MAHOUT入门(一)——环境变量的配置
主要介绍一下,mahout环境变量的配置,推荐算法的api,以及通过命令行来使用mahout。
一、mahout简介
mahout的logo和它的名字一样,是一个象夫,这里的大象代表的是hadoop。mahout可以基于hadoop快速创建高性能的机器学习应用。
目前(2015/11/6,版本0.11.1)的版本的mahout主要包含三个部分:
- 构建可扩展算法的环境
- 成熟的MapReduce算
- 新的Scala+spark算法
| 算法类 | 算法名 | 中文名 |
|---|---|---|
| 分类算法 | Logistic Regression | 逻辑回归 |
| - | Bayesian | 贝叶斯 |
| - | SVM | 支持向量机 |
| - | Perceptron | 感知器算法 |
| - | Neural Network | 神经网络 |
| - | Random Forests | 随机森林 |
| - | Restricted Boltzmann | Machines |
| 聚类算法 | Canopy Clustering | Canopy聚类 |
| - | K-means Clustering | K均值算法 |
| - | Fuzzy K-means | 模糊K均值 |
| - | Expectation Maximization | EM聚类(期望最大化聚类) |
| - | Mean Shift Clustering | 均值漂移聚类 |
| - | Hierarchical Clustering | 层次聚类 |
| - | Dirichlet Process Clustering | 狄里克雷过程聚类 |
| - | Latent Dirichlet Allocation | LDA聚类 |
| - | Spectral Clustering | 谱聚类 |
| 关联规则挖掘 | Parallel FP Growth Algorithm | 并行FP Growth算法 |
| 回归 | Locally Weighted Linear Regression | 局部加权线性回归 |
| 降维/维约简 | Singular Value Decomposition | 奇异值分解 |
| - | Principal Components Analysis | 主成分分析 |
| - | Independent Component Analysis | 独立成分分析 |
| - | Gaussian Discriminative Analysis | 高斯判别分析 |
| 进化算法 | 并行化了Watchmaker框架 | |
| 推荐/协同过滤 | Non-distributed recommenders | Taste(UserCF, ItemCF, SlopeOne) |
| - | Distributed Recommenders | ItemCF |
| 向量相似度计算 | RowSimilarityJob | 计算列间相似度 |
| - | VectorDistanceJob | 计算向量间距离 |
| 非Map-Reduce算法 | Hidden Markov Models | 隐马尔科夫模型 |
| 集合方法扩展 | Collections | 扩展了java的Collections类 |
2相关的资源
书:
Apache Mahout cookbook- Book by Piero Giacomelli published Dec 2013
by Packtpub.
2013年出版的书籍,基本介绍了mahout的内容,编的也必将好。Mahout in Action - Book by Sean Owen, Robin Anil, Ted Dunning and Ellen Friedman published Oct 2011 by Manning Publications.
有一点点老Taming Text - By Grant Ingersoll and Tom Morton, published by Manning Publications. Will have some Mahout coverage, but by no means
as complete as Mahout in Action.
网站:
官网,特别好的网站,里面有很多例子
http://mahout.apache.org/
3 环境搭建
3.1安装Ubantu
这个比较简单,网上的教程也很多,这里不详细讲述。我使用的是64位的ubantu系统和VMware
3.2安装jdk、maven、hadoop
我使用的安装包和数据都在这里:
http://pan.baidu.com/s/1o7boog6
首先下载好安装包,hadoop2.7需要java1.6以上的环境才可以。下载好的情况如下: 
然后把它们对解压:
