【超详细】从VMware安装到Hadoop+Hbase完全分布式搭建到音乐排行榜综合实验
目录
一、VMware安装
二、VMwareTools安装
三、更新apt
四、安装配置SSH
五、安装JAVA环境
六、Hadoop安装
七、克隆一台slave
八、修改主机名和测试连通
九、SSH无密码登录Slave
十、配置集群/分布式环境
十一、Hbase的安装与配置
十二、MapReduce与Hbase集成环境
十三、Eclipse安装与配置
十四、音乐排行榜综合实验
一、VMware安装
注意:如果选择的系统是64位Ubuntu系统,那么在安装虚拟机前,我们还要进入BIOS开启CPU的虚拟化

VMware Workstation安装
双击![]() ,选择安装目录,一路next,即可完成。
,选择安装目录,一路next,即可完成。
双击桌面上的图标 ,然后输入产品序列号。
,然后输入产品序列号。
配置Vmware
安装好VMware,打开VMware主界面,点击”创建新的虚拟机”

选择”典型”然后下一步
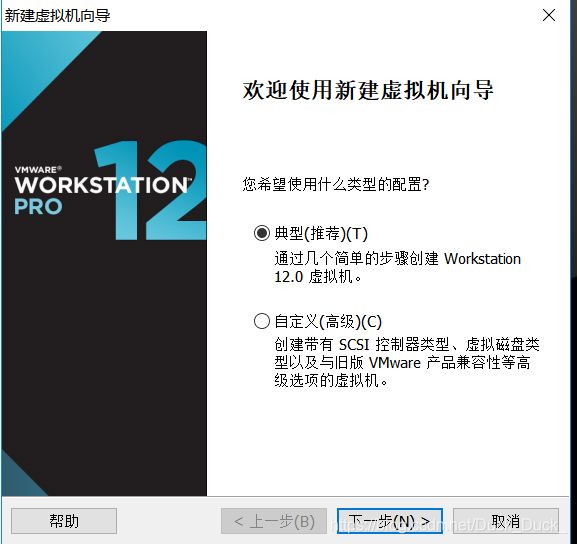
直接下一步
稍后安装操作系统
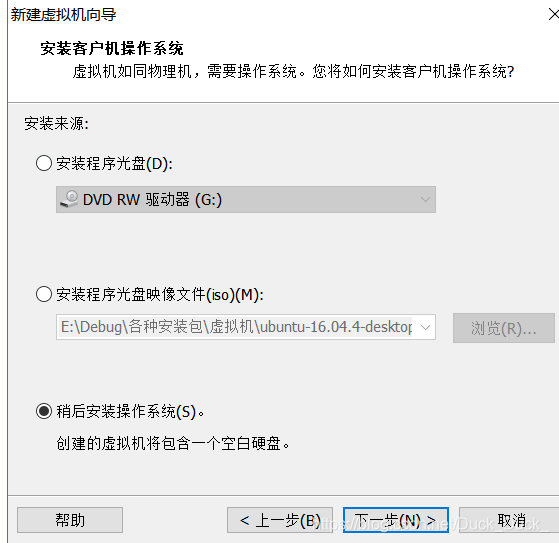
选择”Linux”系统,版本选择”Ubuntu 64位”
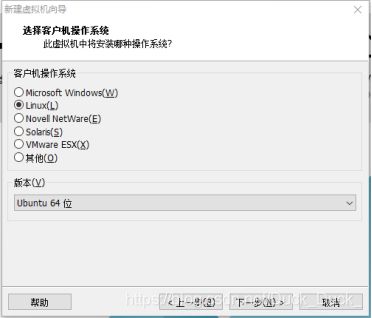
选择合适的位置安装
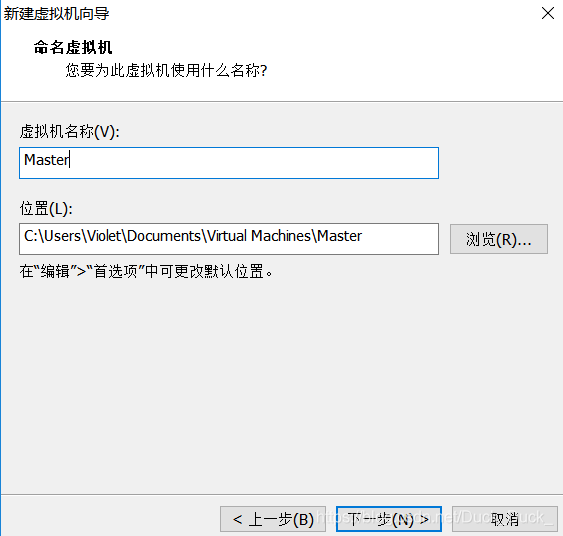
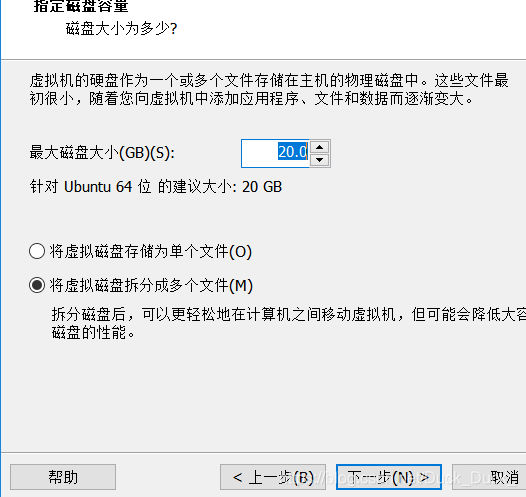
自定义硬件
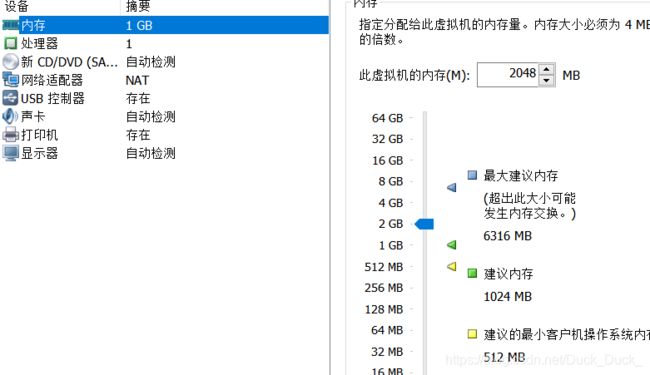
内存分配2GB
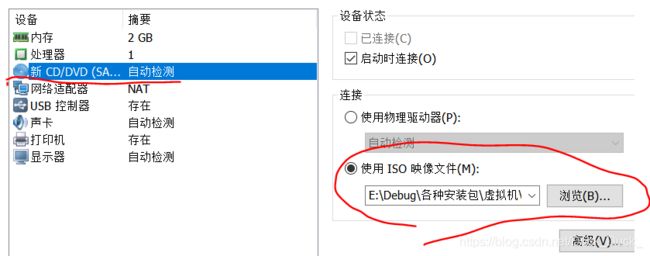
选择完ISO映像文件后,点“关闭”,最后点击“完成”。
二、VMwareTools安装

