“手写识别”实例介绍
图像识别:
图像识别(Image Recognition)是指利用计算机对图像进行处理、分析 和理解,以识别各种不同模式的目标和对像的技术。
图像识别的发展经历了三个阶段:文字识别、数字图像处理与识别、物体 识别。机器学习领域一般将此类识别问题转化为分类问题。
手写识别:
手写识别是常见的图像识别任务。计算机通过手写体图片来识别出图片 中的字,与印刷字体不同的是,不同人的手写体风格迥异,大小不一, 造成了计算机对手写识别任务的一些困难。
数字手写体识别由于其有限的类别 (0~9共10个数字)成为了相对简单 的手写识别任务。DBRHD 和 MNIST 是常用的两个数字手写识别数据集。

MNIST数据集:
MNIST的下载链接:http://yann.lecun.com/exdb/mnist/。
MNIST是一个包含数字0~9的手写体图片数据集,图片已归一化为以手写数 字为中心的28*28规格的图片。MNIST由训练集与测试集两个部分组成,各部分 规模如下:
训练集:60,000个手写体图片及对应标签 测试集:10,000个手写体图片及对应标签
MNIST数据集的手写数字样例:
MNIST数据集中的每一个图片由28*28个像素点组成
每个像素点的值区间为0~255,
0表示白色,255表示黑色。

DBRHD数据集:
DBRHD(Pen-Based Recognition of Handwritten Digits Data Set)是UCI的机器 学习中心提供的数字手写体数据库: https://archive.ics.uci.edu/ml/datasets/Pen-
Based+Recognition+of+Handwritten+Digits。
DBRHD数据集包含大量的数字0~9的手写体图片,这些图片来源于44位不同的人的手 写数字,图片已归一化为以手写数字为中心的32*32规格的图片。DBRHD的训练集与测试 集组成如下:
训练集 :7,494个手写体图片及对应标签,来源于40位手写者 测试集:3,498个手写体图片及对应标签,来源于14位手写者
DBRHD数据集特点:
去掉了图片颜色等复杂因素,将手写体数字图片转化为训 练数据为大小32*32的文本, 矩阵空白区域使用0代表,字迹区域使用1表示。

已有许多模型在 MNIST 或 DBRHD 数据集上进行了实验,有些模型对数据集进行了偏斜 矫正,甚至在数据集上进行了人为的扭曲、偏移、缩放及失真等操作以获取更加多样性的 样本,使得模型更具有泛化性。
常用于数字手写体的分类器
1) 线性分类器
3) Boosted Stumps
5) SVM
2) K最近邻分类器 4) 非线性分类器 6) 多层感知器
7) 卷积神经网络
后续任务:利用全连接的神经网络实现手写识别的任务
神经网络实现“手写识别”
任务介绍
手写数字识别是一个多分类问题,共有 10 个分类,每个手写数字图像的 类别标签是 0~9 中的其中一个数。例如下面这三张图片的标签分别是 0,1, 2。

任务:利用 sklearn 来训练一个简单的全连接神经网络,即多层感知机 (Multilayer perceptron,MLP)用于识别数据集 DBRHD 的手写数字。
MLP的输入
DBRHD数据集的每个图片是一个由0 或1组成的32*32的文本矩阵;
多层感知机的输入为图片矩阵展开的 1*1024个神经元。

