微信小程序学习(2)-云开发
微信小程序-云开发
微信小程序学习(1)
微信小程序学习(2)
文章目录
- 微信小程序-云开发
- 初始化+云函数的坑
- 云函数使用
- 老陈段子
- 小程序云存储
- 小程序云数据库
- 初始化插入
- 简单查询
- 更新数据
- 删除数据
- Aggregate联合查询
- addFields派生/替换字段
- bucket分组
- bucketAuto自动分组
- granularity 详细说明
- count记录数
- geoNear地理位置索引
- group分组
- limit输出限制
- lookup联表查询(yun)
- match查询
- project操作字段
- replaceRoot换根节点
- simple 随机抽取
- skip跳过指定条数
- sort排序
- sortByCount 组排序
- unwind数组拆分
- end 结束
- command查询命令
- 查询·逻辑操作符(and、or、not、nor)
- 查询·比较操作符(eq、neq、lt、lte、gt、gte、in、nin)
- 查询·字段操作符(exists、mod)
- 查询·数组操作符(all、elemMatch、size)
- 查询·地理位置操作符(geoNear、geoWithin、geoInteersects)
- 查询·表达式操作符(expr)
- 更新·字段操作符(set、remove、inc、mul、min、max、rename)
- 更新·数组操作符(push、pop、unshift、shift、pull、pullAll、addToSet)
- ***聚合操作符$**
- 算数操作符(abs、add、ceil、divide、exp、floor、ln、log、log、log10、mod、multiply、pow、sqrt、subtract、trunc)
- 数组操作符(arrayElemAt、arrayToObject、concatArrays、filter、in、indexOfArray、isArray、map、objectToArray、range、reduce、reverseArray、size、slice、zip)
- 布尔操作符(and、not、or)
- 比较操作符(cmp、eq、gt、gte、lt、lte、neq)
- 日期操作符(dateFromParts、dateFromString、dateToString、dayOfMonth、dayOfweek、dayOfYear、hour、isoDayOfWeek、isoWeek、isoWeekYear、millisecond、minute、month、second、week、year、subtract)
- 常量操作符(iteral)
- 对象操作符(mergeObjects、objectToArray)
- 集合操作符(allElementsTrue、anyElementTrue、setDifference、setEquals、setIntersection、setIsSubset、setUnion)
- 字符串操作符(concat、dateFromString、dateToString、indexOfBytes、indexOfCP、split、strLenBytes、strLenCP、strcasecmp、substr、substrBytes、substrCP、toLower、toUpper)
- 累计器操作符(addToSet、avg、first、last、max、min、push、stdDevPop、stdDevSamp、sum)
- 变量操作符(let)
初始化+云函数的坑
新建一个lcduanzi的项目,拿到之前之策的微信小程序的AppID(云开发必须有)
创建完项目报错invalid scope 没有权限,请先开通云服务
警告我们要去创建云开发环境
小程序云开发是serveless的一种方式,后端操作相对于前端会友好


之后等几分钟,云函数服务初始化完成之后,右击login,上传云部署(云端安装依赖),发现可以拿到用户openid的操作了
初始化到这里,然后尝试新建页面"pages/laochen/duanzi",页面还挺多的

然后试着新建云函数

新建之后同步云函数列表,然后还要下载下来
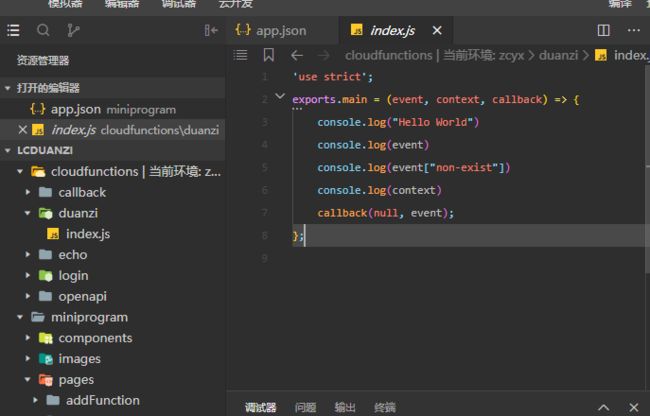
修改一下
'use strict';
exports.main = (event, context) => {
console.log("Hello World")
console.log(event)
console.log(context)
return {
admin:'root',
}
};
之后的调用方式如下
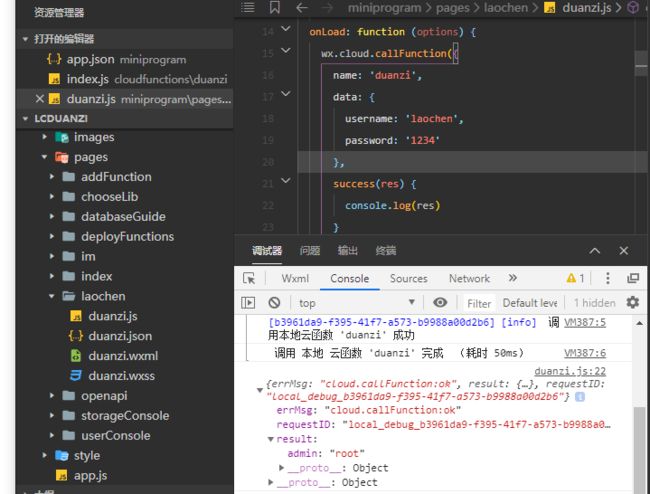


但是云调试有点不好用,容易卡住和莫名报错
修改后本地调试没问题就上传同步云端函数
然后撞到大问题了
本地用callback报错,云端用return返回null
(什么鬼啊!!!!!)
老师给我找到答案了orz原来是异步函数的问题,而且node版本大改了
https://blog.csdn.net/weixin_43387238/article/details/106823390

给测试代码加个async就分分钟能用了(好坑啊)
云函数使用
因为云函数其实就是我们的后端node,请求数据可以写在这里
话不多说先装个axios
tyarn add axios
tyarn是yarn的阿里镜像感觉稍稍快一些

数据路径https://api.apiopen.top/getJoke


onLoad: function (options) {
wx.cloud.callFunction({//调用云端函数
name: 'duanzi',
data: { page: 1, count: 10, type: 'image' },
success(res) {
console.log(res)
}
})
},
'use strict';
let axios = require('axios')
let httpUrl = "https://api.apiopen.top/getJoke"
// let options = [
// { page: 1, count: 10, type: 'text' },
// { page: 1, count: 10, type: 'image' },
// { page: 1, count: 10, type: 'vedio' }
// ]
exports.main = async (event, context) => {
let res=await axios.get(httpUrl,{params:event})
return res.data//云端的返回值
};
本地和云端都没问题,直接使用部署到云端的接口就行了
老陈段子
主要是使用api的数据进行循环渲染,然后下拉到底部无限刷新增加数据
一会下面把完整代码贴出来就行了,三个页面差不多
https://gitee.com/mus-z/lcduanzi/tree/master/miniprogram