点击“虚拟机”,点击“安装VMware tool”。
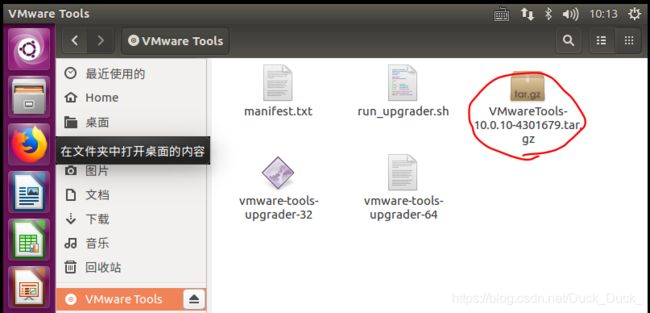
将圈出来的这个安装包复制到home下,并解压(用命令(tar zxvf VMwareTools-10.0.10-4301679.tar.gz)或者右键解压都行,下划线处为自己的包名,可能会不同)。
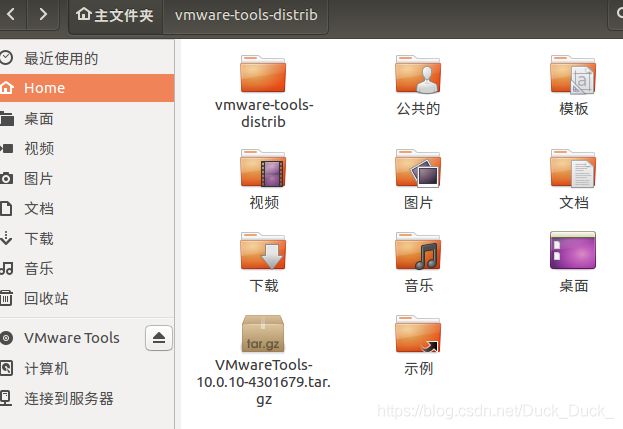
如图,可得到文件夹vmware-tools-distrib
![]()
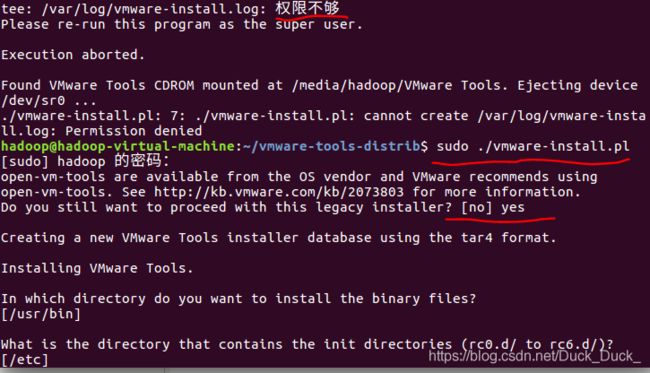
后面就一路回车。直到他跳出:

至此,安装完毕,重新启动虚拟机。重启后才能生效。
三、更新apt
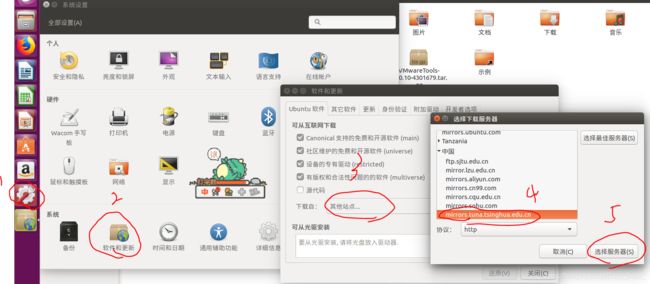
选择服务器后,会让你授权,就输入一下密码。
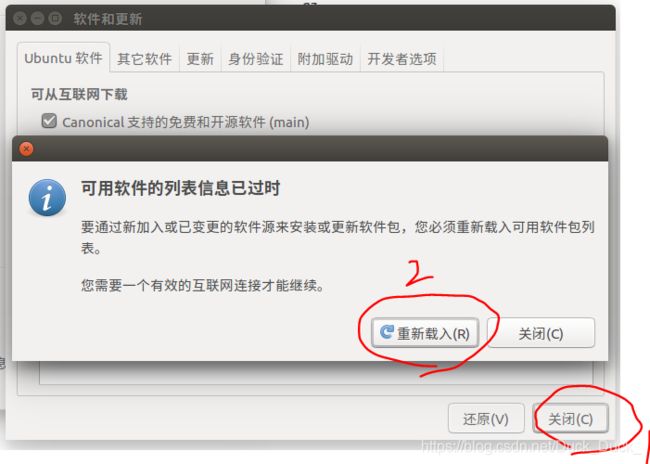
然后点击“关闭,会弹出上面的弹窗,点击“重新载入”。
等他更新完,ctrl+Alt+t快捷键打开终端。
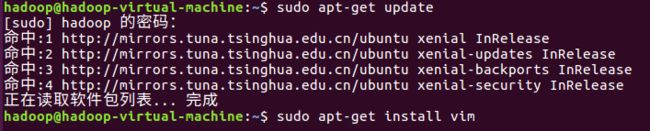
sudo apt-get update
sudo apt-get install vim 顺带手装个vim,vi的增强版。

