadImage(imgTag)
exifImage(imgFile)
if __name__ == '__main__':
main()