学完前面的教程,相信你已经能爬取大部分的网站信息了,但是当你爬的网站多了,你应该会发现一个新问题,有的网站需要登录账户才能看到更多的信息对吧?那么这种网站怎么爬取呢?这些登录数据就是今天要说的——cookie
cookie
其实在前面在解析requests模块时也提到过的。
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密),比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。这也是放爬虫的一种手段,但是怎么可能难道我们呢?对吧?我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了
既然已经知道cookie是登录账户信息,我们怎么利用它进行爬取网站呢?这里就要用到一个内置模块——cookielib
cookielib
1.简介:
cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用来访问Internet资源。
Cookielib模块非常强大,可以利用它的CookieJar类的对象来捕获cookie并在后续连接请求时重新发送,比如可以实现模拟登录功能
该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
其关系为:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar
2.方法属性:

注意:这里使用的是python2,cookielib是内置模块也是针对python2而言,在python3中,与cookielib模块功能相同的是http.cookiejar模块
3.常用方法/属性就略过,以后遇到再说,本篇博文直接以举例来解析最常用的几个方法
1)获取Cookie
import cookielib
import urllib2
cookie = cookielib.CookieJar() #创建CookieJar对象实例来保存cookie
handler=urllib2.HTTPCookieProcessor(cookie) #利用urllib2库的HTTPCookieProcessor对象创建cookie处理器
opener = urllib2.build_opener(handler) #通过cookie处理器创建opener
response = opener.open('http://www.baidu.com') #此处的open方法类同urllib2的urlopen方法,也可以传入request
for item in cookie:
print 'Name = '+item.name
print 'Value = '+item.value
结果:
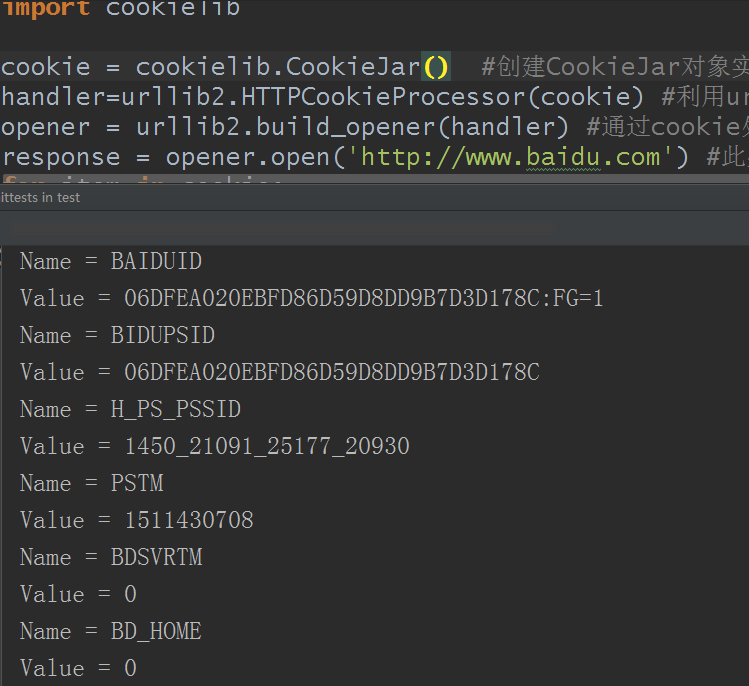
上面的Name和Value就是cookie信息
注意:cookie并不是等同于账户密码信息,而是包含账户密码信息和其他信息
2)保存Cookie到文件
有时候根据开发需要,我们可能会想把cookie信息保存下来以便以后直接使用,相信大家平时上网访问需要登录账户的时候都是勾选了记住帐号密码的吧?
当勾选了这个选项,浏览器就会把账户和密码作为cookie信息保存在浏览器的本地数据内,以后再访问,直接自动登录
利用python其实也可以实现这个功能
import cookielib
import urllib2
filename = 'cookie.txt' #设置保存cookie的文件,默认保存在当前目录
cookie = cookielib.MozillaCookieJar(filename) #创建一个MozillaCookieJar对象实例来保存cookie,MozillaCookieJar对象会自动完成创建和写入操作
handler = urllib2.HTTPCookieProcessor(cookie) #利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
opener = urllib2.build_opener(handler) #通过cookie处理器创建opener
response = opener.open("http://www.baidu.com") #创建一个请求
cookie.save(ignore_discard=True, ignore_expires=True) #保存cookie到文件
这里的save方法要说一下,它有两个参数:
- ignore_discard:即使cookies将被丢弃也将它保存下来
- ignore_expires:如果在该文件中cookies已经存在,则覆盖原文件写入(类似文件操作模式里的'W')
打开cookie.txt文件:
# Netscape HTTP Cookie File
# http://curl.haxx.se/rfc/cookie_spec.html
# This is a generated file! Do not edit.
.baidu.com TRUE / FALSE 3658914970 BAIDUID F6DCF3EE6D6624B9CDE48E6CDF1186F0:FG=1
.baidu.com TRUE / FALSE 3658914970 BIDUPSID F6DCF3EE6D6624B9CDE48E6CDF1186F0
.baidu.com TRUE / FALSE H_PS_PSSID 1441_21109_18559_25178_20927
.baidu.com TRUE / FALSE 3658914970 PSTM 1511431348
www.baidu.com FALSE / FALSE BDSVRTM 0
www.baidu.com FALSE / FALSE BD_HOME 0
以上就是cookie信息
3)从文件中获取Cookie并访问
既然有保存到文件,那么自然有逆操作,利用已有的cookie文件的来传入数据
import cookielib
import urllib2
cookie = cookielib.MozillaCookieJar() #创建MozillaCookieJar实例对象
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True) #从当前目录下的cookie.txt文件中读取cookie内容到变量
url = "http://www.baidu.com"
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) #利用urllib2的build_opener方法创建一个opener
response = opener.open(url)
print response.read()
结果:
百度一下,你就知道

结果不出意外的就是百度首页的源代码
4)利用cookie模拟登录网站
重点来了,前面的都只是说下用法,我这里测试的网站为https://www.w3cschool.cn
#-*- coding:utf-8 -*-
import urllib,urllib2
import cookielib #python3里是http.cookiejar
cookiefile='cookie.txt' #存入本地文件
postdata=urllib.urlencode({
'username':'xxxxxx', #你的账户名
'password':'xxxxxx' #你的密码
})
# head={
# 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'
# } #需不需要修改User-Agent头部信息随你
url='https://www.w3cschool.cn/checklogin' #网站登录链接
cookie = cookielib.MozillaCookieJar(cookiefile) #打开文件
handler=urllib2.HTTPCookieProcessor(cookie) #利用urllib2创建cookie对象
opener = urllib2.build_opener(handler) #创建opener对象
response = opener.open(url,postdata) #打开网站链接并传入cookie
cookie.save(ignore_discard=True,ignore_expires=True) #保存cookie
url2='https://www.w3cschool.cn/my' #利用cookie请求访问另一个网址,此网址个人主页,以此来验证登录是否成功
result=opener.open(url2) #打开网站链接
print result.read() #读取网站源代码
结果:
个人中心- W3Cschool在线教程
加载中...

这确实是w3cschool的个人主页源代码。如果cookie没有成功传入的话,结果会和下面一样:

懂了吧?cookie没有传入成功就会是未登录状态的源代码,就是请输入账号和密码等等等的
所以,现在知道cookie的强大了吧?