会问“您希望继续执行吗?”打个Y就行,然后开始安装,等。
四、安装配置SSH
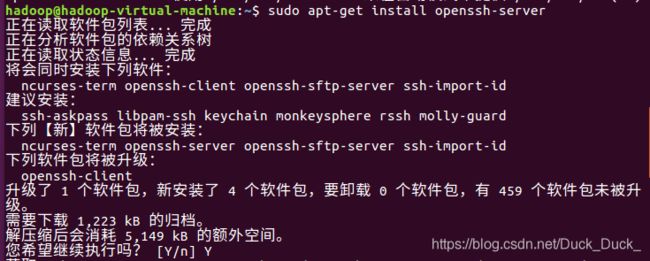
sudo apt-get install openssh-server
ssh localhost

exit # 退出刚才的 ssh localhost

cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
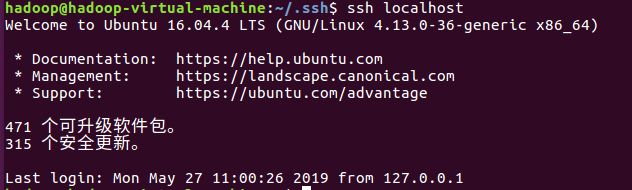
再次ssh localhost,就会发现直接登录,无需密码。
五、安装JAVA环境
创建一个目录,用于放置JDk:sudo mkdir –p /usr/lib/jvm
将jdk的包解压到上述目录:sudo tar zxvf jdk-8u101-linux-x64.tar.gz -C /usr/lib/jvm

配置环境变量,输入命令:vim ~/.bashrc
打开文件后,按i键,将光标移动最后面添加以下内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_101
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:{JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH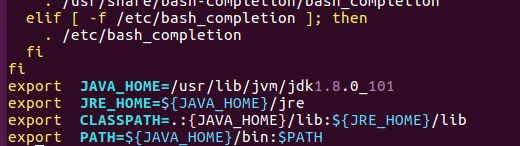
按下Esc键,取消输入,“:wq”,保存并退出。
使配置生效:source ~/.bashrc
验证是否成功:java -version

六、Hadoop安装

sudo tar zxvf hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限验证hadoop安装是否正确:

cd /usr/local/hadoop
./bin/hadoop version
配置hadoop环境:
vim ~/.bashrc
在文件最末尾插入:

保存退出。

使之生效。
cd /usr/local/hadoop/etc/hadoop
找到hadoop-env.sh,打开

将这里,修改为具体的Java路径:
/usr/lib/jvm/jdk1.8.0_101

七、克隆一台slave
首先,将master关机,因为运行中和挂起状态无法克隆。
然后在左边栏中,找到Master,右键,管理,克隆。就会出现如上图弹框。
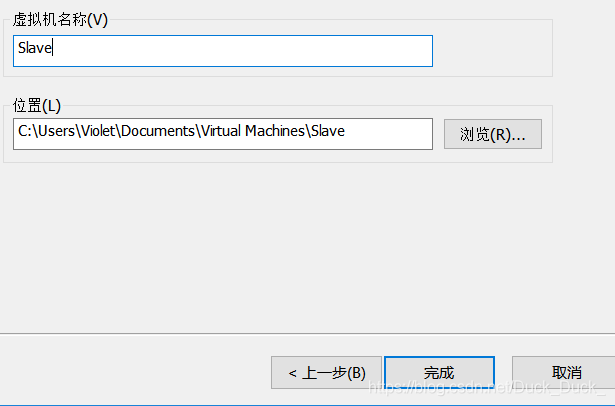
完成。等他完成克隆。
八、修改主机名和测试连通
![]()
sudo vim /etc/hostname 两台都要改,一台是Master一台是Slave
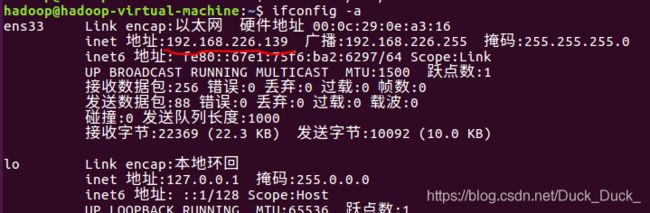
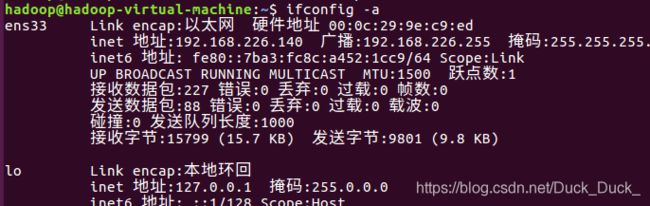
查看Master和slave的IP地址:(我这里一个是192.168.226.139另一个是192.168.226.140)
修改IP映射(也是Master和Slave都要改,但内容相同)
![]()
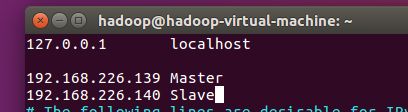
改完之后,重启生效。
配置好后需要在各个节点上执行如下命令,测试是否相互 ping 得通,如果 ping 不通,后面就无法顺利配置成功:
ping Master -c 3 # 只ping 3次,否则要按 Ctrl+c 中断
ping Slave -c 3
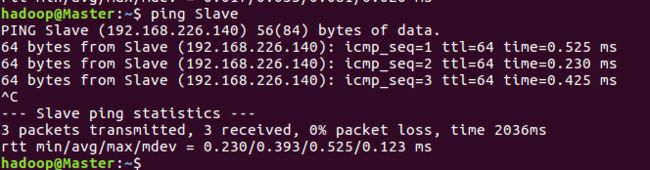
如上图,主机名已经改变,且能ping通。
九、SSH无密码登录Slave
下述操作均在Master终端:
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回车就可以
cat ./id_rsa.pub >> ./authorized_keys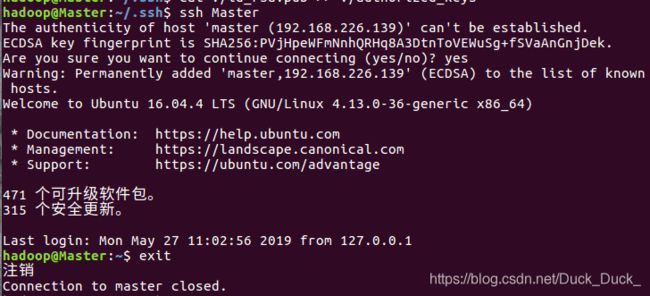
完成后ssh Master验证一下,验证完exit退出。
将公钥传到Slave:scp ~/.ssh/id_rsa.pub hadoop@Slave:/home/hadoop/

