Flink1.10新特性探究之Hive整合以及实时数据处理实例(上)
最近工作比较忙,地铁上受到一位陌生老哥举动鼓舞,终于下定决心写了!ps:感谢老哥(haha)一直想写一篇Flink1.10.0与Hive的整合博文,上周末进行的整合探究,现将心得和实践实例呈上,希望给正在探索的小伙伴提供一些帮助,顺带将Flink新特性在数据实时处理上的心得一并呈上,口水话不多说了,咱们直接开干!!!!!!!!!
================>
文章目录
- 开发环境版本说明
- 摘要
- 本文大纲
- 环境搭建
- 基础环境准备
- Flink环境准备
- 安装 Flink
- SQL Client与hive集成配置**
- 加入依赖包
- 启动
- Kafka数据准备测试
- 启动kafka
- 创建主题测试消费
- 用SQL Client读取kafka数据
- 启动sql client
- Flink sql client创建表,测试消费流数据
- 创建表
- 写数据(消费Kafka)
- 验证查看数据表
开发环境版本说明
| 组件 | 版本号 |
|---|---|
| jdk | 1.8 |
| Centos | 7.X |
| hadoop | 2.7.2 |
| Hive | 1.2.1 |
| Zookeeper | 3.4.1 |
| Kafka | 2.11 |
| Flink | 1.10.0 |
摘要
Flink 1.10 与 1.9 相比又是个创新版本,在我们感兴趣的很多方面都有改进,特别是 Flink SQL。
很期待用纯sql的形式来处理流式数据,flink 1.10推出了生产可用的 Hive 集成,拥有了更强的流式 SQL 处理能力。这次我们就来尝试一下啦~~
按照惯例,增加阅读兴趣,码儿们,给你们来个美妹儿

一是 SQL DDL 对事件时间的支持;
二是 Hive Metastore 作为 Flink 的元数据存储(即 HiveCatalog)。
本文大纲
1、环境准备
2、SQL Client与hive集成配置
3、用SQL Client读取kafka数据
4、用根据埋点日志计算 PV、UV 的简单示例来体验 Flink 1.10 的两个重要新特性
环境搭建
基础环境准备
这里暂不做赘述,但凡玩数据的 (zk、Hadoop、kafka、hive)默认你们已经准备OK
这里重要说下Flink(主研Flink)
Flink环境准备
Flink安装
standalone模式
安装 Flink
解压缩 flink-1.10.0-bin-scala_2.11.tgz,进入conf目录中。
1)修改 flink/conf/flink-conf.yaml 文件:

2)修改 /conf/slave文件:
![]()
3)分发给另外两台机子:
4)启动:
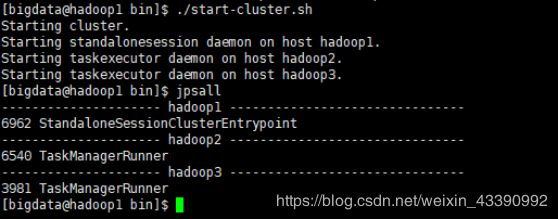
访问http://localhost:8081可以对flink集群和任务进行监控管理。
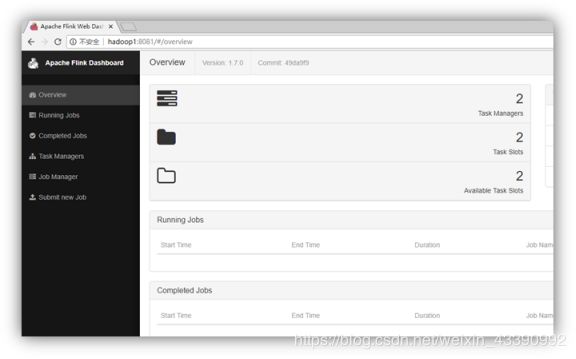
注意,根据自己机器情况进行操作,不要一味模仿照抄。
SQL Client与hive集成配置**
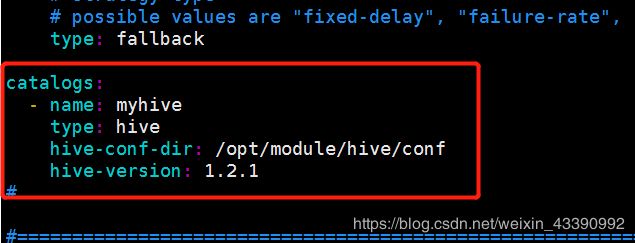
配制yaml文件
cp $FLINK_HOME/conf/sql-client-defaults.yaml sql-client-hive.yamlvim $FLINK_HOME/conf/sql-client-hive.yaml
配置该文件,这里粘出重要部分,里面详细配置自行查看:
加入依赖包
这里最容易 出错,注意!!!
切记,官网的东西并不是很准,根据自身情况而定(需要大家会排错)
这里引用别人粘贴的东西:
H I V E H O M E / l i b / h i v e − e x e c − 2.3.4. j a r HIVE_HOME/lib/hive-exec-2.3.4.jar HIVEHOME/lib/hive−exec−2.3.4.jarHIVE_HOME/lib/hive-common-2.3.4.jar H I V E H O M E / l i b / h i v e − m e t a s t o r e − 2.3.4. j a r HIVE_HOME/lib/hive-metastore-2.3.4.jar HIVEHOME/lib/hive−metastore−2.3.4.jarHIVE_HOME/lib/hive-shims-common-2.3.4.jar H I V E H O M E / l i b / a n t l r − r u n t i m e − 3.5.2. j a r HIVE_HOME/lib/antlr-runtime-3.5.2.jar HIVEHOME/lib/antlr−runtime−3.5.2.jarHIVE_HOME/lib/datanucleus-api-jdo-4.2.4.jar H I V E H O M E / l i b / d a t a n u c l e u s − c o r e − 4.1.17. j a r HIVE_HOME/lib/datanucleus-core-4.1.17.jar HIVEHOME/lib/datanucleus−core−4.1.17.jarHIVE_HOME/lib/datanucleus-rdbms-4.1.19.jar H I V E H O M E / l i b / j a v a x . j d o − 3.2.0 − m 3. j a r HIVE_HOME/lib/javax.jdo-3.2.0-m3.jar HIVEHOME/lib/javax.jdo−3.2.0−m3.jarHIVE_HOME/lib/libfb303-0.9.3.jar$HIVE_HOME/lib/jackson-core-2.6.5.jar
其他包:
commons-cli-1.3.1.jarflink-connector-hive_2.11-1.10.0.jarflink-hadoop-compatibility_2.11-1.10.0.jarflink-shaded-hadoop2-uber-blink-3.2.4.jarflink-table-api-java-bridge_2.11-1.10.0.jarmysql-connector-java-5.1.9.jar
官网图:
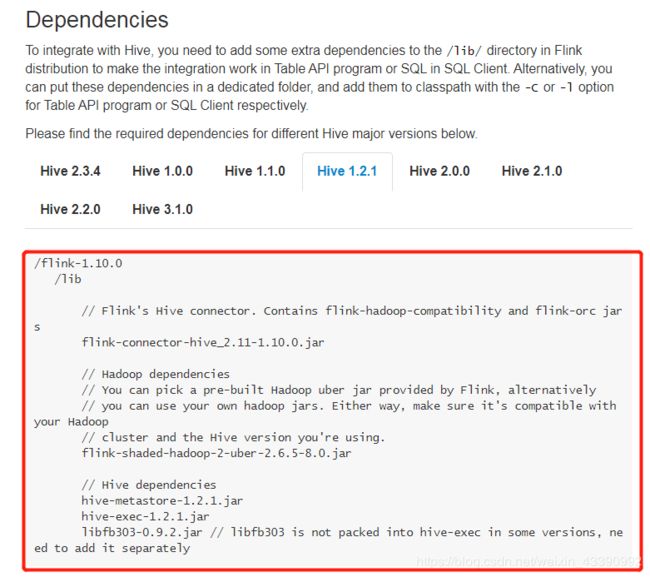
缺少的包下载地址:

很多缺失包都在这里下载,自己找下:
查找与之对应的:
Flink的jar都在这里了:
https://repository.apache.org/content/groups/snapshots/org/apache/flink/
https://repo1.maven.org/maven2/org/apache/flink/flink-connector-hive_2.11/1.10.0/
我自己最后的包:[自己对照看下]
附上图片:

比如有些包是Hive1.2.1中没有的,这里从2.X版本down过来的
比如:

等等。。。。。。
启动
start-cluster.sh
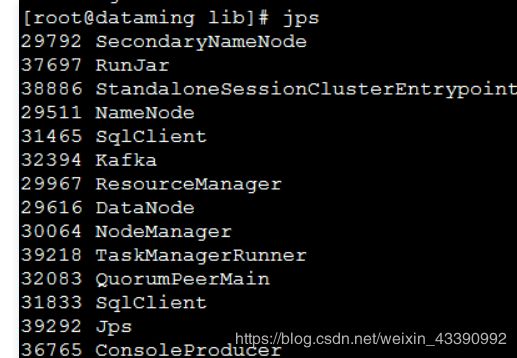
Kafka数据准备测试
启动kafka
zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties &kafka-server-start.sh $KAFKA_HOME/config/server.properties &
创建主题测试消费
kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic flinktest
kafka-topics.sh --list --bootstrap-server localhost:9092 ##查看创建的topic
测试生产消费者:
kafka-console-producer.sh --broker-list localhost:9092 --topic flinktest ##生产者
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic flinktest --from-beginning ##消费者
如下图,没什么问题:


