论文阅读《Spatiotemporal Multiplier Networks for Video Action Recognition》
Spatiotemporal Multiplier Networks for Video Action Recognition
2017CVPR
Christoph Feichtenhofer:http://feichtenhofer.github.io/
Abstract
加入恒等映射核来捕捉长期依赖。
Intro
ST-ResNet:没有提供它的设计选择有系统的理由
重新考虑双流的结合,ResNet较为深入的增加了解这些技术是如何相互作用的
引入这些新的结构,产生了一个新的动作识别方法。
3 main contributions
- 展示了一种可乘的运动外观流,表现非常好
- 讨论在长期输入的情况下,生成ST-ResNet的几种方法(提出了加入时间核),这种方法允许新的时间聚合核注入,甚至进入了网络的skip path。
- 基于如何在residual connections之间融合双流,并且扩展到时间维度,提出了通用的卷积结构,用于动作识别。
Related work
Historically:HOF,MBH,trajectories,HOG3D,Cubiods,SOEs
More recently:
- unsupervised learning,
- makes use of a combination of hand-crafted and learned features
- C3D
- aggregation of temporal information over extended time periods.(dynamic-image/LSTM/RNN/Siamese architecture/)
- 2-stream
Two-stream multiplier networks
3.1. Baseline architecture
双流,卷积网络在appearance上容易过拟合。
在每个流上都用ResNet作为base network architecture。
3.2. Connecting the two streams
加入cross-stream残差连接。提出了几种连接方式:
但是简单的cross-residual连接这两种流的层次导致了较低的分类与(非连接)两流的性能相比基线。我们推测,性能下降是由于这些层的输入分布的巨大变化在注入融合后的一个网络流中来自另一个流的信号。

3.2.1 Additive interaction 相加
Xal and Xml 是appearance stream 和motion stream的第 l 层的输入,对应的,根据链式法则,在反向传播中loss function的梯度 L :

3.2.2 Multiplicative interaction 相乘
将motion信号作为appearance feature的调整,公式为:
⨀ 表示element-wise相乘。反向传播梯度为:
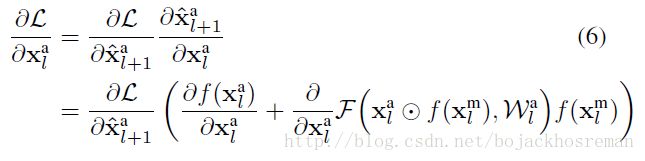
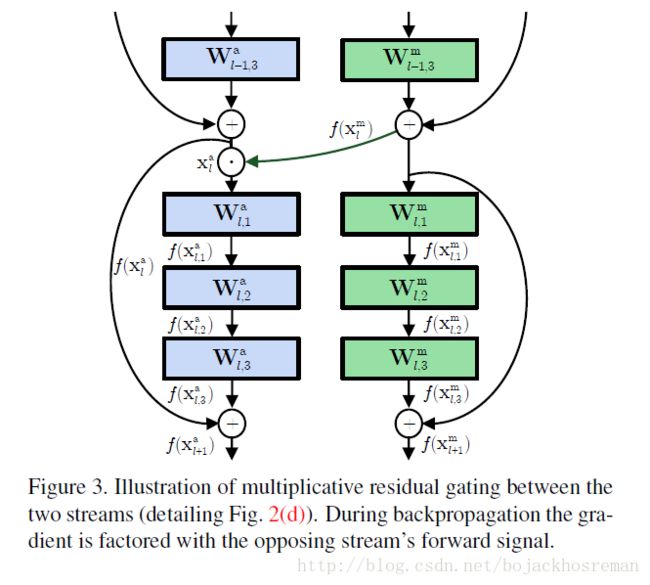
连接方式如图:
motion信号 f(Xml) 传入到appearance流的残差单元,残差单元的梯度:
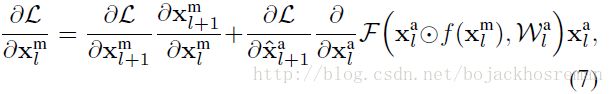
3.2.3 Discussion
Inclusion of the multiplicative interaction increases the order of the network fusion from first to second order。
这里的相乘融合,对比相加,显示出了更strong的信息改变。在之前的例子中,motion信息直接缩放了appearance信息( Xal⨀f(Xml) ),在反向传播的时候,streams因为前向相加作用而均匀分布,如果是相乘的话,则是缩放的关系。后一种交互方式允许在学习过程中,信息流更有效地互动过程,相应的时空特征最终被捕获。
最后,相对于不对称的添加motion信息到appearance信息,我们采用了双向连接。相乘or相加都可以。实验结果表明,这样的连接方式性能比较差,作者人为是因为spatial stream在训练中支配了motion steam。
3.3. Temporal filtering with feature identity
10frames is not enough
采用了一维时间卷积结合特征空间变换来初始化恒等映射。
一维卷积能够非常有效的学习到时间依赖,比LSTM的开销也少得多。特征变换的初始化作为恒等映射,当应用于很深的网络是,网络中任一有意义的改变都会扭曲模型,因此移除了大多数表现力。
形式上,添加时间卷积层用于传递 Cl 个特征通道:
bl 初始化为0, Wl 是时间核,是特征通道之间的恒等映射堆积起来的:
⨂ 代表张量外积,f是长度为T的一维时间核。
因为我们的内核保留了特性标识,所以我们可以将它们放在网络中的任何一层,而不影响它的表示能力(在初始化)。然而在训练的时候,新添加的temporal conv层影响整个模型。
这里我们区分了两个主要变体,直接在shortcut path中直接加入这一层,这样会直接影响网络中的其它层。或者是在残差单元中加入这一层,这样局部的影响周围的block。这两个变体如图所示。
然后全局池化。
4. Architecture details
采用了50-ResNet和152-ResNet.在imagenet上经过了预训练。
blocks的参数:

4.1. Training procedure
先分别训练两个stream,
lr: 10−2 and lower it 2 times after validation error saturates(饱和)。
光流:L=10 frames
dropout=0.8
random crop:256, 224, 192, 168
resize:224x224
batch size:128

4.2. Fully convolutional testing
测试的时候采用fully conv可以提高速度,TitanX 上大约250ms就可以测试一个视频。
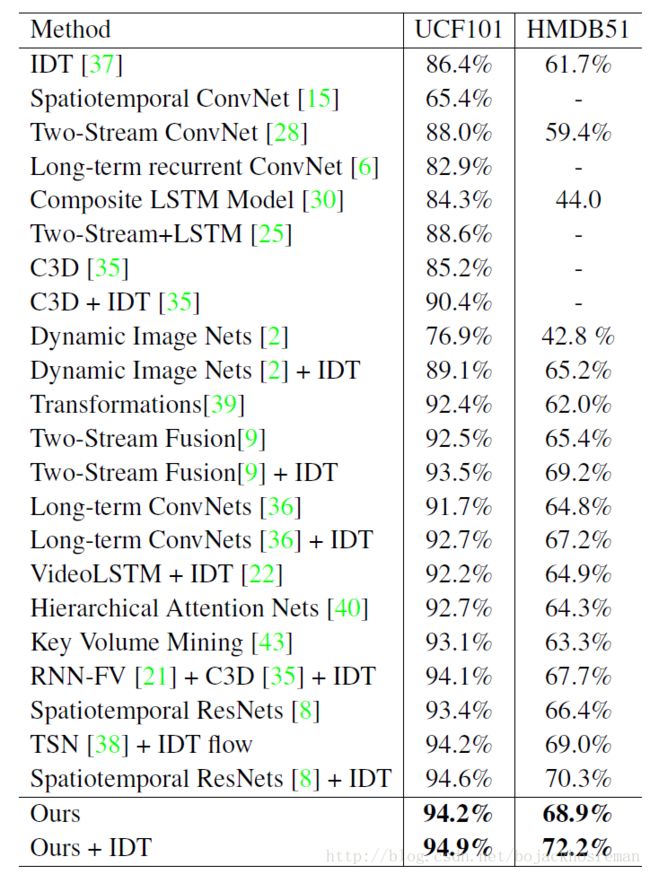
5. Experimental results