tar -C /home/user/ -xvzf jdk-7u79-linux-x64.gztar -C /home/user/ -xvzf hadoop-2.7.1.tar.gztar -C /home/user/ -xvzf apache-maven-3.0.5-bin.tar.gz通过修改~/.profile文件配置局部的环境变量
Vi ~/.profile在之后追加:
export JAVA_HOME=/home/user/jdk1.7.0_79
export HADOOP_HOME=/home/user/hadoop-2.7.1
export MAVEN_HOME=/home/user/apache-maven-3.0.5
export PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$HADOOP_HOME/bin如图: 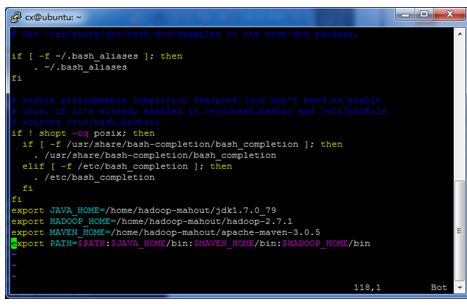
然后输入source ~/.profile使其生效
然后使用java -version 和mvn -version验证环境变量的配置情况,如果成功就会有如下的显示: 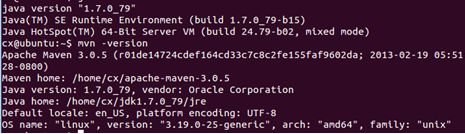
否则有可能是环境变量配置错误,或者是没有source,有时候重启一下控制台可以会影响。
在hadoop_home目录下输入如下命令,验证hadoop的安装情况:
hadoop jar /home/user/hadoop-0.23.5/share/hadoop/mapreduce/hadoopmapreduce-
examples-0.23.5.jar pi 10 100如果成功的话,就会输出如下值: 
(如果只是使用推荐算法(Taste)那么上面这些配置就够了,要通过命令行来使用mahout的话还需要进行下面的配置)
如果成功可以继续进行hadoop的配置,配置方法如下:
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
按照官网的文档中的伪分布式(Pseudo-Distributed Operation)的配置方法配置hadoop
然后接着按照下面的方法进行ssh的安装配置和开启hdfs系统。
安装成功之后输入jps命令可以看到
51013 DataNode
51208 SecondaryNameNode
50879 NameNode
51522 NodeManager
这些内容,如果没有,说明hadoop没有配置好
3.3安装netbean
直接运行netbeans-8.1-javase-linux.sh就可以对其进行安装:
sh netbeans-8.1-javase-linux.sh也可以使用eclipse,只是要配置maven插件和svn插件,这里的netbean已经自带这两个插件了
3.4获取mahout
打开netbean,打开选项页Team|Subversion|Checkout
通过下面的地址获取mathou:
http://svn.apache.org/repos/asf/mahout/trunk
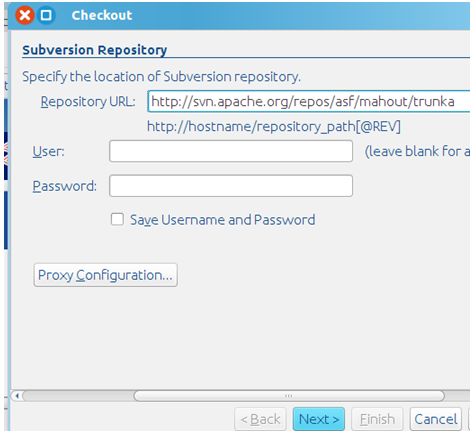
然后选择finish就会开始获取mahout,下载完成之后,右键点击项目,选择clean and build就可以自动的下载依赖包,并且对mahout进行编译,这里要花费一些事件,需要耐心的等待。
3.5配置mahout的环境变量
等待编译完成就可以,就可以对mahout的环境变量进行配置了,如果没有配置这个环境变量。依然可以通过代码使用mahout的一些功能,但是无法通过命令行来使用。
首先,修改~/.profile文件(不要忘记source)。更具目录添加mahout的环境变量:
export JAVA_HOME=/home/user/jdk1.7.0_79
export HADOOP_HOME=/home/user/hadoop-2.7.1
export MAVEN_HOME=/home/user/apache-maven-3.0.5
export MAHOUT_HOME=/home/user/NetBeansProjects/trunk
export PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$HADOOP_HOME/bin:$MAHOUT_HOME/bin
export CLASSPATH=$MAHOUT_HOME/lib:$JAVA_HOME/lib然后进入MAOUT_HOME目录的bin目录下,使用命令为mahout文件添加运行的权限,:
sudo chmod 777 mahout最后可以输入mahout来验证环境变量的配置情况
如果配置的正确就会输入mahout具有的算法如下: 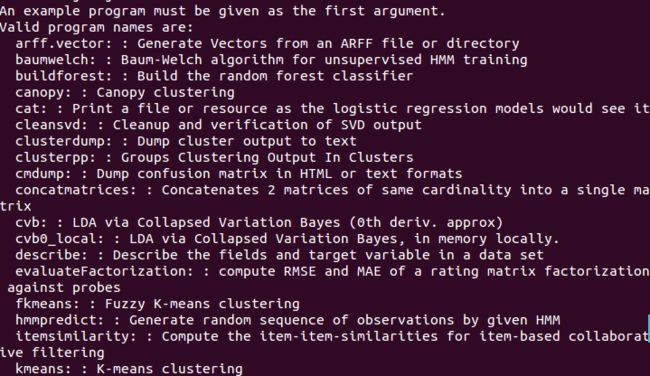
至此,mahout需要使用的环境变量就基本配置完毕了。