Titanic数据分析
利用Pandas对泰坦尼克数据进行分析
1.导入数据
导入数据,对数据做个简单的统计
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据
titanic = pd.read_csv(r"自己电脑上这个文件的路径\train.csv")
# 快速预览
print(titanic.head())
print(titanic.info())
# 把所有数值类型的数据做一个简单的统计
print(titanic.describe()) #describe函数比info函数功能更强大,统计所有非空数据的条数,mean平均值,std标准差,min和max最小最大值
# 统计null值个数
print(titanic.isnull().sum())
2. 处理空值
# 可以填充整个dataframe里面的空值
# titanic.fillna(0) #将空值都填充为0
# 单独选择一列进行空值填充
# titanic.Age.fillna(0)
# 年龄用0填充不合适,可以用中位数进行填充
# 年龄的中位数
print(titanic.Age.median()) #输出结果为28
# 按年龄中位数去填充,此时返回一个新的series
print(titanic.Age.fillna(titanic.Age.median()))
# 直接填充,并不返回新的series
titanic.Age.fillna(titanic.Age.median(), inplace = True)
# 再次查看Age的空值
print(titanic.isnull().sum()) #此时发现,age的空值为0了
3. 尝试从性别进行分析
# 做简单的汇总统计,value_counts这个函数会经常用到
print(titanic.Sex.value_counts()) #男性577,女性314
# 生还者中,男女的人数
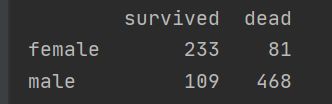
survived = titanic[titanic.Survived==1].Sex.value_counts()
print(survived) #男性109,女性233
# 未生还者中,男女的人数
dead = titanic[titanic.Survived==0].Sex.value_counts()
print(dead) #男性468,女性81

3.1. 尝试绘图
先看一下画出的柱状图是什么样的
# 尝试用pandas自带绘图
df = pd.DataFrame([survived, dead],index = ['survived', 'dead']) # 由于汇总统计输出的数据类型是series,有两列,所以可以用dataframe构建
df.plot.bar()
plt.show()

绘图成功,但是不是我们想要的效果
我们想把女性的死亡和生还人数画一起,把男性的死亡和生还人数画一起,这时候我们可以把dataframe转置一下
df = df.T
print(df)
转置成功,这时候再画一下

仍然不是我们想要的结果
尝试把直方图堆积在一起,直观一点
df.plot(kind = 'bar', stacked = True)
plt.show()
效果如图:
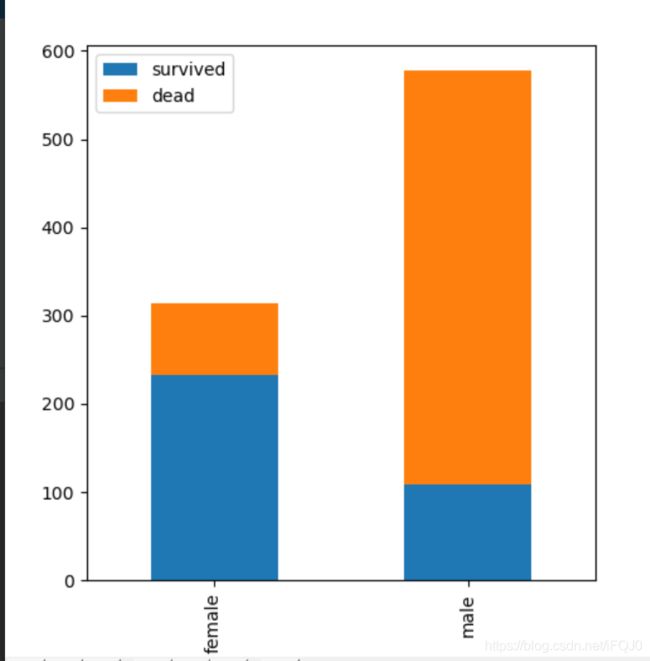
由于男女人数不一样,没法直观看到男女生还人数的百分比
df['p_survived'] = df.survived / (df.survived + df.dead)
df['p_dead'] = df.dead / (df.survived + df.dead)
print(df)
 此时生还和死亡的百分比就出来了,女性的死亡和生还的百分比相加是100%。注意分母要用括号括起来!
此时生还和死亡的百分比就出来了,女性的死亡和生还的百分比相加是100%。注意分母要用括号括起来!