只展示image页面(其实三个差不多是一样的)
<view class="view">
<view class="list">
<view class="listItem" wx:for="{{dzList}}" wx:key="index" data-sid="{{item.sid}}" data-uid="{{item.uid}}">
<view class="itemHeader">
<view class="headerimg">
<image src="{{item.header}}">image>
view>
<view class="text">
<view class="username">{{item.name}}view>
<view class="time">{{item.passtime}}view>
view>
view>
<view class="itemContent">
{{item.text}}
<view class="contentImg">
<image src="{{item.images}}" mode="widthFix" wx:if="{{item.images}}">image>
<video src="{{item.video}}" wx:if="{{item.video}}" poster="{{item.thumbnail}}">video>
view>
view>
<view class="itemFooter">
<view class="zf">
<image src="/images/点赞.png">image>
<text>{{item.up}}text>
view>
<view class="pl">
<image src="/images/评论.png">image>
<text>{{item.comment}}text>
view>
<view class="dz">
<image src="/images/转发.png">image>
<text>{{item.forward}}text>
view>
view>
view>
view>
view>
// miniprogram/pages/laochen/image.js
Page({
/**
* 页面的初始数据
*/
data: {
dzList:[],
page:1,
},
/**
* 生命周期函数--监听页面加载
*/
onLoad: function (options) {
wx.cloud.callFunction({
name: 'duanzi',
data: { page: 1, count: 10, type: 'image' },
success:(res)=>{
console.log(res)
this.setData({
dzList:res.result.result
})
}
})
},
/**
* 页面上拉触底事件的处理函数
*/
onReachBottom: function () {
wx.showLoading({
title: '加载中',
})
let page=this.data.page+1;
wx.cloud.callFunction({
name: 'duanzi',
data: { page: page, count: 10, type: 'image' },
success:(res)=>{
console.log(res)
let dzList=[...this.data.dzList,...res.result.result||[]]
if(res.result&&res.result.result&&res.result.result.length>0){
this.setData({
dzList:dzList,
page:page,
})
wx.hideLoading()
}else{
wx.hideLoading()
wx.showToast({
title: '没数据啦',
icon: 'warn',
duration: 2000
})
}
}
})
},
})
/* miniprogram/pages/laochen/image.wxss */
.listItem {
width: 700rpx;
background-color: #ddd;
border-radius: 20rpx;
margin: 25rpx;
}
.listItem .itemHeader {
display: flex;
height: 80rpx;
align-items: center;
padding: 20rpx 0;
}
.listItem .headerimg {
width: 64rpx;
height: 64rpx;
padding: 10rpx 20rpx;
}
.listItem .headerimg image {
width: 64rpx;
height: 64rpx;
border-radius: 50%;
}
.listItem .headerimg .username {
font-size: 30rpx;
}
.listItem .time {
font-size: 24rpx;
color: #aaa;
}
.listItem .itemContent {
padding: 0 24rpx 12rpx;
}
.listItem .itemFooter {
display: flex;
width: 750rpx;
box-sizing: border-box;
padding: 24rpx;
padding-top: 0rpx;
}
.itemFooter>view {
display: flex;
padding: 0 36rpx 12rpx 0;
justify-content: center;
align-items: center;
}
.dz>image,
.pl>image,
.zf>image {
width: 40rpx;
height: 40rpx;
margin-right: 10rpx;
}
.listItem .itemContent image {
width: 100%;
margin: 10rpx 0;
}
.listItem .itemContent video {
width: 100%;
margin: 10rpx 0;
}
小程序云存储
新建一个页面 upload
<button bindtap="uploadEvent" type="primary">上传图片button>
uploadEvent(){
//1.选择图片,本机相册
wx.chooseImage({
success:(res)=>{
console.log(res)
//res.tempFilePaths[0]
//2.上传图片
wx.cloud.uploadFile({
cloudPath:new Date().valueOf()+'.png',
filePath:res.tempFilePaths[0],
success:(result)=>{
console.log(result)
}
})
}
,fail:(err)=>{
console.log(err)
}
})
},


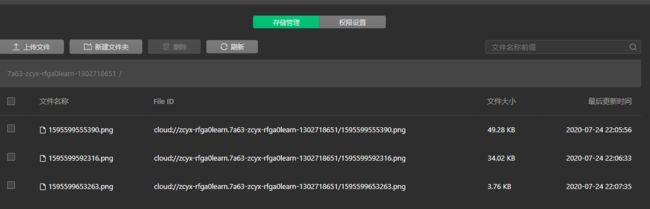
云服务器也是可以查看我们上传的东西的
试了下上传任意格式的文件,缺点是用手机预览的时候发现只能看微信聊天窗口的历史文件,所以要借助文件传输助手先发过我们的文件,然后再去选
uploadEvent(){
// //1.选择图片,本机相册
// wx.chooseImage({
// success:(res)=>{
// console.log(res)
// //res.tempFilePaths[0]
// //2.上传图片
// wx.cloud.uploadFile({
// cloudPath:new Date().valueOf()+'.png',
// filePath:res.tempFilePaths[0],
// success:(result)=>{
// console.log(result)
// this.setData({
// imgSrc:result.fileID,
// })
// }
// })
// }
// ,fail:(err)=>{
// console.log(err)
// }
// })
//4.想试一下别的文件
wx.chooseMessageFile({
success:(res)=>{
console.log(res)
//res.tempFiles[0].path
if(res.tempFiles.length>0){
wx.cloud.uploadFile({
//这个地方需要加上后缀
cloudPath:new Date().valueOf()+'.'+res.tempFiles[0].name.split('.').pop(),
filePath:res.tempFiles[0].path,
success:(result)=>{
console.log(result)
wx.showToast({
title: 'success',
duration:1000,
})
this.setData({
//imgSrc:result.fileID,
})
}
,fail:(err)=>{
console.log(err)
wx.showToast({
title: 'fail',
duration:1000,
})
}
})
}else{
console.log('err:获取文件失败')
wx.showToast({
title: 'fail',
duration:1000,
})
}
},fail:(err)=>{
console.log(err)
wx.showToast({
title: 'fail',
duration:1000,
})
},
})
},
小程序云数据库
https://developers.weixin.qq.com/miniprogram/dev/wxcloud/guide/database.html#%E6%95%B0%E6%8D%AE%E5%BA%93
小程序的云数据库是非关系型的数据库,基本上是操作json对象
新建一个页面db

然后打开云开发数据库,新建一个集合dbtest
初始化插入
然后在db.js中
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VFNa0a5f-1595745595451)(upload\image-20200725173239617.png)]
这样就已经可以插入记录并得到_id作为主键返回值了

_id是自动生成的主键, _openid是传入的用户的关键字
简单查询
直接调用连接的.doc(_id)方法


想要拿到所有数据就直接.get()
如果想获取多条数据的话,需要用到where方法来指定字段

对象的形式是可以深层向下搜索的

对于单个属性的判断,还可以用db.command作为比较的指令
https://developers.weixin.qq.com/miniprogram/dev/wxcloud/guide/database/query.html
| 查询指令 | 说明 |
|---|---|
| eq | 等于 |
| neq | 不等于 |
| lt | 小于 |
| lte | 小于或等于 |
| gt | 大于 |
| gte | 大于或等于 |
| in | 字段值在给定数组中 |
| nin | 字段值不在给定数组中 |
以及逻辑指令 and或or
//下面使用dbcommand
let command = this.command;
this.con.where({
//用对象来表示我们sql形式的where
test: 1,
num:command.lt(200).or(command.gte(1000))
}).get().then(res => {
console.log(res)
})
更新数据
https://developers.weixin.qq.com/miniprogram/dev/wxcloud/guide/database/update.html


