引子:如下图是一张非常寻常的表格,在以前的工作中实常会制作类似的表格,但是今天的数据库内容,将我之前这种传统的制表思路上升了一个层次;
今天核心的内容就是怎样让表与表之间产生关系,在思考这个问题的时候,我们可以回顾之前学习python时,当一个任务涉及到很多的功能时,我们为了
让程序的结构更清晰,扩展性更高,我们选择用函数>>模块>>包 的方式将功能层层拆分,最终让程序结构上升到新的层次,而且极大的降低了代码的冗
余。再回到这张表,如果说总共就这几个人,这张表没什么问题,但是假设我们拥有100w的用户,此时表中的 def_name,dep_desc就有些冗余了;此外
这种表的形式也非常不利于后期数据的取值和修改。

实现思路:把内容多出现重复的字段拎出来制作成具有id的新表,将两张表建立联系。
| 一对多 |
第一步 拆分表

第二步 建立关联(通过dep_id字段链接两张表)
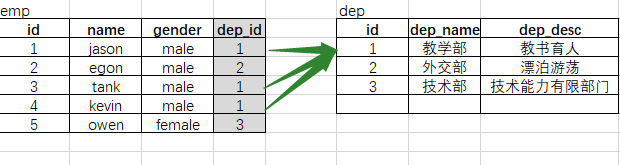
| 注意:1.必选要先建被关联表; 2.新增数据的时候,要先增被关联表中的数据; |
create table dep( id int primary key auto_increment, # id设置为主建,自增 dep_name char(16), dep_desc char(64) # 注意最后一个括号后面一定不要加逗号! ); create table emp( id int primary key auto_increment, name char(16), gender enum('male','female','others') not null default 'male', # default后面的默认值空格直接书写即可 dep_id int, foreign key(dep_id) references dep(id) # 外键 本表中的dep_id 字段 ,关联dep表中的id字段; );
插入数据
2.新增数据的时候,要先增被关联表中的数据
insert into dep(dep_name,dep_desc) values
('外交部','形象代言人'),
('教学部','教书育人'),
('技术部','技术能力有限部门');
insert into emp(name,gender,dep_id) values
('jason','male',1),
('egon','male',2),
('kevin','male',2),
('tank','male',2),
('jerry','female',3);
修改dep_id 数据
update emp set dep_id=100 where id=1; #修改dep_id数据 结果报错。
但我们可以选择先删除关联表中的数据后,再更改与其关联表emp中的字段。但这
并不是最好的解决办法
第三步 深度关联(修改/删除同步)on update cascade on delete cascade
create table dep( id int primary key auto_increment, dep_name char(16), dep_desc char(64) ); create table emp( id int primary key auto_increment, name char(16), gender enum('male','female','others') not null default 'male', # default后面的默认值空格直接书写即可 dep_id int, foreign key(dep_id) references dep(id) on update cascade # 同步更新 on delete cascade # 同步删除 );
| 多对多(第三张表牵线搭桥) |
当我们面对的是两张表互相之间都是多对一的情况,也就是多对多的情况时,就会出现互为外键,如果还是安装上面的方法创建,就会出现无法创建表的情况。此时我们需要第三张表来作为中间人,
为两张表牵线搭桥,让它们产生关联。
书与作者案例
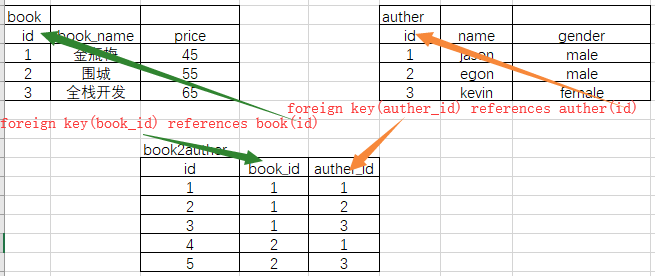
多对多案例实现
create table book( id int primary key auto_increment, title char(16), price int ); create table author( id int primary key auto_increment, name char(16), gender char(16) ); create table book2author( id int primary key auto_increment, book_id int, author_id int, foreign key(book_id) references book(id) on update cascade # 同步更新 on delete cascade, # 同步删除 foreign key(author_id) references author(id) on update cascade # 同步更新 on delete cascade # 同步删除 );
插入数据
insert into book(title,price) values
('瓶金梅','69.96'),
('围城','99.99'),
('python全栈开发','21000');
insert into author(name,gender) values
('jason','male'),
('egon','female'),
('kevin','male');
insert into book2author(book_id,author_id) values
(1,1),
(1,2),
(1,3),
(2,1),
(2,3),
(3,1),
(3,2);
| 一对一 |

客户表和学生表(老男孩的客户与学生之间,报名之前都是客户,只有报了名的才能是学生)
# 左表的一条记录唯一对应右表的一条记录,反之也一样 create table customer( id int primary key auto_increment, name char(20) not null, qq char(10) not null, phone char(16) not null ); create table student( id int primary key auto_increment, class_name char(20) not null, customer_id int unique, #该字段一定要是唯一的 foreign key(customer_id) references customer(id) #外键的字段一定要保证unique on delete cascade on update cascade );
修改表
| 语法: 1. 修改表名 ALTER TABLE 表名 RENAME 新表名; 2. 增加字段 ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…], ADD 字段名 数据类型 [完整性约束条件…]; ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] FIRST; ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名; 3. 删除字段 ALTER TABLE 表名 DROP 字段名; 4. 修改字段 ALTER TABLE 表名 MODIFY 字段名 数据类型 [完整性约束条件…]; ALTER TABLE 表名 CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…]; ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…]; |
复制表
| # 复制表结构+记录 (key不会复制: 主键、外键和索引) create table new_service select * from service; # 只复制表结构 select * from service where 1=2; //条件为假,查不到任何记录 create table new1_service select * from service where 1=2; create table t4 like employees; |