再去Slave节点终端:
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完就可以删掉了
回到Master节点,测试是否能够免密登录:ssh Slave

验证完后exit退出,回到Master。
十、配置集群/分布式环境
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1.文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
本教程让 Master 节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,只添加一行内容:Slave。
2, 文件 core-site.xml 改为下面的配置:
fs.defaultFS
hdfs://Master:9000
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
3, 文件 hdfs-site.xml,dfs.replication 一般设为 3,但我们只有一个 Slave 节点,所以 dfs.replication 的值还是设为 1:
dfs.namenode.secondary.http-address
Master:50090
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
4, 文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
Master:10020
mapreduce.jobhistory.webapp.address
Master:19888
5, 文件 yarn-site.xml:
yarn.resourcemanager.hostname
Master
yarn.nodemanager.aux-services
mapreduce_shuffle
配置好后,将 Master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。在 Master 节点上执行:
cd /usr/local
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz Slave:/home/hadoop![]()
![]()
![]()
在 Slave节点上执行:
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop![]()
![]()
同样,如果有其他 Slave 节点,也要执行将 hadoop.master.tar.gz 传输到 Slave 节点、在 Slave 节点解压文件的操作。
首次启动需要先在 Master 节点执行 NameNode 的格式化:
hdfs namenode -format # 首次运行需要执行初始化,之后不需要
接着可以启动 hadoop 了,启动需要在 Master 节点上进行:
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:

在 Slave 节点可以看到 DataNode 和 NodeManager 进程,如下图所示:

在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有 1 个 Datanodes:
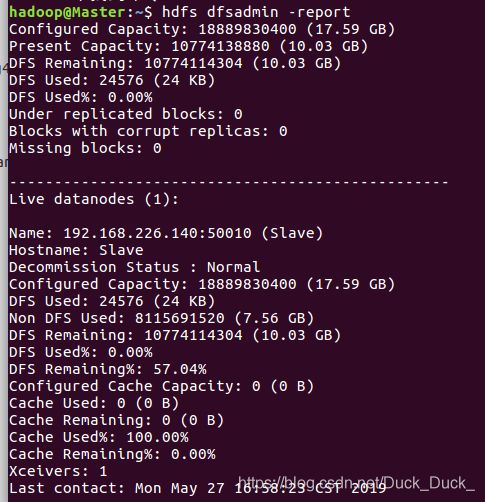
也可以通过 Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/。如果不成功,可以通过启动日志排查原因。
执行分布式实例过程与伪分布式模式一样,首先创建 HDFS 上的用户目录:
hdfs dfs -mkdir -p /user/hadoop
关闭 Hadoop 集群也是在 Master 节点上执行的:
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver此外,同伪分布式一样,也可以不启动 YARN,但要记得改掉 mapred-site.xml 的文件名。
十一、Hbase的安装与配置
解压:
sudo tar zxvf hbase-1.2.3-bin.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hbase-1.2.3/ ./hbase
sudo chown -R hadoop ./hbase ![]()
若出现如上错误,自己手打一遍,可能是复制的问题。
验证一下:

配置hbase环境:
vim ~/.bashrc
在文件最末尾插入:
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin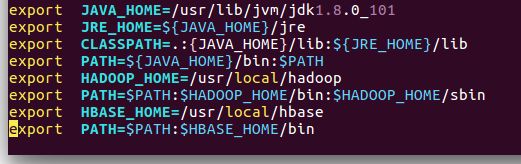
使之生效:source ~/.bashrc
进入hbase的安装目录 /usr/local/hbase/conf
找到regionservers
修改如图:
找到hbase-site.xml,右键gedit打开,加入:
hbase.rootdir
hdfs://master:9000/hbase
HBase Data storge directory
hbase.cluster.distributed
true
Assign HBase run mode
hbase.master
hdfs://master:60000
Assign Master position
hbase.zookeeper.quorum
Master,Slave
Assign Zookeeper cluster
配置/usr/local/hbase/conf/hbase-env.sh。
cd /usr/local/hbase/conf/打开配置文件hbase-env.sh
vim hbase-env.sh在最后面添加以下内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_101
export HADOOP_HOME=/usr/local/hadoop
export HBASE_HOME=/usr/local/hbase
export HBASE_MANAGES_ZK=true至此,在Master节点上的Hbase配置完成,现在要将配置传给Slave
cd /usr/local
tar -zcf ~/hbase.master.tar.gz ./hbase
cd ~
scp ./hbase.master.tar.gz Slave:/home/hadoop
在 Slave节点上执行:
sudo tar -zxf ~/hbase.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hbasevim ~/.bashrc
在文件最末尾插入:
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
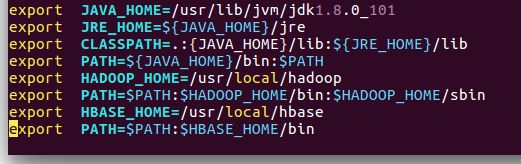
使之生效:source ~/.bashrc
启动Hbase:start-hbase.sh