下面绘制男女中生还者的比例情况的图
# 男女中生还者的比例情况
df['p_survived'] = df.survived / (df.survived + df.dead)
df['p_dead'] = df.dead / (df.survived + df.dead)
df[['p_survived','p_dead']].plot(kind='bar', stacked = True)
plt.show()
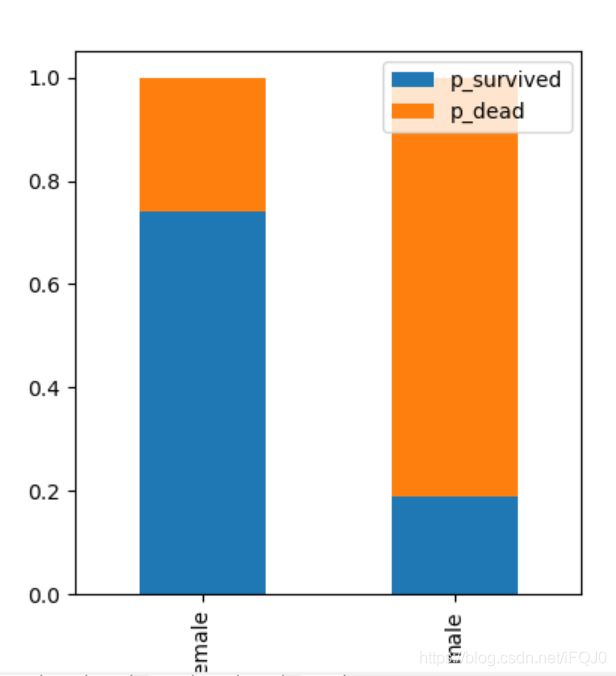
通过上图可以看出,性别特征对是否生还的影响还是挺大的
4. 从年龄进行分析
# 简单统计
print(titanic.Age.value_counts())

与性别类似,对年龄进行Dataframe,打印看一下
# 因为年龄只有一列数据,不适合用柱状图,这里尝试用直方图画一下
# 生还者的年龄
survived = titanic[titanic.Survived==1].Age
# 未生还者的年龄
dead = titanic[titanic.Survived==0].Age
df = pd.DataFrame([survived,dead], index=['survived','dead'])
df = df.T
print(df)
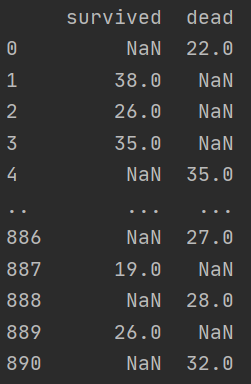
绘制直方图
df.plot.hist()
plt.show()
 可以看到,由于死亡人数比生还的多,把生还盖过了。我们还是用stacked
可以看到,由于死亡人数比生还的多,把生还盖过了。我们还是用stacked
df.plot.hist(stacked = True)
plt.show()
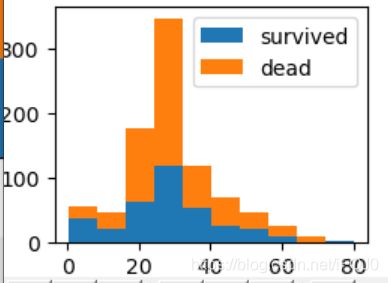 可以看到,图片自动将柱子设为了10根,我们可以放多一点
可以看到,图片自动将柱子设为了10根,我们可以放多一点
df.plot.hist(stacked = True, bins=30) #将柱子根数设为30根
plt.show()
中间很高的柱子,因为我们把空值都替换为了中位数
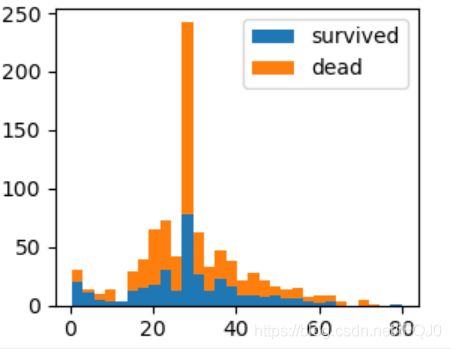
此时可以看出死亡人数比生还者多,但是具体多多少还是不容易看出
我们可以借用密度图,更直观一点
# 密度图
df.plot.kde()
plt.show()
这里记得安装scipy安装包,否则会报错。安装方法跟我前几篇博客一样的。
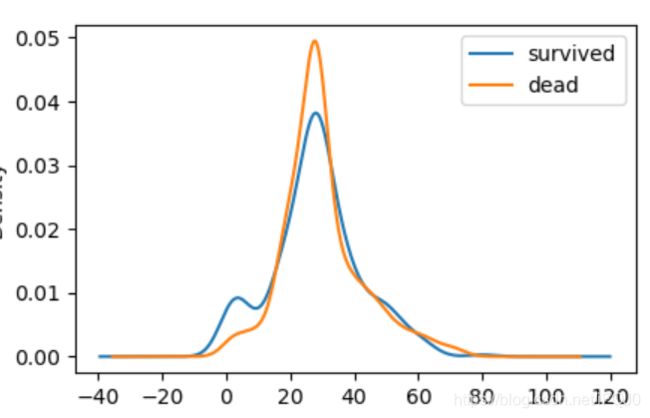 在0~16岁的区间内,生还者要多些。到20岁,死亡人数明显上升。到了30岁以后,基本死亡和生还人数趋于一致了。
在0~16岁的区间内,生还者要多些。到20岁,死亡人数明显上升。到了30岁以后,基本死亡和生还人数趋于一致了。
用describe函数看一下Age的分布信息