删除数据
删除一条记录的时候

但是删除多条记录要求我们放到云函数去做,或者我觉得可以先查询把_id都存下来再循环删除

试一下云函数删除的操作
wx.cloud.callFunction({
name:'deleteDb',
data:{test:null},//这次我想删掉test为null的字段(也就是没有添加test的)
success:(res)=>{
console.log(res)
}
})
先用get看看能不能拿到,发现可以

// 云函数入口文件
const cloud = require('wx-server-sdk')
cloud.init()
// 云函数入口函数
exports.main = async (event, context) => {
console.log(event)
let res=cloud.database().collection('dbtest').where({
...event
}).remove()
return res
}
测试一下是可以删除的

发现本地测试和云端测试都能正常删除,但是如果云调用就不行,查了下日志发现


多了奇奇怪怪的东西,应该是我的写法有问题我去改改哦
// 云函数入口文件
const cloud = require('wx-server-sdk')
cloud.init()
// 云函数入口函数
exports.main = async (event, context) => {
console.log(event)
let res=cloud.database().collection('dbtest').where({
test:event.test,
}).remove()
return res
}
这样就没问题了
Aggregate联合查询
https://developers.weixin.qq.com/miniprogram/dev/wxcloud/reference-sdk-api/database/aggregate/Aggregate.lookup.html#%E7%A4%BA%E4%BE%8B
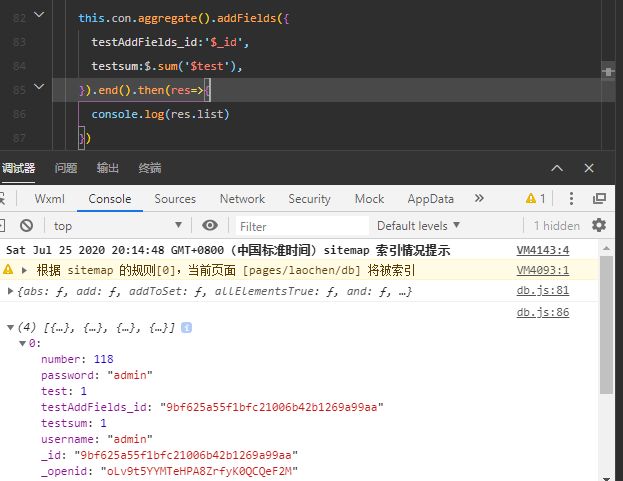
addFields派生/替换字段
addFields 等同于同时指定了所有已有字段和新增字段的 project 阶段。
addFields 的形式如下:
addFields({
<新字段>: <表达式>
})
addFields 可指定多个新字段,每个新字段的值由使用的表达式决定。
如果指定的新字段与原有字段重名,则新字段的值会覆盖原有字段的值。注意 addFields 不能用来给数组字段添加元素。

bucket分组
每组分别作为一个记录输出,包含一个以下界为值的 _id 字段和一个以组中记录数为值的 count 字段。count 在没有指定 output 的时候是默认输出的。
bucket 只会在组内有至少一个记录的时候输出。
bucket 的形式如下:
bucket({
groupBy: ,
boundaries: [, , ...],
default: ,
output: {
: ,
...
:
}
})
groupBy 是一个用以决定分组的表达式,会应用在各个输入记录上。可以用 $ 前缀加上要用以分组的字段路径来作为表达式。除非用 default 指定了默认值,否则每个记录都需要包含指定的字段,且字段值必须在 boundaries 指定的范围之内。
boundaries 是一个数组,每个元素分别是每组的下界。必须至少指定两个边界值。数组值必须是同类型递增的值。
default 可选,指定之后,没有进入任何分组的记录将都进入一个默认分组,这个分组记录的 _id 即由 default决定。default 的值必须小于 boundaries 中的最小值或大于等于其中的最大值。default 的值可以与 boundaries元素值类型不同。
output 可选,用以决定输出记录除了 _id 外还要包含哪些字段,各个字段的值必须用累加器表达式指定。当 output 指定时,默认的 count 是不会被默认输出的,必须手动指定:
output: {
count: $.sum(1),
...
:
}
使用 bucket 需要满足以下至少一个条件,否则会抛出错误:
- 每一个输入记录应用
groupBy表达式获取的值都必须是一个在boundaries内的值 - 指定一个
default值,该值在boundaries以外,或与boundaries元素的值不同的类型
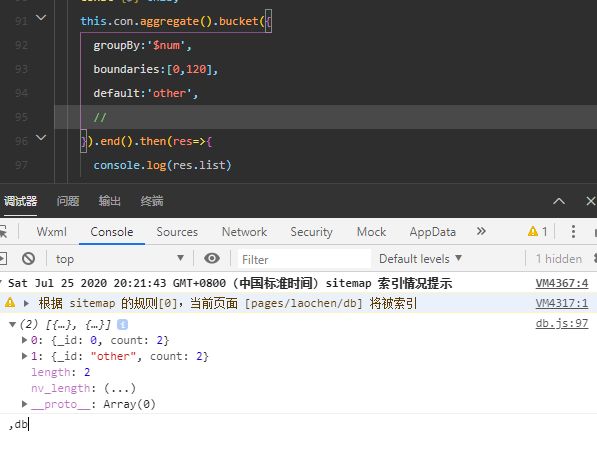
list[0]是[0,120),default是(-#,0)U[120,+#)
尝试一下自定义output

bucketAuto自动分组
每组分别作为一个记录输出,包含一个以包含组中最大值和最小值两个字段的对象为值的 _id 字段和一个以组中记录数为值的 count 字段。count 在没有指定 output 的时候是默认输出的。
bucketAuto 的形式如下:
bucketAuto({
groupBy: ,
buckets: ,
granularity: ,
output: {
: ,
...
:
}
})
groupBy 是一个用以决定分组的表达式,会应用在各个输入记录上。可以用 $ 前缀加上要用以分组的字段路径来作为表达式。除非用 default 指定了默认值,否则每个记录都需要包含指定的字段,且字段值必须在 boundaries 指定的范围之内。
buckets 是一个用于指定划分组数的正整数。
granularity 是可选枚举值字符串,用于保证自动计算出的边界符合给定的规则。这个字段仅可在所有 groupBy 值都是数字并且没有 NaN 的情况下使用。枚举值包括:R5、R10、R20、R40、R80、1-2-5、E6、E12、E24、E48、E96、E192、POWERSOF2。
output 可选,用以决定输出记录除了 _id 外还要包含哪些字段,各个字段的值必须用累加器表达式指定。当 output 指定时,默认的 count 是不会被默认输出的,必须手动指定:
output: {
count: $.sum(1),
...
:
}
在以下情况中,输出的分组可能会小于给定的组数:
- 输入记录数少于分组数
groupBy计算得到的唯一值少于分组数granularity的间距少于分组数granularity不够精细以至于不能平均分配到各组
granularity
granularity 详细说明
granularity用于保证边界值属于一个给定的数字序列。Renard 序列
Renard 序列是以 10 的 5 / 10 / 20 / 40 / 80 次方根来推导的、在 1.0 到 10.0 (如果是 R80 则是 10.3) 之间的数字序列。
设置
granularity为 R5 / R10 / R20 / R40 / R80 就把边界值限定在序列内。如果groupBy的值不在 1.0 到 10.0 (如果是 R80 则是 10.3) 内,则序列数字会自动乘以 10。E 序列
E 序列是以 10 的 6 / 12 / 24 / 48 / 96 / 192 次方跟来推导的、带有一个特定误差的、在 1.0 到 10.0 之间的数字序列。
1-2-5 序列
1-2-5 序列 表现与三值 Renard 序列一样。
2的次方序列
由 2 的各次方组成的序列数字。
buckets表示自动分组的数量