查看jps:
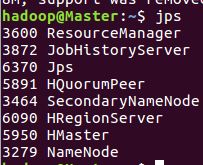

验证:hbase shell
至此,Hbase配置结束。
十二、MapReduce与Hbase集成环境
(1)将hbase-site.xml复制到$HADOOP_HOME/etc/hadoop下。
(2)编辑$HADOOP_HOME/etc/hadoop/hadoop-env.sh,增加一行:
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/usr/local/hbase/lib/*(3)验证配置:
创建一张表:
create 'score','name','sex'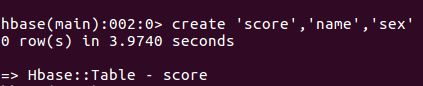
hadoop jar /usr/local/hbase/lib/hbase-server-1.2.3.jar rowcounter score报错如下: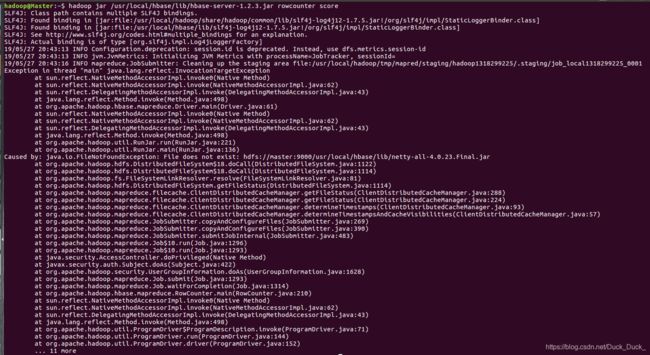
解决方法如下:将需要的jar包都上传到hdfs。
hdfs dfs -mkdir -p hdfs://master:9000/usr/local/hadoop/share/hadoop
hdfs dfs -put /usr/local/hadoop/share/hadoop hdfs://master:9000/usr/local/hadoop/share/
hdfs dfs -mkdir -p hdfs://master:9000/usr/local/hbase/lib
hdfs dfs -put /usr/local/hbase/lib hdfs://master:9000/usr/local/hbase/lib再一次:hadoop jar /usr/local/hbase/lib/hbase-server-1.2.3.jar rowcounter score
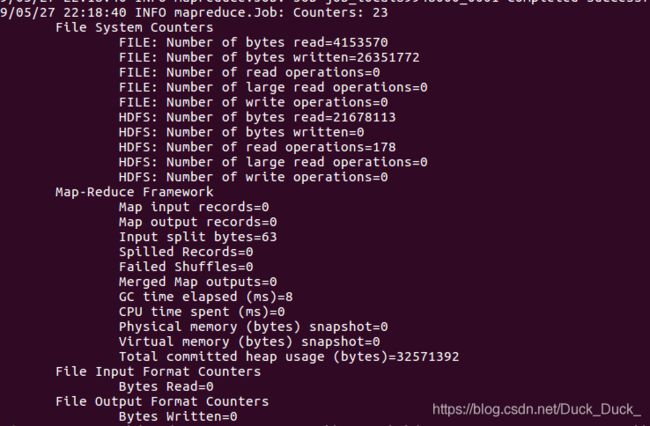
以上。配置完成。
十三、Eclipse安装与配置
(一)安装eclipse
打开终端,输入命令:sudo apt-get install eclipse
系统开始安装eclipse,过程会比较长,请耐心等待。
安装完毕,输入以下命令,观察eclipse的安装情况:whereis eclipse
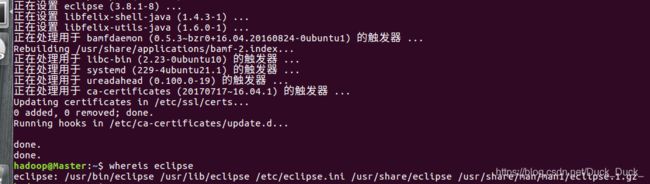
说明:
/usr/bin/eclipse 启动的shell脚本
/usr/lib/eclipse 系统文件
/usr/share/eclipse 共享的系统文件
/etc/eclipse.ini 配置文件
运行eclipse,验证能否正常使用。输入命令:eclipse

(二)安装Hadoop-Eclipse-Plugin
在终端输入命令,将hadoop插件包解压(注意红色标注的hadoop指用户名)
unzip -qo hadoop2x-eclipse-plugin-master.zip -d /home/hadoop/
![]()
输入命令:sudo cp ~/hadoop2x-eclipse-plugin-master/release/hadoop-eclipse-plugin-2.6.0.jar /usr/lib/eclipse/plugins/
![]()
输入命令:/usr/lib/eclipse/eclipse -clean,将启动eclipse。
(三)配置Hadoop-Eclipse-Plugin
在继续配置前请确保已经开启了Hadoop。
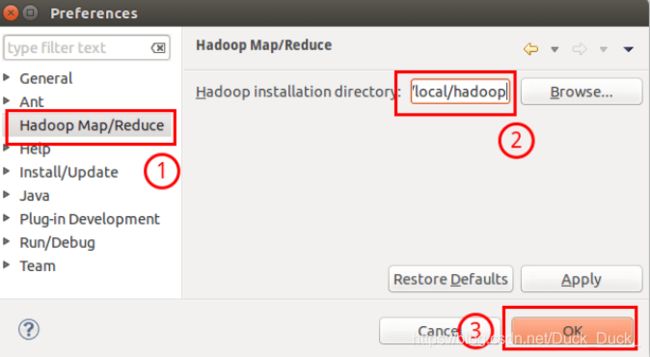
在打开的eclipse中,选择 Window 菜单下的 Preference。