# 可以查看年龄的分布,来决定我们图片横轴的取值范围
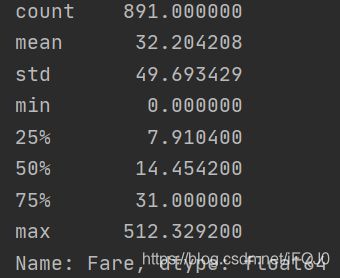
print(titanic.Age.describe())
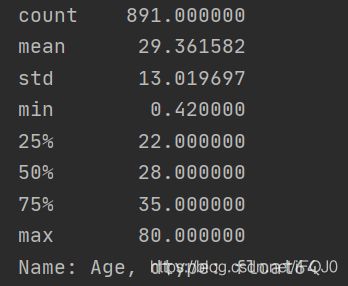
发现年龄在0.42-80岁之间,但是我们绘制出来的密度图区间在-40~120
于是我们对横轴的取值范围进行限制
df.plot.kde(xlim=(0,80))
plt.show()
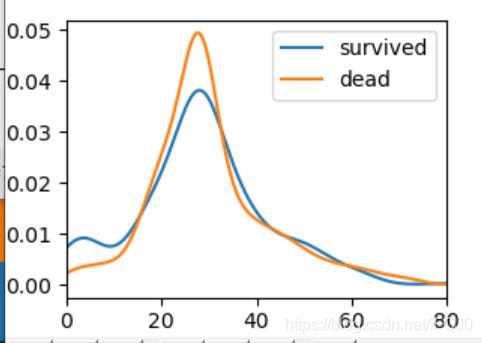 从上图可知,年龄对生还的影响还是挺大的。10岁之前,生还的几率比较大,20-30岁生还的几率就变小了,死亡率增高了
从上图可知,年龄对生还的影响还是挺大的。10岁之前,生还的几率比较大,20-30岁生还的几率就变小了,死亡率增高了
以上都是把年龄作为线性数据来分析,我们还可以按年龄简单地分为两类,成年人和未成年人,来进行聚类分析。
以后如果碰到数据比较适合聚类分析的话,可以想想怎么做。
1.首先我们把成年人和未成年人的生还与死亡人数的柱状图画出来
age = 16
young = titanic[titanic.Age<=age]['Survived'].value_counts()
old = titanic[titanic.Age>age]['Survived'].value_counts()
df = pd.DataFrame([young,old],index=['young','old'])
df.columns = ['dead','survived']
df.plot.bar(stacked = True)
plt.show()
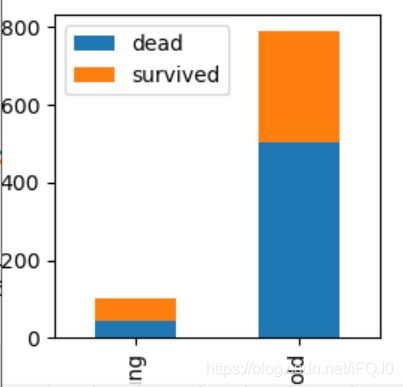
2.与性别一样,我们把成年人和未成年生还者的比例情况画出来
# 成年人和未成年生还者的比例情况
df['p_survived'] = df.survived / (df.survived + df.dead)
df['p_dead'] = df.dead / (df.survived + df.dead)
df[['p_survived','p_dead']].plot(kind='bar', stacked = True)
plt.show()
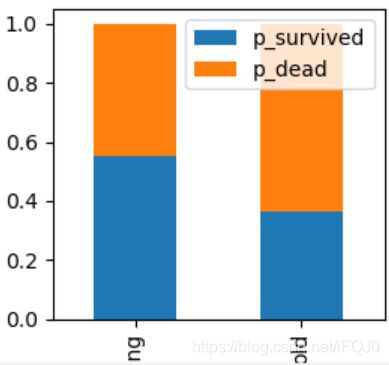
5.分析票价
我们查看下图票价数据特征可知,票价特征跟年龄相似,都是一列数字。所以处理上会跟年龄差不多,我们这里直接画密度图就好了。
print(titanic.Fare)
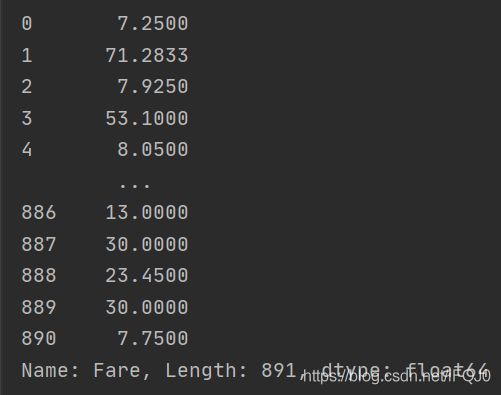 画密度图要设定xlim范围的话,先查看票价的范围
画密度图要设定xlim范围的话,先查看票价的范围
survived = titanic[titanic.Survived==1].Fare