count记录数
count 的形式如下:
count()
是输出记录数的字段的名字,不能是空字符串,不能以 $ 开头,不能包含 . 字符。
count 阶段等同于 group + project 的操作

geoNear地理位置索引
geoNear必须为第一个聚合阶段- 必须有地理位置索引。如果有多个,必须用
key参数指定要使用的索引
示例
假设集合 attractions 有如下记录:
{
"_id": "geoNear.0",
"city": "Guangzhou",
"docType": "geoNear",
"location": {
"type": "Point",
"coordinates": [
113.30593,
23.1361155
]
},
"name": "Canton Tower"
},
{
"_id": "geoNear.1",
"city": "Guangzhou",
"docType": "geoNear",
"location": {
"type": "Point",
"coordinates": [
113.306789,
23.1564721
]
},
"name": "Baiyun Mountain"
},
{
"_id": "geoNear.2",
"city": "Beijing",
"docType": "geoNear",
"location": {
"type": "Point",
"coordinates": [
116.3949659,
39.9163447
]
},
"name": "The Palace Museum"
},
{
"_id": "geoNear.3",
"city": "Beijing",
"docType": "geoNear",
"location": {
"type": "Point",
"coordinates": [
116.2328567,
40.242373
]
},
"name": "Great Wall"
}
const $ = db.command.aggregate
db.collection('attractions').aggregate()
.geoNear({
distanceField: 'distance', // 输出的每个记录中 distance 即是与给定点的距离
spherical: true,
near: db.Geo.Point(113.3089506, 23.0968251),
query: {
docType: 'geoNear',
},
key: 'location', // 若只有 location 一个地理位置索引的字段,则不需填
includeLocs: 'location', // 若只有 location 一个是地理位置,则不需填
})
.end()
返回结果如下:
{
"_id": "geoNear.0",
"location": {
"type": "Point",
"coordinates": [
113.30593,
23.1361155
]
},
"docType": "geoNear",
"name": "Canton Tower",
"city": "Guangzhou",
"distance": 4384.68131486958
},
{
"_id": "geoNear.1",
"city": "Guangzhou",
"location": {
"type": "Point",
"coordinates": [
113.306789,
23.1564721
]
},
"docType": "geoNear",
"name": "Baiyun Mountain",
"distance": 6643.521654040738
},
{
"_id": "geoNear.2",
"docType": "geoNear",
"name": "The Palace Museum",
"city": "Beijing",
"location": {
"coordinates": [
116.3949659,
39.9163447
],
"type": "Point"
},
"distance": 1894750.4414538583
},
{
"_id": "geoNear.3",
"docType": "geoNear",
"name": "Great Wall",
"city": "Beijing",
"location": {
"type": "Point",
"coordinates": [
116.2328567,
40.242373
]
},
"distance": 1928300.3308822548
}
group分组
group 的形式如下:
group({
_id: ,
: ,
...
:
})
_id 参数是必填的,如果填常量则只有一组。其他字段是可选的,都是累计值,用 $.sum 等累计器,但也可以使用其他表达式。
累计器必须是以下操作符之一:
- addToSet
- avg
- first
- last
- max
- min
- push
- stdDevPop
- stdDevSamp
- sum
内存限制
该阶段有 100M 内存使用限制

limit输出限制
限制输出到下一阶段的记录数,最好配合sort之后

lookup联表查询(yun)
不能在小程序端执行
1. 相等匹配
将输入记录的一个字段和被连接集合的一个字段进行相等匹配时,采用以下定义:
lookup({
from: <要连接的集合名>,
localField: <输入记录的要进行相等匹配的字段>,
foreignField: <被连接集合的要进行相等匹配的字段>,
as: <输出的数组字段名>
})
参数详细说明
| 参数字段 | 说明 |
|---|---|
| from | 要进行连接的另外一个集合的名字 |
| localField | 当前流水线的输入记录的字段名,该字段将被用于与 from 指定的集合的 foreignField 进行相等匹配。如果输入记录中没有该字段,则该字段的值在匹配时会被视作 null |
| foreignField | 被连接集合的字段名,该字段会被用于与 localField 进行相等匹配。如果被连接集合的记录中没有该字段,该字段的值将在匹配时被视作 null |
| as | 指定连接匹配出的记录列表要存放的字段名,这个数组包含的是匹配出的来自 from 集合的记录。如果输入记录中本来就已有该字段,则该字段会被覆写 |
这个操作等价于以下伪 SQL 操作:
SELECT *, <output array field>
FROM collection
WHERE <output array field> IN (SELECT *
FROM <collection to join>
WHERE <foreignField>= <collection.localField>);
例子:
-
指定一个相等匹配条件

-
对数组字段应用相等匹配
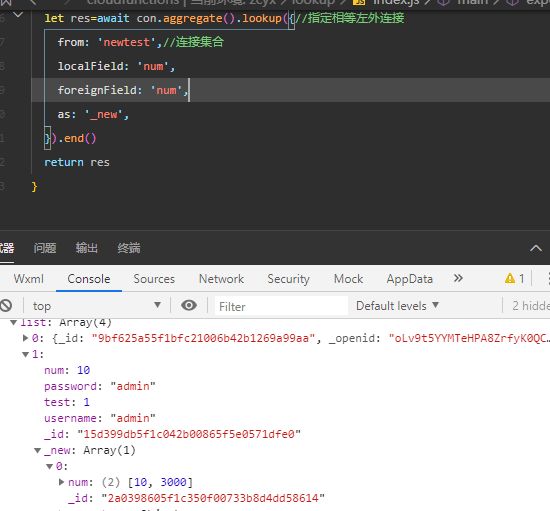
-
组合
mergeObjects应用相等匹配
2. 自定义连接条件、拼接子查询
如果需要指定除相等匹配之外的连接条件,或指定多个相等匹配条件,或需要拼接被连接集合的子查询结果,那可以使用如下定义:
lookup({
from: <要连接的集合名>,
let: { <变量1>: <表达式1>, ..., <变量n>: <表达式n> },
pipeline: [ <在要连接的集合上进行的流水线操作> ],
as: <输出的数组字段名>
})
参数详细说明
| 参数字段 | 说明 |
|---|---|
| from | 要进行连接的另外一个集合的名字 |
| let | 可选。指定在 pipeline 中可以使用的变量,变量的值可以引用输入记录的字段,比如 let: { userName: '$name' } 就代表将输入记录的 name 字段作为变量 userName 的值。在 pipeline 中无法直接访问输入记录的字段,必须通过 let 定义之后才能访问,访问的方式是在 expr 操作符中用 $$变量名 的方式访问,比如 $$userName。 |
| pipeline | 指定要在被连接集合中运行的聚合操作。如果要返回整个集合,则该字段取值空数组 []。在 pipeline 中无法直接访问输入记录的字段,必须通过 let 定义之后才能访问,访问的方式是在 expr 操作符中用 $$变量名 的方式访问,比如 $$userName。 |
| as | 指定连接匹配出的记录列表要存放的字段名,这个数组包含的是匹配出的来自 from 集合的记录。如果输入记录中本来就已有该字段,则该字段会被覆写 |
该操作等价于以下伪 SQL 语句:
SELECT *, <output array field>
FROM collection
WHERE <output array field> IN (SELECT <documents as determined from the pipeline>
FROM <collection to join>
WHERE <pipeline> );
例子
- 指定多个连接条件
- 拼接被连接集合的子查询