此时会弹出一个窗体,窗体的左侧会多出Hadoop Map/Reduce 选项,点击此选项,选择Hadoop的安装目录(/usr/local/hadoop)。
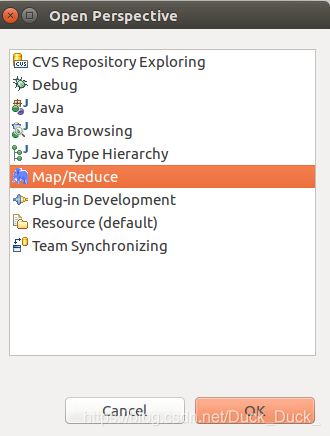
切换 Map/Reduce 开发视图:选择 Window 菜单下选择 Open Perspective -> Other,弹出一个窗体,从中选择 Map/Reduce 选项即可进行切换。
建立与Hadoop集群的连接:点击 Eclipse软件右下角的 Map/Reduce Locations 面板,在面板中单击右键,选择 New Hadoop Location。
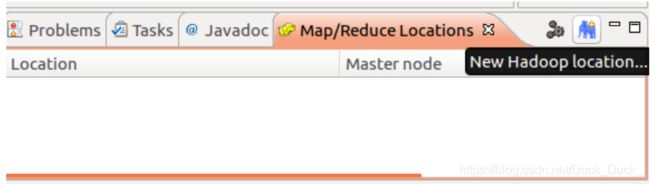
在弹出的界面中进行设置:
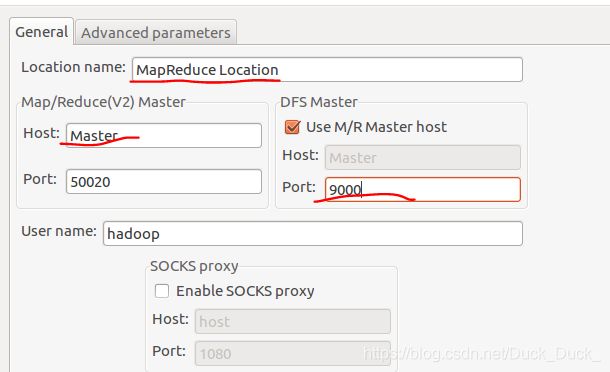
单击“finish ”按钮,可以看到HDFS的文件结构了,至此eclipse的配置就完成。

十四、音乐排行榜综合实验
hdfs dfs -mkdir -p /user/hadoop/input2/music2
hdfs dfs -put /home/hadoop/music1.txt /user/hadoop/input2/music2
hdfs dfs -put /home/hadoop/music2.txt /user/hadoop/input2/music2
hdfs dfs -put /home/hadoop/music3.txt /user/hadoop/input2/music2
hadoop jar /usr/local/hbase/lib/hbase-server-1.2.3.jar importtsv -D importtsv.bulk.output=tmp -D importtsv.columns=HBASE_ROW_KEY,info:name,info:singer,info:gender,info:ryghme,info:terminal music /input2/music2
hadoop jar /usr/local/hbase/lib/hbase-server-1.2.3.jar completebuLkload tmp music![]()
进入hbase shell,查看数据导入情况。
scan 'music'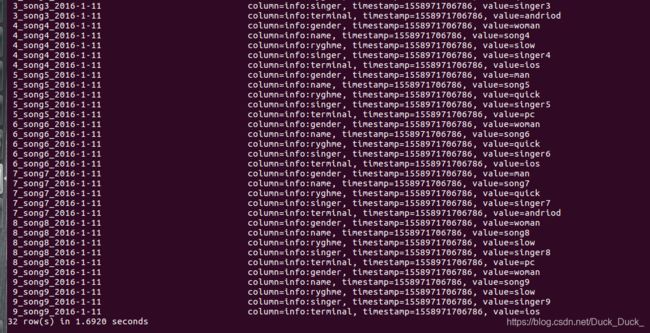
TableMapper API的使用:
前期准备:
create 'namelist','details'新建一个Project。

选择“Map/Reduce Project”。
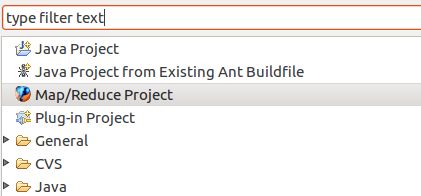
Project name随便取,最好能说明这个项目的作用。