dead = titanic[titanic.Survived==0].Fare
df = pd.DataFrame([survived,dead], index=['survived','dead'])
df = df.T
df.plot.kde(xlim=[0,513])
# 设定xlim范围,先查看票价的范围
# print(titanic.Fare.describe())
plt.show()
可以看到,票价的范围是0-512.3,所以我们设置取值范围为0-513就可以。
票价的密度图如下:
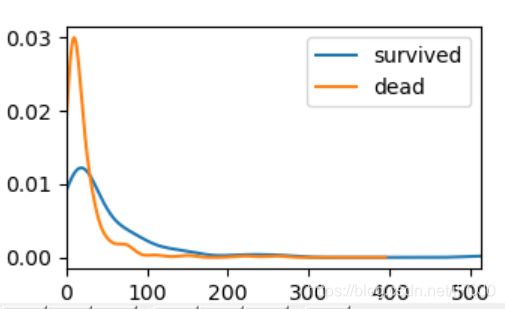 由上图,可以看出票价对生还的影响。从大概50的地方,低票价的人,生还率比较低。
由上图,可以看出票价对生还的影响。从大概50的地方,低票价的人,生还率比较低。
6.组合特征
比如同时查看年龄的票价对生还率的影响
我们将年龄作横轴,票价作纵轴,绘制散点图
import matplotlib.pyplot as plt
ax = plt.subplot()
# 死亡
age = titanic[titanic.Survived == 0].Age
fare = titanic[titanic.Survived == 0].Fare
plt.scatter(age, fare, s=10, marker='o',alpha=0.3,linewidths=1,edgecolors='gray') #alpha参数表示透明度
# 生还者
age = titanic[titanic.Survived == 1].Age
fare = titanic[titanic.Survived == 1].Fare
plt.scatter(age, fare, s=10, marker='o',alpha=0.3,linewidths=1,edgecolors='red')
ax.set_xlim(min(age),max(age))
ax.set_ylim(min(fare),max(fare))
ax.set_xlabel('age') #横轴显示标签age, scatter函数没有label参数,所以我们另外设置一下
ax.set_ylabel('fare') #纵轴显示标签fare
plt.show()
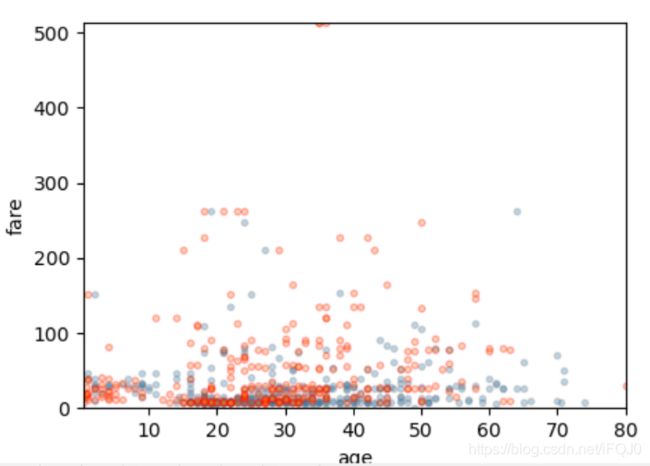
从上图我们可以分析,
蓝色点表示生还者,大部分年龄都是50岁以下
图形大致呈现三角形,说明票价高的还是占少部分
红色点表示未生还者,大部分票价都在100以下
在100以上红色点比蓝色点多
7.隐含特征
7.1 Name
Name里面有一些Mr.、Miss. 这样的称呼,都是带点的,我们可以把这些名字提取出来
同样,用describe函数查看以下Name数据的特征
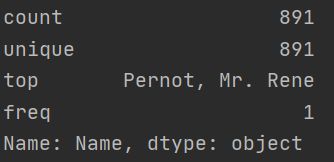
把称呼提取出来,放到title列下