MLP的输出
MLP输出:“one-hot vectors”
一个 one-hot 向量除了某一位的数字是1以外其余各维度数字都是0。
图片标签将表示成一个只有在第n维度(从0开始)数字为1的10维向量。
比如,标签0将表示成[1,0,0,0,0,0,0,0,0,0,0]。即,MLP输出层具有10 个神经元。
MLP结构
MLP的输入与输出层,中间隐藏层 的层数和神经元的个数设置都将 影响该MLP模型的准确率。
在本实例中,我们只设置一层隐 藏层,在后续实验中比较该隐藏 层神经元个数为50、100、200时 的MLP效果。
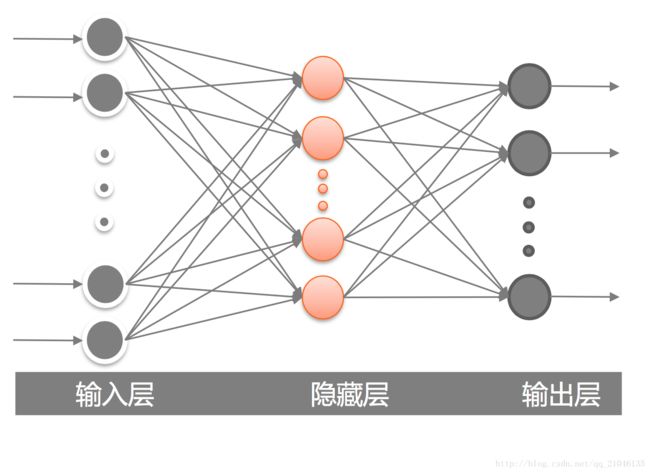
MLP手写识别实例构建
本实例的构建步骤如下:
步骤1:建立工程并导入sklearn包 步骤2:加载训练数据
步骤3:训练神经网络
步骤4:测试集评价
代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sun May 28 20:12:45 2017
@author: xiaolian
"""
import numpy as np #
from os import listdir #
from sklearn.neural_network import MLPClassifier
def img2vector(filename):
retMat = np.zeros([1024], int)
fr = open(filename)
lines = fr.readlines()
for i in range(32):
for j in range(32):
retMat[i*32 + j] = lines[i][j]
return retMat
def readDataSet(path):
fileList = listdir(path)
numFiles = len(fileList)
dataSet = np.zeros([numFiles, 1024], int)
labels = np.zeros([numFiles, 10])
for i in range(numFiles):
filePath = fileList[i]
digit = int(filePath.split('_')[0])
labels[i][digit] = 1.0
dataSet[i] = img2vector(path + '/' + filePath)
return dataSet, labels
train_dataSet, train_labels = readDataSet('trainingDigits')
clf = MLPClassifier(hidden_layer_sizes = (1000,), activation = 'logistic', solver = 'adam', learning_rate_init = 0.0001, max_iter = 2000)
clf.fit(train_dataSet, train_labels)
dataSet, labels = readDataSet('testDigits')
res = clf.predict(dataSet)
print(res)
error_num = 0
num = len(dataSet)
for i in range(num):
if np.sum(res[i] == labels[i]) < 10:
error_num += 1
print( 'total num : ', num, 'error num:', error_num, 'erroe_rate :', error_num / float(num) )KNN实现“手写识别”
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Mon May 29 06:53:31 2017
@author: xiaolian
"""
import numpy as np
from os import listdir
from sklearn import neighbors
def img2vector(filename):
retMat = np.zeros([1024], int)
fr = open(filename)
lines = fr.readlines()
for i in range(32):
for j in range(32):
retMat[i * 32 + j] = lines[i][j]
return retMat
def readDataSet(path):
filelist = listdir(path)
numfiles = len(filelist)
dataSet = np.zeros([numfiles, 1024],int)
labels = np.zeros([numfiles])
for i in range(numfiles):
filepath = filelist[i]
digit = int(filepath.split('_')[0])
labels[i] = digit
dataSet[i] = img2vector(path + '/' + filepath)
return dataSet, labels
train_dataset, train_labels = readDataSet('trainingDigits')
knn = neighbors.KNeighborsClassifier(algorithm = 'kd_tree', n_neighbors = 3)
knn.fit(train_dataset, train_labels)
dataset, labels = readDataSet('testDigits')
res = knn.predict(dataSet)
error_num = np.sum(res != labels)
num = len(dataset)
print('total num:', num, 'wrong num:', error_num, 'wrongrate :',error_num / float(num))