这部分写复杂连接的语法是真的看不懂,之后把command和aggregate的语法看完再看一下复杂的外连接
match查询
查询条件与普通查询一致,可以用普通查询操作符,注意 match 阶段和其他聚合阶段不同,不可使用聚合操作符,只能使用查询操作符
但是不知道为什么,我这边在match中不能用查询操作符,否则就不能用比较函数。。但是用了聚合操作符就没办法加and或者or

project操作字段
project 的形式如下:
project({
<表达式>
})
表达式可以有以下格式:
| 格式 | 说明 |
|---|---|
<字段>: <1 或 true> |
指定包含某个已有字段 |
_id: <0 或 false> |
舍弃 _id 字段 |
| <字段>: <表达式> | 加入一个新字段,或者重置某个已有字段 |
<字段>: <0 或 false> |
舍弃某个字段(如果你指定舍弃了某个非 _id 字段,那么在此次 project 中,你不能再使用其它表达式) |
指定包含字段
_id 字段是默认包含在输出中的,除此之外其他任何字段,如果想要在输出中体现的话,必须在 project 中指定; 如果指定包含一个尚不存在的字段,那么 project 会忽略这个字段,不会加入到输出的文档中;
指定排除字段
如果你在 project 中指定排除某个字段,那么其它字段都会体现在输出中; 如果指定排除的是非 _id 字段,那么在本次 project 中,不能再使用其它表达式;
加入新的字段或重置某个已有字段
你可以使用一些特殊的表达式加入新的字段,或重置某个已有字段。
多层嵌套的字段
有时有些字段处于多层嵌套的底层,我们可以使用点记法:
"contact.phone.number": <1 or 0 or 表达式>
也可以直接使用嵌套的格式:
contact: { phone: { number: <1 or 0 or 表达式> } }
replaceRoot换根节点
replaceRoot 使用形式如下:
replaceRoot({
newRoot: <表达式>
})
表达式格式如下:
| 格式 | 说明 |
|---|---|
| <字段名> | 指定一个已有字段作为输出的根节点(如果字段不存在则报错) |
| <对象> | 计算一个新字段,并且把这个新字段作为根节点 |
simple 随机抽取
sample 的形式如下:
sample({
size: <正整数>
})
请注意:size 是正整数,否则会出错
skip跳过指定条数
指定一个正整数,跳过对应数量的文档,输出剩下的文档。
sort排序
形式如下:
sort({
<字段名1>: <排序规则>,
<字段名2>: <排序规则>,
})
<排序规则>可以是以下取值:
1代表升序排列(从小到大);-1代表降序排列(从大到小)
升序/降序排列
假设我们有集合 articles,其中包含数据如下:
{ "_id": "1", "author": "stark", "score": 80, "age": 18 }
{ "_id": "2", "author": "bob", "score": 60, "age": 18 }
{ "_id": "3", "author": "li", "score": 55, "age": 19 }
{ "_id": "4", "author": "jimmy", "score": 60, "age": 22 }
{ "_id": "5", "author": "justan", "score": 95, "age": 33 }
db.collection('articles')
.aggregate()
.sort({
age: -1,
score: -1
})
.end()
上面的代码在 students 集合中进行聚合搜索,并且将结果排序,首先根据 age 字段降序排列,然后再根据 score字段进行降序排列。
输出结果如下:
{ "_id": "5", "author": "justan", "score": 95, "age": 33 }
{ "_id": "4", "author": "jimmy", "score": 60, "age": 22 }
{ "_id": "3", "author": "li", "score": 55, "age": 19 }
{ "_id": "1", "author": "stark", "score": 80, "age": 18 }
{ "_id": "2", "author": "bob", "score": 60, "age": 18 }
sortByCount 组排序
sortByCount 的调用方式如下:
sortByCount(<表达式>)
表达式的形式是:$ + 指定字段。请注意:不要漏写 $ 符号
统计基础类型
假设集合 passages 的记录如下:
{ "category": "Web" }
{ "category": "Web" }
{ "category": "Life" }
下面的代码就可以统计文章的分类信息,并且计算每个分类的数量。即对 category 字段执行 sortByCount 聚合操作。
db.collection('passages')
.aggregate()
.sortByCount('$category')
.end()
返回的结果如下所示:Web 分类下有2篇文章,Life 分类下有1篇文章。
{ "_id": "Web", "count": 2 }
{ "_id": "Life", "count": 1 }
解构数组类型
假设集合 passages 的记录如下:tags 字段对应的值是数组类型。
{ "tags": [ "JavaScript", "C#" ] }
{ "tags": [ "Go", "C#" ] }
{ "tags": [ "Go", "Python", "JavaScript" ] }
如何统计文章的标签信息,并且计算每个标签的数量?因为 tags 字段对应的数组,所以需要借助 unwind 操作解构 tags 字段,然后再调用 sortByCount。
下面的代码实现了这个功能:
db.collection('passages')
.aggregate()
.unwind(`$tags`)
.sortByCount(`$tags`)
.end()
返回的结果如下所示:
{ "_id": "Go", "count": 2 }
{ "_id": "C#", "count": 2 }
{ "_id": "JavaScript", "count": 2 }
{ "_id": "Python", "count": 1 }
unwind数组拆分
使用指定的数组字段中的每个元素,对文档进行拆分。拆分后,文档会从一个变为一个或多个,分别对应数组的每个元素。
unwind 有两种使用形式:
- 参数是一个字段名
unwind(<字段名>)
- 参数是一个对象
unwind({
path: <字段名>,
includeArrayIndex: ,
preserveNullAndEmptyArrays:
})
| 字段 | 类型 | 说明 |
|---|---|---|
| path | string | 想要拆分的数组的字段名,需要以 $ 开头。 |
| includeArrayIndex | string | 可选项,传入一个新的字段名,数组索引会保存在这个新的字段上。新的字段名不能以 $ 开头。 |
| preserveNullAndEmptyArrays | boolean | 如果为 true,那么在 path 对应的字段为 null、空数组或者这个字段不存在时,依然会输出这个文档;如果为 false,unwind 将不会输出这些文档。默认为 false |
end 结束
标志聚合操作定义完成,发起实际聚合操作
command查询命令
https://developers.weixin.qq.com/miniprogram/dev/wxcloud/reference-sdk-api/database/Command.html
查询-where|更新-update
查询·逻辑操作符(and、or、not、nor)
and是与、or是或、not是非、nor是都不
查询·比较操作符(eq、neq、lt、lte、gt、gte、in、nin)
eq是等于、neq是不等于、lt是小于、lte是小于等于、gt是大于、gte是大于等于、in是属于、nin是不属于
查询·字段操作符(exists、mod)
exists判断是否存在
mod给定除数 divisor 和余数 remainder,要求字段作为被除数时 value % divisor = remainder