titanic['title'] = titanic.Name.apply(lambda name:name.split(',')[1].split('.')[0].strip())
s = 'Pernot, Mr. Rene'
print(s.split(',')[-1].split('.')[0].strip())
代码的意思是:首先从,把两边分开,获取到’Pernot’和‘ Mr. Rene’,取最后一位,‘Mr. Rene’,将它从.两边分开,得到‘ Mr’和‘ Rene’,取第一位,得到‘ Mr’,最后用strip函数将两边空格删除,返回Mr
此时,title已经插入进表格的最后一列,都是称谓
# 简单地统计称谓
print(titanic.title.value_counts())
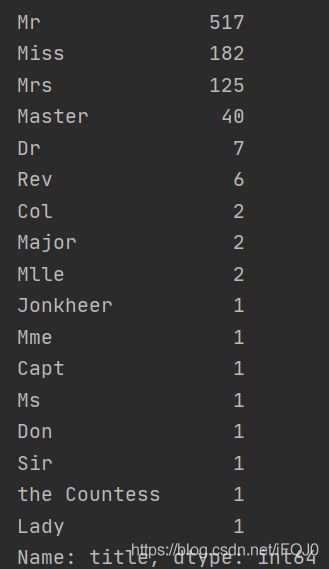 提取这个有啥用呢?
提取这个有啥用呢?
比如有一个人被称为Mr,而年龄是不知道的,这个时候可以用所有Mr的年龄平均值来替代,而不是我们之前简单地用中位数填充。
7.2 GDP
当需要评估一个地区的经济状况, 手头又没有数据,应该学会从一些隐含特征中提取一些有效特征。比如用夜光图,简单用灯光图的亮度来模拟GDP
7.3 家族分类
按家族人数的数量分成一个小的类别
SibSp 兄弟姐妹的数量
Parch 子女的数量
titanic['family_size'] = titanic.SibSp + titanic.Parch +1 #加上自己
print(titanic)
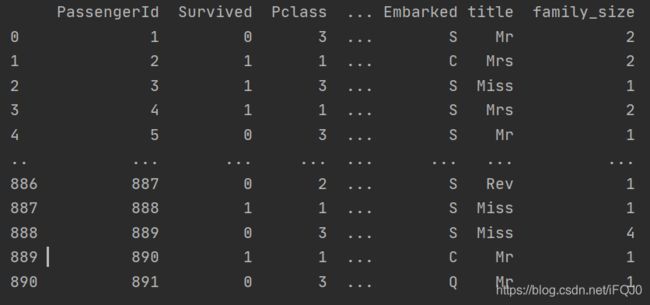 统计一下family_size
统计一下family_size
print(titanic.family_size.value_counts())
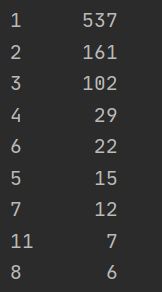
可以看到大多数人还是属于1
还可以对family_size进行聚类,首先分成Singleton,SmallFamily,LargeFamily三类
def func(family_size):
if family_size ==1:
return 'Singleton'
if family_size <=4 and family_size >=2:
return 'SmallFamily'
if family_size >4:
return 'LargeFamily'
titanic['family_type'] = titanic.family_size.apply(func) # 根据现有的列生成新的列用apply函数
print(titanic)
打印看一下,生成了新的列family_type
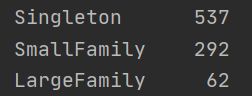
 统计一下family_type
统计一下family_type
print(titanic.family_type.value_counts())