在JRE System Library上右键,选中Properties。
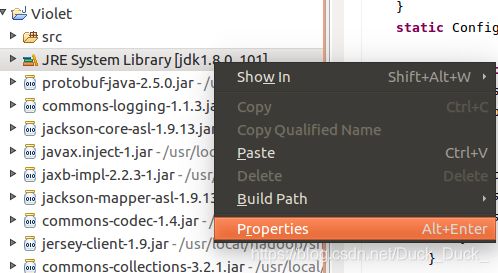
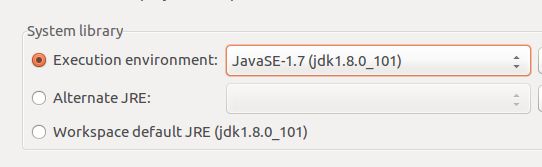
选择如下:
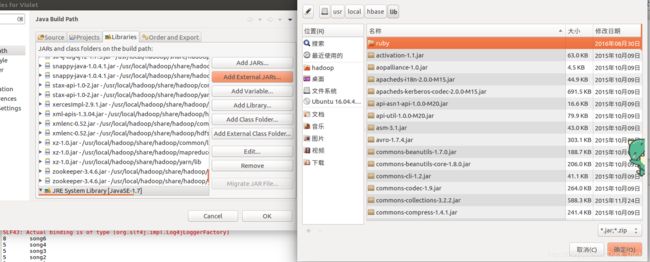
上面就导入了hadoop的jar包,还需要hbase的jar包,所以需要下列操作。

这里点击“Add External JARs”,找到hbase的安装目录,进入lib文件夹,选中全部jar包,按确定,导入。
新建Class。
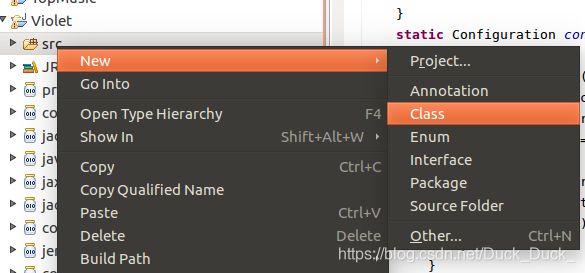
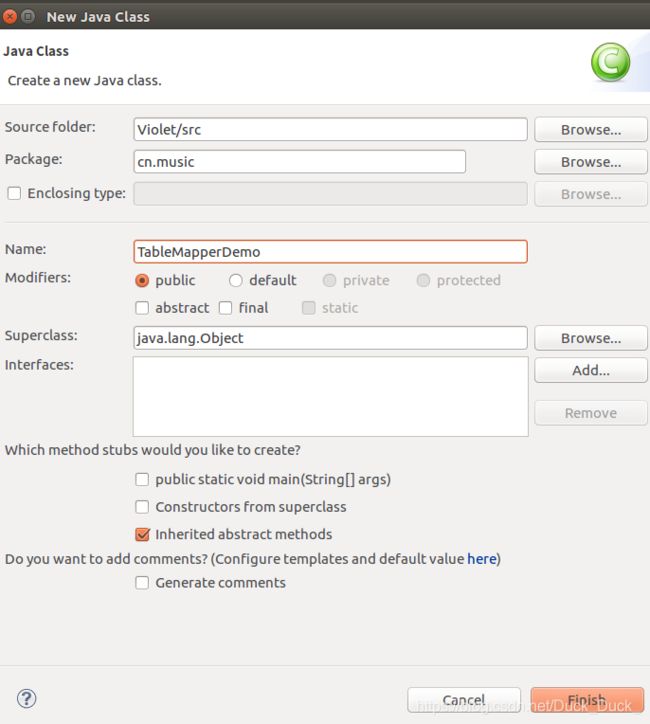
附上MapperDemo,ReducerDemo和最终版的TopMusic的代码:
TableMapperDemo.java
package cn.music;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.GenericOptionsParser;
public class TableMapperDemo {
static class MyMapper extends TableMapper {
@Override
protected void map(ImmutableBytesWritable key, Result value,
Context context) throws IOException, InterruptedException {
List| cells = value.listCells();
for (Cell cell : cells) {
Put put = new Put(CellUtil.cloneValue(cell));
//details:rank=0
put.addColumn(Bytes.toBytes("details"), Bytes.toBytes("rank"),
Bytes.toBytes(0));
context.write(new Text(Bytes.toString(CellUtil.cloneValue(cell))),put);
}
}
}
private static void m3(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = HBaseConfiguration.create();
GenericOptionsParser gop = new GenericOptionsParser(conf, args);
Job job = Job.getInstance(conf, "hbase-mapreduce-api");
// MapReduce程序作业基本配置
job.setJarByClass(TableMapperDemo.class);
job.setOutputFormatClass(TableOutputFormat.class);
// create 'clicklist','rank'
job.getConfiguration().set(TableOutputFormat.OUTPUT_TABLE, "namelist");
// 使用hbase提供的工具类来设置job
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
TableMapReduceUtil.initTableMapperJob("music", scan, MyMapper.class,
Text.class, Put.class, job);
job.waitForCompletion(true);
}
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
m3(args);// 使用TableMapper+TableMapReduceUtil+TableOutputFormat
}
}
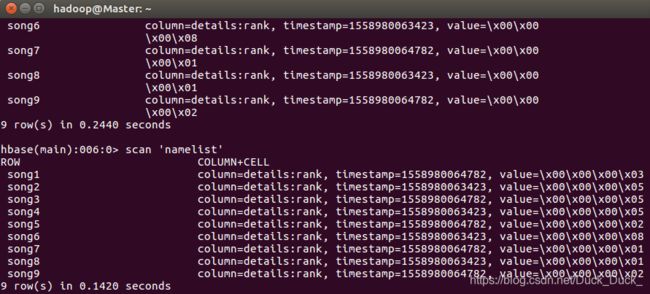
| 去hbase shell下查看结果。