查询·数组操作符(all、elemMatch、size)
all用于数组字段的查询筛选条件,要求数组字段中包含给定数组的所有元素
eleMatch用于数组字段的查询筛选条件,要求数组中包含至少一个满足 elemMatch 给定的所有条件的元素
size要求数组长度为给定值
查询·地理位置操作符(geoNear、geoWithin、geoInteersects)
geoNear找最近排序
geoWithin找区域内
geoInteersects找相交
查询·表达式操作符(expr)
expr方法接收一个参数,该参数必须为聚合表达式
expr可用于在聚合match流水线阶段中引入聚合表达式- 如果聚合
match阶段是在lookup阶段内,此时的expr表达式内可使用lookup中使用let参数定义的变量,具体示例可见lookup的指定多个连接条件例子 expr可用在普通查询语句(where)中引入聚合表达式
更新·字段操作符(set、remove、inc、mul、min、max、rename)
set用于设定字段等于指定值,而不只是更新一个属性
remove删除某个字段
inc表示自增,只能写number
mul表示自乘,也是用于number
min 如果字段 progress > 50,则更新到 50
const _ = db.command
db.collection('todos').doc('doc-id').update({
data: {
progress: _.min(50)
}
})
max类似min,如果字段 progress < 50,则更新到 50
const _ = db.command
db.collection('todos').doc('doc-id').update({
data: {
progress: _.max(50)
}
})
rename是字段重命名,如果需要对嵌套深层的字段做重命名,需要用点路径表示法。不能对嵌套在数组里的对象的字段进行重命名
更新·数组操作符(push、pop、unshift、shift、pull、pullAll、addToSet)
push对一个值为数组的字段,往数组添加一个或多个值。或字段原为空,则创建该字段并设数组为传入值
| 属性 | 类型 | 默认值 | 必填 | 说明 |
|---|---|---|---|---|
| each | Array. | 是 | 要插入的所有元素 | |
| position | number | 否 | 从哪个位置开始插入,不填则是尾部 | |
| sort | number | 否 | 对结果数组排序 | |
| slice | number | 否 | 限制结果数组长度 |
pop对一个值为数组的字段,将数组尾部元素删除
unshift对一个值为数组的字段,往数组头部添加一个或多个值。或字段原为空,则创建该字段并设数组为传入值,类似push
shift对一个值为数组的字段,将数组头部元素删除
pull给定一个值或一个查询条件,将数组中所有匹配给定值或查询条件的元素都移除掉
pullAll给定一个值或一个查询条件,将数组中所有匹配给定值的元素都移除掉。跟 pull 的差别在于只能指定常量值、传入的是数组
addToSet给定一个或多个元素,除非数组中已存在该元素,否则添加进数组
要添加进数组的一个或多个元素
| 属性 | 类型 | 默认值 | 必填 | 说明 |
|---|---|---|---|---|
| each | Array. | 是 | 数组,用于同时指定多个要插入数组的元素 |
*聚合操作符$
Expression:聚合表达式
字段路径:表达式用字段路径表示法来指定记录中的字段。字段路径的表示由一个 $ 符号加上字段名或嵌套字段名。嵌套字段名用点将嵌套的各级字段连接起来。如 $profile 就表示 profile 的字段路径,$profile.name 就表示 profile.name 的字段路径(profile 字段中嵌套的 name 字段)
常量可以是任意类型。默认情况下 $ 开头的字符串都会被当做字段路径处理,如果想要避免这种行为,使用 AggregateCommand.literal 声明为常量
算数操作符(abs、add、ceil、divide、exp、floor、ln、log、log、log10、mod、multiply、pow、sqrt、subtract、trunc)
abs返回一个数字的绝对值,语法如下:
db.command.aggregate.abs()
abs 传入的值除了数字常量外,也可以是任何最终解析成一个数字的表达式。
如果表达式解析为 null 或者指向一个不存在的字段,则 abs 的结果是 null。如果值解析为 NaN,则结果是 NaN
add将数字相加或将数字加在日期上。如果数组中的其中一个值是日期,那么其他值将被视为毫秒数加在该日期上
语法如下:
db.command.aggregate.add([<表达式1>, <表达式2>, ...])
表达式可以是形如 $ + 指定字段,也可以是普通字符串。只要能够被解析成字符串即可
ceil向上取整
db.command.aggregate.ceil()
divide传入被除数和除数,求商
db.command.aggregate.divide([<被除数表达式>, <除数表达式>])
exp求e的n次方
db.command.aggregate.exp()
floor向下取整
db.command.aggregate.floor()
ln取以e为底对数
db.command.aggregate.ln()
log取以任意值为底的对数
db.command.aggregate.log([, log10是取以10为底的对数
db.command.aggregate.log()
mod取数字取模后的值
db.command.aggregate.mod([, ])
multiply是得到数字相乘的结果
db.command.aggregate.multiply([, , ...])
pow是得到指定的次数幂
db.command.aggregate.pow([])
sqrt求平方根
db.command.aggregate.sqrt([])
substract将两个数字相减然后返回差值,或将两个日期相减然后返回相差的毫秒数,或将一个日期减去一个数字返回结果的日期
db.command.aggregate.subtract([, ])
trunc将数字截断为整形
db.command.aggregate.trunc()
数组操作符(arrayElemAt、arrayToObject、concatArrays、filter、in、indexOfArray、isArray、map、objectToArray、range、reduce、reverseArray、size、slice、zip)
arrayElemAt返回在指定数组下标的元素。
db.command.aggregate.arrayElemAt([, ])
arrayToObject把数组转换为对象
假设集合 shops 有如下记录:
{ "_id": 1, "sales": [ ["max", 100], ["min", 50] ] }
{ "_id": 2, "sales": [ ["max", 70], ["min", 60] ] }
{ "_id": 3, "sales": [ { "k": "max", "v": 50 }, { "k": "min", "v": 30 } ] }
求各个第一次考试的分数和和最后一次的分数:
const $ = db.command.aggregate
db.collection('shops').aggregate()
.project({
sales: $.arrayToObject('$sales'),
})
.end()
返回结果如下:
{ "_id": 1, "sales": { "max": 100, "min": 50 } }
{ "_id": 2, "sales": { "max": 70, "min": 60 } }
{ "_id": 3, "sales": { "max": 50, "min": 30 } }
concatArrays拼接数组
db.command.aggregate.arrayToObject([ , , ... ])
filter根据给定条件返回满足条件的数组的子集
db.command.aggregate.filter({
input: ,
as: ,
cond:
})
| 字段 | 说明 |
|---|---|
| input | 一个可以解析为数组的表达式 |
| as | 可选,用于表示数组各个元素的变量,默认为 this |
