LIBSVM数据格式及其使用
关于支持向量机(SVM)的理论部分推荐一个博客:支持向量机通俗导论(理解SVM的三层境界)
http://blog.csdn.net/v_july_v/article/details/7624837
July的博客分三层讲述支持向量机,对于我们需要了解道不同层次的学习者来说,一目了然。
我也是通过此博客进行学习的。
假若你已经基本上掌握了SVM的理论部分,那么如何对数据进行分析呢?
我们一般对数据使用SVM进行分类的时候,使用的是林智仁的SVM库:LIBSVM
http://www.csie.ntu.edu.tw/~cjlin/libsvm/
在这里可以下载到最新的库,而且能够下载到训练所用的数据,但是数据连接点开之后只能复制,就像这个数据集:
http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/breast-cancer
不能下载,那我们复制完之后存储成什么格式呢?
我们可以从LIBSVM里面随便下载一个数据,比如libsvm里面自带的heart_scale,然后用notepad打开,粘贴保存即可
对于自己的数据怎么办呢?
首先,我们知道LIBSVM里面的数据格式如下:
Label 1:value 2:value ….
其次,我们使用FormatDataLibsvm.xls生成这种格式,具体如下:
下载FormatDataLibsvm.xls(百度搜索)
运行FormatDataLibsvm.xls(注意这时会有一个关于“宏已禁宏”的安全警示,点击“选项”,选择“启用此内容”,确定即可);1,先运行FormatDataLibsvm.xls然后将数据粘贴到sheet1的topleft单元。
2、 打开data.xls,(注:网上很多的介绍都是直接将数据粘贴到sheet1的topleft单元),要特别注意的是这时候的数据排列顺序应该是:
条件属性a 条件属性b ... 决策属性
7 5 ... 2
4 2 ... 1
3、"工具"-->"宏"-->执行下面有一个选项(FormatDatatoLibsvm)-->执行,要选中这个然后点击“运行” ,这时候数据讲变成:
决策属性 条件属性a 条件属性b ...
2 1:7 2:5 ...
1 1:4 2:2 ...
等数据转换完成后,将该文件保存为.txt文件。这时数据转换的问题就解决了。
最后,从LIBSVM里面随便下载一个数据,比如libsvm里面自带的heart_scale,然后用notepad打开,数据粘贴进保存即可
使用libsvm 3.18 MATLAB 编程对UCI的数据breast进行分类:
数据连接:http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/breast-cancer
程序如下:
%数据本身分组加预测
[breast_label, breast_inst] =libsvmread('../breast_scale');
data= [breast_inst(:,1), breast_inst(:,2),breast_inst(:,3), breast_inst(:,4)];
%data = breast_inst;
groups = ismember(breast_label,2); %将标签转换成1和0
[train, test] =crossvalind('holdOut',groups,0.7); %利用交叉耦合函数进行分组,70%的数据用来训练,剩下的数据进行预测
train_breast = data(train,:); %获取train标签对应的训练数据
train_breast_labels = groups(train,:);
train_breast_labels = double(train_breast_labels );
test_breast = data(test,:); %获取train标签对应的训练数据
test_breast_labels = groups(test,:);
test_breast_labels =double(test_breast_labels);
% 数据归一化
train_breast = normalization(train_breast',2);
test_breast = normalization(test_breast',2);
train_breast = train_breast';
test_breast = test_breast';
%训练和预测
model = svmtrain(train_breast_labels,train_breast, '-s 0 -t 0 -c 1 -g 0.07');
[predict_label, accuracy, dec_values] =svmpredict(test_breast_labels, test_breast, model);
[mm,mn] = size(model.SVs);
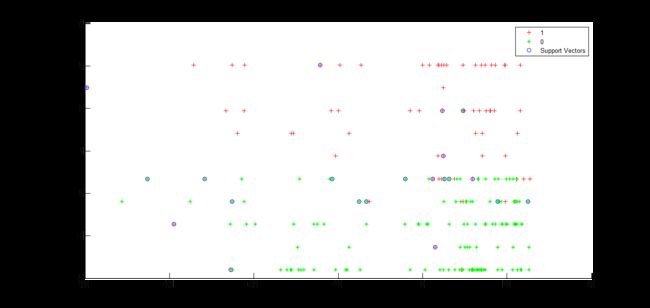
figure;
hold on;
[m,n] = size(train_breast);
for run = 1:m
if train_breast_labels(run) == 0
h1 = plot( train_breast(run,1),train_breast(run,2),'r+' );
else
h2 = plot( train_breast(run,1),train_breast(run,2),'g*' );
end
for i = 1:mm
if model.SVs(i,1)==train_breast(run,1) &&model.SVs(i,2)==train_breast(run,2)
h3 = plot( train_breast(run,1),train_breast(run,2),'o' );
end
end
end
legend([h1,h2,h3],'1','0','SupportVectors');
hold off;
运行结果:
optimization finished, #iter = 67190
nu = 0.093757
obj = -18.486007, rho = -0.113756
nSV = 22, nBSV = 16
Total nSV = 22
Accuracy = 95.1782% (454/477)(classification)
总之,数据前期处理很重要,归一化很重要,明白参数,逐一试试,才能达到较好的分类效果。