TableReduceDemo.java
package cn.music;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.GenericOptionsParser;
public class TableReduceDemo {
static class MyMapper extends TableMapper {
@Override
protected void map(ImmutableBytesWritable key, Result value,
Context context) throws IOException, InterruptedException {
// 取出每行中的所有单元,实际上只扫描了一列(info:name)
List cells = value.listCells();
for (Cell cell : cells) {
context.write(
new Text(Bytes.toString(CellUtil.cloneValue(cell))),
new IntWritable(1));
}
}
}
static class MyReducer extends TableReducer {
@Override
protected void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int playCount = 0;
for (IntWritable num : values) {
playCount += num.get();
}
//为Put操作指定行键
Put put = new Put(Bytes.toBytes(key.toString()));
//为Put操作指定列和值
put.addColumn(Bytes.toBytes("details"), Bytes.toBytes("rank"),
Bytes.toBytes(playCount));
context.write(key, put);
}
}
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = HBaseConfiguration.create();
GenericOptionsParser gop = new GenericOptionsParser(conf, args);
Job job = Job.getInstance(conf, "top-music");
// MapReduce程序作业基本配置
job.setJarByClass(TableReduceDemo.class);
job.setNumReduceTasks(2);
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
// 使用hbase提供的工具类来设置job
TableMapReduceUtil.initTableMapperJob("music", scan, MyMapper.class,
Text.class, IntWritable.class, job);
TableMapReduceUtil.initTableReducerJob("namelist", MyReducer.class, job);
job.waitForCompletion(true);
}
}
| 
TopMusic.java
package cn.music;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class TopMusic {
static final String TABLE_MUSIC = "music";
static final String TABLE_NAMELIST = "namelist";
static final String OUTPUT_PATH = "topmusic";
/**
* 扫描每一行数据中的列info:name
*/
static class ScanMusicMapper extends TableMapper {
@Override
protected void map(ImmutableBytesWritable key, Result value,
Context context) throws IOException, InterruptedException {
List cells = value.listCells();
for (Cell cell : cells) {
if (Bytes.toString(CellUtil.cloneFamily(cell)).equals("info")&&
Bytes.toString(CellUtil.cloneQualifier(cell)).equals("name")) {
context.write(
new Text(Bytes.toString(CellUtil.cloneValue(cell))),
new IntWritable(1));
}
}
}
}
/**
* 汇总每首歌曲播放总次数
*/
static class IntNumReducer extends TableReducer {
@Override
protected void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int playCount = 0;
for (IntWritable num : values) {
playCount += num.get();
}
// 为Put操作指定行键
Put put = new Put(Bytes.toBytes(key.toString()));
// 为Put操作指定列和值
put.addColumn(Bytes.toBytes("details"), Bytes.toBytes("rank"),
Bytes.toBytes(playCount));
context.write(key, put);
}
}
/**
* 扫描全部歌曲名称并获得每首歌曲被播放次数.输出键/值:播放次数/歌名,输出目的地:HDSF文件
*/
static class ScanMusicNameMapper extends TableMapper {
@Override
protected void map(ImmutableBytesWritable key, Result value,
Context context) throws IOException, InterruptedException {
List| cells = value.listCells();
for (Cell cell : cells) {
context.write(
new IntWritable(Bytes.toInt(CellUtil.cloneValue(cell))),
new Text(Bytes.toString(key.get())));
}
}
}
/**
* 实现降序
*/
private static class IntWritableDecreaseingComparator extends
IntWritable.Comparator {
@Override
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);// 比较结果取负数即可降序
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
/**
* 配置作业:播放统计
*/
static boolean musicCount(String[] args)
throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(conf, "music-count");
// MapReduce程序作业基本配置
job.setJarByClass(TopMusic.class);
job.setNumReduceTasks(2);
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
// 使用hbase提供的工具类来设置job
TableMapReduceUtil.initTableMapperJob(TABLE_MUSIC, scan,
ScanMusicMapper.class, Text.class, IntWritable.class, job);
TableMapReduceUtil.initTableReducerJob(TABLE_NAMELIST,
IntNumReducer.class, job);
return job.waitForCompletion(true);
}
///////////////////////////////////////////////////////////////////////
/**
* 配置作业:排序
*/
static boolean sortMusic(String[] args)
throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(conf, "sort-music");
job.setJarByClass(TopMusic.class);
job.setNumReduceTasks(1);
job.setSortComparatorClass(IntWritableDecreaseingComparator.class);
TableMapReduceUtil.initTableMapperJob(TABLE_NAMELIST, new Scan(),
ScanMusicNameMapper.class, IntWritable.class, Text.class, job);
Path output = new Path(OUTPUT_PATH);
if (FileSystem.get(conf).exists(output))
FileSystem.get(conf).delete(output, true);
FileOutputFormat.setOutputPath(job, output);
return job.waitForCompletion(true);
}
/**
* 查看输出文件
*/
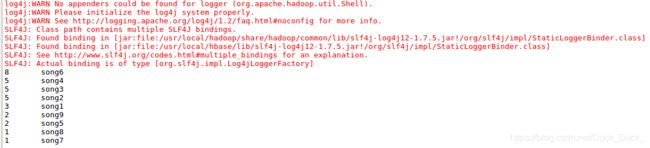
static void showResult() throws IllegalArgumentException, IOException{
FileSystem fs = FileSystem.get(conf);
InputStream in = null;
try {
in = fs.open(new Path(OUTPUT_PATH+"/part-r-00000"));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
static Configuration conf = HBaseConfiguration.create();
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
GenericOptionsParser gop = new GenericOptionsParser(conf, args);
String[] otherArgs = gop.getRemainingArgs();
if (musicCount(otherArgs)) {
if (sortMusic(otherArgs)) {
showResult();
}
}
}
}
| | 
这样就全部完成啦~一些理论知识我这里没有写的很详细,参考书目是《基于Hadoop与Spark的开发实战》肖睿等。
PS.有些问题,自己手打一遍命令或许就能解决~我用eclipse中出现过一次报错信息中含有callTimeout=60000, callDuration=69082: row 'music,,00000000000000' on table 'hbase:meta' at region=hbase:meta,,1.1588230740, hostname=slave,16020,15的问题,调出命令行jps,正常,进入hbase shell,正常,输入list发现:ERROR: Can't get master address from ZooKeeper; znode data == null。我stop了hbase再重新start了一下,就ok了。
以上。