| cond | 一个可以解析为布尔值的表达式,用于判断各个元素是否满足条件,各个元素的名字由 as 参数决定(参数名需加 $$ 前缀,如 $$this |
in给定一个值和一个数组,如果值在数组中则返回 true,否则返回 false
db.command.aggregate.in([, ])
indexOfArray在数组中找出等于给定值的第一个元素的下标,如果找不到则返回 -1。
db.command.aggregate.indexOfArray([ , , , ])
isArray判断给定表达式是否是数组,返回布尔值
db.command.aggregate.isArray()
假设集合 stats 有如下记录:
{
"_id": 1,
"base": 10,
"sales": [ 1, 6, 2, 2, 5 ]
}
{
"_id": 2,
"base": 1,
"sales": 100
}
计算总销量,如果 sales 是数字,则求 sales * base,如果 sales 是数组,则求数组元素之和与 base 的乘积。
const $ = db.command.aggregate
db.collection('stats').aggregate()
.project({
sum: $.cond({
if: $.isArray('$sales'),
then: $.multiply([$.sum(['$sales']), '$base']),
else: $.multiply(['$sales', '$base']),
})
})
.end()
返回结果如下:
{ "_id": 1, "index": 160 }
{ "_id": 2, "index": 100 }
map类似 JavaScript Array 上的 map 方法,将给定数组的每个元素按给定转换方法转换后得出新的数组
db.command.aggregate.map({
input: ,
as: ,
in:
})
| 字段 | 说明 |
|---|---|
| input | 一个可以解析为数组的表达式 |
| as | 可选,用于表示数组各个元素的变量,默认为 this |
| in | 一个可以应用在给定数组的各个元素上的表达式,各个元素的名字由 as 参数决定(参数名需加 $$ 前缀,如 $$this) |
objectToArray将一个对象转换为数组。方法把对象的每个键值对都变成输出数组的一个元素,元素形如 { k:
db.command.aggregate.objectToArray(range返回一组生成的序列数字,按照步长递增。给定开始值、结束值、非零的步长,range 会返回从开始值开始逐步增长、步长为给定步长、但不包括结束值的序列。
reduce类似 JavaScript 的 reduce 方法,应用一个表达式于数组各个元素然后归一成一个元素
db.command.aggregate.reduce({
input:
initialValue: ,
in:
})
| 字段 | 说明 |
|---|---|
| input | 输入数组,可以是任意解析为数组的表达式 |
| initialValue | 初始值 |
| in | 用来作用于每个元素的表达式,在 in 中有两个可用变量,value 是表示累计值的变量,this是表示当前数组元素的变量 |
reverseArray反转数组
db.command.aggregate.reverseArray()
size返回数组的长度
db.command.aggregate.size()
slice类似 JavaScritp 的 slice 方法。返回给定数组的指定子集
语法有两种:
返回从开头或结尾开始的 n 个元素:
db.command.aggregate.slice([, ])
返回从指定位置算作数组开头、再向后或向前的 n 个元素:
db.command.aggregate.slice([, , ])
zip把二维数组的第二维数组中的相同序号的元素分别拼装成一个新的数组进而组装成一个新的二维数组,相当于转置二维数组
db.command.aggregate.zip({
inputs: [, , ...],
useLongestLength: ,
defaults:
})
布尔操作符(and、not、or)
and给定多个表达式,and 仅在所有表达式都返回 true 时返回 true,否则返回 false。
db.command.aggregate.and([, , ...])
not给定一个表达式,如果表达式返回 true,则 not 返回 false,否则返回 true。注意表达式不能为逻辑表达式(and、or、nor、not)。
db.command.aggregate.not()
or给定多个表达式,如果任意一个表达式返回 true,则 or 返回 true,否则返回 false
db.command.aggregate.or([, , ...])
比较操作符(cmp、eq、gt、gte、lt、lte、neq)
cmp如果第一个值小于第二个值,返回 -1 如果第一个值大于第二个值,返回 1 如果两个值相等,返回 0
db.command.aggregate.cmp([, ])
条件操作符(cond、ifNull、switch)
cond计算布尔表达式,返回指定的两个值其中之一
cond 的使用形式如下:
cond({ if: <布尔表达式>, then: <真值>, else: <假值> })
或者:
cond([ <布尔表达式>, <真值>, <假值> ])
两种形式中,三个参数(if、then、else)都是必须的
ifNull如果表达式结果为 null、undefined 或者不存在,那么返回一个替代值;否则返回原值。
ifNull([ <表达式>, <替代值> ])
switch根据给定的 switch-case-default 计算返回值
switch({
branches: [
case: <表达式>, then: <表达式>,
case: <表达式>, then: <表达式>,
...
],
default: <表达式>
})
日期操作符(dateFromParts、dateFromString、dateToString、dayOfMonth、dayOfweek、dayOfYear、hour、isoDayOfWeek、isoWeek、isoWeekYear、millisecond、minute、month、second、week、year、subtract)
日期对象比较复杂就不一一弄了orz,去上级目录找到网址去看例子比较合适
常量操作符(iteral)
iteral直接返回一个值的字面量,不经过任何解析和处理,通常用于解析带$的字符串
对象操作符(mergeObjects、objectToArray)
mergeObjects将多个文档合并为单个文档
使用形式如下: 在 group() 中使用时:
mergeObjects()
在其它表达式中使用时:
mergeObjects([, , ...])
objectToArray就是把对象转换成kv的对象数组
集合操作符(allElementsTrue、anyElementTrue、setDifference、setEquals、setIntersection、setIsSubset、setUnion)
allElementsTrue输入一个数组,或者数组字段的表达式。如果数组中所有元素均为真值,那么返回 true,否则返回 false。空数组永远返回 true。
allElementsTrue([])
anyElementTrue输入一个数组,或者数组字段的表达式。如果数组中任意一个元素为真值,那么返回 true,否则返回 false。空数组永远返回 false
anyElementTrue([])
setDifference输入两个集合,输出只存在于第一个集合中的元素,即A-B
setDifference([, ])
setEquals输入两个集合,判断两个集合中包含的元素是否完全相同(不考虑顺序、去重)
setEquals([, ])
setIntersection输入两个集合,输出两个集合的交集,即A∩B
setIntersection([, ])
setIsSubset输入两个集合,判断第一个集合是否是第二个集合的子集
setIsSubset([, ])
setUnion输入两个集合,输出两个集合的并集
setUnion([, ])
字符串操作符(concat、dateFromString、dateToString、indexOfBytes、indexOfCP、split、strLenBytes、strLenCP、strcasecmp、substr、substrBytes、substrCP、toLower、toUpper)