以上,准备好了实时数据源,方便后面做测试用
用SQL Client读取kafka数据
启动sql client
sql-client.sh embedded -d conf/sql-client-hive.yaml
启动中:
[bigdata@hadoop102 flink-1.10.0]$ bin/sql-client.sh embedded -d conf/sql-client-hive.yaml
Reading default environment from: file:/opt/module/flink-1.10.0/conf/sql-client-hive.yaml
No session environment specified.
2020-05-19 23:21:45,266 INFO org.apache.hadoop.hive.metastore.HiveMetaStore - 0: Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
2020-05-19 23:21:45,356 INFO org.apache.hadoop.hive.metastore.ObjectStore - ObjectStore, initialize called
2020-05-19 23:21:46,883 INFO org.apache.hadoop.hive.metastore.ObjectStore - Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
2020-05-19 23:21:48,313 INFO org.apache.hadoop.hive.metastore.MetaStoreDirectSql - Using direct SQL, underlying DB is MYSQL
2020-05-19 23:21:48,316 INFO org.apache.hadoop.hive.metastore.ObjectStore - Initialized ObjectStore
2020-05-19 23:21:48,864 INFO org.apache.hadoop.hive.metastore.HiveMetaStore - Added admin role in metastore
2020-05-19 23:21:48,871 INFO org.apache.hadoop.hive.metastore.HiveMetaStore - Added public role in metastore
2020-05-19 23:21:49,009 INFO org.apache.hadoop.hive.metastore.HiveMetaStore - No user is added in admin role, since config is empty
2020-05-19 23:21:49,192 INFO org.apache.hadoop.hive.metastore.HiveMetaStore - 0: get_database: default
2020-05-19 23:21:49,210 INFO org.apache.hadoop.hive.metastore.HiveMetaStore.audit - ugi=bigdata ip=unknown-ip-addr cmd=get_database: default
出现下图就启动成功了:
久违的小松鼠====================》

执行如下:
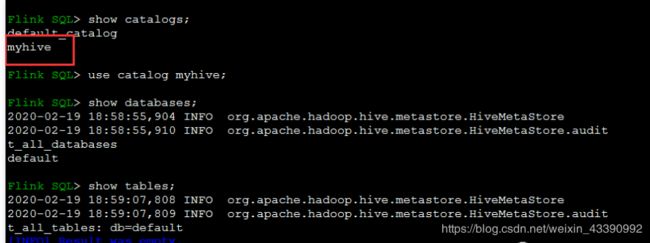
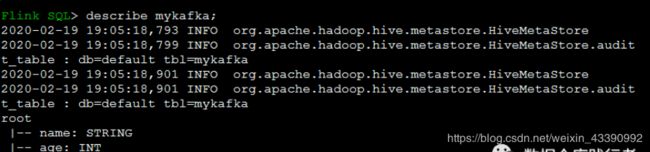
Flink sql client创建表,测试消费流数据
创建表
CREATE TABLE mykafka (name String,
age Int)
WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'flinktest', 'connector.properties.zookeeper.connect' = 'localhost:2181', 'connector.properties.bootstrap.servers' = 'localhost:9092', 'format.type' = 'csv',
'update-mode' = 'append');
此时在hive中也能看到用flink sql client 新创建的表啦:
回到HIve,即可查看创建的表
为什么呢?因为咱们之前做了整合
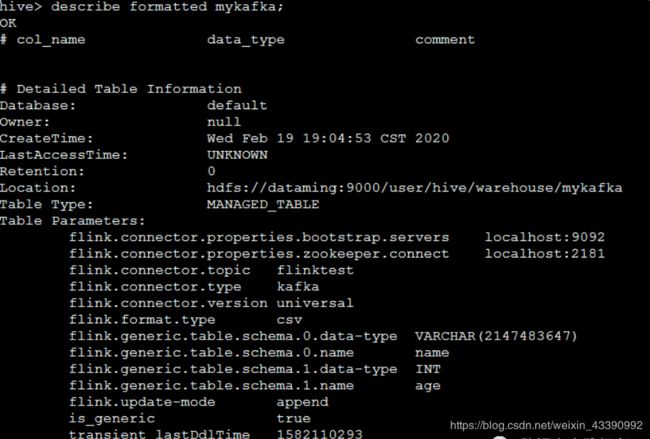
写数据(消费Kafka)
此时,用kafka生产端写入几条数据,可以从flink端查到了:

验证查看数据表
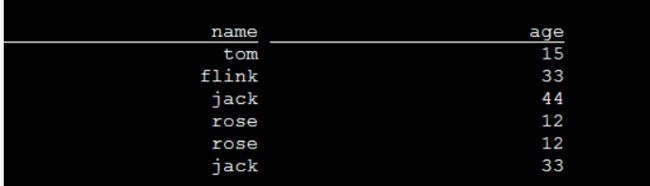
这样以来,就可以通过SQL Client这种纯SQL的方式来操作实时数据了
SQL Client 应用很广,而且特别好用,很多公司都进行了开发整合,正马不停蹄的做流批一体的整合分析!!!!!!!!!!!!!!!
因为时间关系,
实时部分案例分享,后面再做补充