concat连接字符串,返回拼接后的字符串
db.command.aggregate.concat([<表达式1>, <表达式2>, ...])
表达式可以是形如 $ + 指定字段,也可以是普通字符串。只要能够被解析成字符串即可
dateFromString将一个日期/时间字符串转换为日期对象
db.command.aggregate.dateFromString({
dateString: ,
timezone:
})
dateToString根据指定的表达式将日期对象格式化为符合要求的字符串
dateToString 的调用形式如下:
db.command.aggregate.dateToString({
date: <日期表达式>,
format: <格式化表达式>,
timezone: <时区表达式>,
onNull: <空值表达式>
})
下面是四种表达式的详细说明:
| 名称 | 描述 |
|---|---|
| 日期表达式 | 必选。指定字段值应该是能转化为字符串的日期。 |
| 格式化表达式 | 可选。它可以是任何包含“格式说明符”的有效字符串。 |
| 时区表达式 | 可选。指明运算结果的时区。它可以解析格式为 UTC Offset 或者 Olson Timezone Identifier 的字符串。 |
| 空值表达式 | 可选。当 <日期表达式> 返回空或者不存在的时候,会返回此表达式指明的值。 |
下面是格式说明符的详细说明:
| 说明符 | 描述 | 合法值 |
|---|---|---|
| %d | 月份的日期(2位数,0填充) | 01 - 31 |
| %G | ISO 8601 格式的年份 | 0000 - 9999 |
| %H | 小时(2位数,0填充,24小时制) | 00 - 23 |
| %j | 一年中的一天(3位数,0填充) | 001 - 366 |
| %L | 毫秒(3位数,0填充) | 000 - 999 |
| %m | 月份(2位数,0填充) | 01 - 12 |
| %M | 分钟(2位数,0填充) | 00 - 59 |
| %S | 秒(2位数,0填充) | 00 - 60 |
| %w | 星期几 | 1 - 7 |
| %u | ISO 8601 格式的星期几 | 1 - 7 |
| %U | 一年中的一周(2位数,0填充) | 00 - 53 |
| %V | ISO 8601 格式的一年中的一周 | 1 - 53 |
| %Y | 年份(4位数,0填充) | 0000 - 9999 |
| %z | 与 UTC 的时区偏移量 | +/-[hh][mm] |
| %Z | 以分钟为单位,与 UTC 的时区偏移量 | +/-mmm |
| %% | 百分号作为字符 | % |
indexOfBytes在目标字符串中查找子字符串,并返回第一次出现的 UTF-8 的字节索引(从0开始)。如果不存在子字符串,返回 -1
db.command.aggregate.indexOfBytes([<目标字符串表达式>, <子字符串表达式>, <开始位置表达式>, <结束位置表达式>])
下面是 4 种表达式的详细描述:
| 表达式 | 描述 |
|---|---|
| 目标字符串表达式 | 任何可以被解析为字符串的表达式 |
| 子字符串表达式 | 任何可以被解析为字符串的表达式 |
| 开始位置表达式 | 任何可以被解析为非负整数的表达式 |
| 结束位置表达式 | 任何可以被解析为非负整数的表达式 |
indexOfCP在目标字符串中查找子字符串,并返回第一次出现的 UTF-8 的 code point 索引(从0开始)。如果不存在子字符串,返回 -1。code point 是“码位”,又名“编码位置”。这里特指 Unicode 包中的码位,范围是从0(16进制)到10FFFF(16进制)。
split。按照分隔符分隔数组,并且删除分隔符,返回子字符串组成的数组。如果字符串无法找到分隔符进行分隔,返回原字符串作为数组的唯一元素。
db.command.aggregate.split([<字符串表达式>, <分隔符表达式>])
strLenBytes计算并返回指定字符串中 utf-8 编码的字节数量
db.command.aggregate.strLenBytes(<表达式>)
strLenCp计算并返回指定字符串的UTF-8 code points 数量,即字符数量
db.command.aggregate.strLenCP(<表达式>)
strcasecmp对两个字符串在不区分大小写的情况下进行大小比较,并返回比较的结果
db.command.aggregate.strcasecmp([<表达式1>, <表达式2>])
substr返回字符串从指定位置开始的指定长度的子字符串。它是 db.command.aggregate.substrBytes 的别名,更推荐使用后者
db.command.aggregate.substr([<表达式1>, <表达式2>, <表达式3>])
substrBytes返回字符串从指定位置开始的指定长度的子字符串。子字符串是由字符串中指定的 UTF-8 字节索引的字符开始,长度为指定的字节数
db.command.aggregate.substrBytes([<表达式1>, <表达式2>, <表达式3>])
substrCP返回字符串从指定位置开始的指定长度的子字符串。子字符串是由字符串中指定的 UTF-8 字节索引的字符开始,长度为指定的字节数
db.command.aggregate.substrCP([<表达式1>, <表达式2>, <表达式3>])
toLower将字符串转化为小写并返回
db.command.aggregate.toLower(表达式)
toUpper将字符串转化为大写并返回。
db.command.aggregate.toUpper(表达式)
累计器操作符(addToSet、avg、first、last、max、min、push、stdDevPop、stdDevSamp、sum)
addToSet向数组中添加值,如果数组中已存在该值,不执行任何操作。它只能在 group stage 中使用
db.command.aggregate.addToSet(<表达式>)
avg返回一组集合中,指定字段对应数据的平均值
db.command.aggregate.avg(<number>)
first返回指定字段在一组集合的第一条记录对应的值。仅当这组集合是按照某种定义排序( sort )后,此操作才有意义。只能在 group 阶段被使用
db.command.aggregate.first(<表达式>)
last返回指定字段在一组集合的最后一条记录对应的值。仅当这组集合是按照某种定义排序( sort )后,此操作才有意义。只能在 group 阶段被使用
db.command.aggregate.last(<表达式>)
max返回一组数值的最大值
db.command.aggregate.max(<表达式>)
min返回一组数值的最小值
b.command.aggregate.min(<表达式>)
push在 group 阶段,返回一组中表达式指定列与对应的值,一起组成的数组
db.command.aggregate.push({
<字段名1>: <指定字段1>,
<字段名2>: <指定字段2>,
...
})
stdDevPop返回一组数据的标准差,输入的表达式必须返回number
db.command.aggregate.stdDevPop(<表达式>)
stdDevSamp计算输入值的样本标准偏差。如果输入值代表数据总体,或者不概括更多的数据,请改用 db.command.aggregate.stdDevPop。stdDevSamp会自动忽略非数字值。如果指定字段所有的值均是非数字,那么结果返回null
db.command.aggregate.stdDevSamp(<表达式>)
sum计算并且返回一组字段所有数值的总和
db.command.aggregate.sum(<表达式>)
变量操作符(let)
let自定义变量,并且在指定表达式中使用,返回的结果是表达式的结果
db.command.aggregate.let({
vars: {
<变量1>: <变量表达式>,
<变量2>: <变量表达式>,
...
},
in: <结果表达式>
})
vars 中可以定义多个变量,变量的值由 变量表达式 计算而来,并且被定义的变量只有在 in 中的 结果表达式 才可以访问。
在 in 的结果表达式中访问自定义变量时候,请在变量名前加上双美元符号( $$ )并用引号括起来。