CodeForces Round#628 赛后题解
Codeforces round 628赛后解题报告
A. EhAb AnD gCd
首先,我们要来了解一些性质,以及 LCM 和 GCD 的一些特殊关联,我们从他们的定义入手:
首先,我们设:
a = Π i = 1 p i c i , b = Π i = 1 p i d i a=\Pi_{i=1} p_i^{c_i},b=\Pi_{i=1} p_i^{d_i} a=Πi=1pici,b=Πi=1pidi
其中, p i p_i pi 代表质数。这样,我们就有:
g c d ( a , b ) = Π i = 1 p i min ( c i , d i ) gcd(a,b)=\Pi_{i=1} p_i^{\min(c_i,d_i)} gcd(a,b)=Πi=1pimin(ci,di)
l c m ( a , b ) = Π i = 1 p i max ( c i , d i ) lcm(a,b)=\Pi_{i=1} p_i^{\max(c_i,d_i)} lcm(a,b)=Πi=1pimax(ci,di)
由于我们知道:对于任意两个数 x , y x,y x,y,都有 x + y = min ( x , y ) + max ( x , y ) x+y=\min(x,y)+\max(x,y) x+y=min(x,y)+max(x,y),因此:
a ⋅ b = g c d ( a , b ) ⋅ l c m ( a , b ) a\cdot b=gcd(a,b)\cdot lcm(a,b) a⋅b=gcd(a,b)⋅lcm(a,b)
所以对于这道题,我们知道了 g c d ( a , b ) + l c m ( a , b ) = x gcd(a,b)+lcm(a,b)=x gcd(a,b)+lcm(a,b)=x,而且 a ⋅ b = g c d ( a , b ) ⋅ l c m ( a , b ) a\cdot b=gcd(a,b)\cdot lcm(a,b) a⋅b=gcd(a,b)⋅lcm(a,b),所以当 a = 1 , b = x − 1 a=1,b=x-1 a=1,b=x−1 时,这两个条件同时满足,所以只要输出 1 , x − 1 1,x-1 1,x−1 即可。
//#pragma GCC optimize("Ofast","-funroll-loops","-fdelete-null-pointer-checks")
//#pragma GCC target("ssse3","sse3","sse2","sse","avx2","avx")
#includeB. CopyCopyCopyCopyCopy
对于这样一道题来说,因为是在复制了 n n n 次的数列里取数,所以真正把数列列出来,然后 DP 地算法,时间复杂度超太多,不现实,所以我们考虑贪心。
因为是复制了 n n n 次的数列,所以我们甚至可以在每一个数列里取一个数,最后凑成原数列,所以这告诉我们,原数列的任意全排列皆可以取到,所以只要对于原数列去重后,把元素个数输出即可。
//#pragma GCC optimize("Ofast","-funroll-loops","-fdelete-null-pointer-checks")
//#pragma GCC target("ssse3","sse3","sse2","sse","avx2","avx")
#includeC. Ehab and Path-etic MEXs
首先这道题我读了20min才读懂
闲话不多说,我们先来看题。通过思考,我们发现,其实我们只需要考虑边权为 0 , 1 , 2 0,1,2 0,1,2 的边。为什么呢?首先,我们来讲一个废话真命题:对于任意两条边,他们肯定同时出现在一条也是唯一一条链上。
因此我们发现,题目中所提到的 max ( u , v ) ∈ E M E X ( u , v ) \max_{(u,v)\in E} MEX(u,v) max(u,v)∈EMEX(u,v),无论如何,最小值至少为2,因为 0 , 1 0,1 0,1 肯定出现在一条链上。而对于答案是否大于 2 2 2,我们就要分析边权为 2 2 2 的这条边了。所以,为了使 0 , 1 , 2 0,1,2 0,1,2,不再一条链上,我们需要找到如下图的“T型” ,如果能找到,那么答案就为2,找到一个“T型”,然后把 0 , 1 , 2 0,1,2 0,1,2 分别放上去即可。

但如果找不到呢?是不是要考虑 3 3 3?
其实不用,如果找不到“T型”,那么,这棵树就退化成了一条链,那么所有边在一条链上(也只有一条链),所以边权随意乱放,答案也都一样。这道题就分析完了。
//#pragma GCC optimize("Ofast","-funroll-loops","-fdelete-null-pointer-checks")
//#pragma GCC target("ssse3","sse3","sse2","sse","avx2","avx")
#includeD. Ehab the Xorcist
这道题是一个纯数学的题,首先我们来看:如果 u > v u>v u>v 输出 − 1 -1 −1,因为 x o r xor xor 操作只会然数变小,不会变大,所以得证。然后我们会发现,答案数组的元素数不会超过 3 3 3,因为对于一个三元组: ( u , ( v − u ) 2 , ( v − u ) 2 ) (u,\frac{(v-u)}{2},\frac{(v-u)}{2}) (u,2(v−u),2(v−u)),永远满足题目要求(因为 a x o r a = 0 a\ xor\ a=0 a xor a=0)所以我们需要考虑的就是什么情况下答案为 0 , 1 , 2 0,1,2 0,1,2。我们一次来分析。
对于 0 0 0,当 u = v = 0 u=v=0 u=v=0 时,答案是 0 0 0,样例已给出。
对于 1 1 1,很好说,就是当 u = v ≠ 0 u=v\neq 0 u=v=0 时,答案数组为 u u u,元素个数为 1 1 1。
对于 2 2 2 来说,就是一个数对 ( a , b ) (a,b) (a,b) 满足: a + b = v , a x o r b = u a+b=v,a\ xor\ b=u a+b=v,a xor b=u,由于我们知道: a + b = a x o r b + 2 ⋅ ( a & b ) a+b=a\ xor\ b+2\cdot(a \& b) a+b=a xor b+2⋅(a&b),所以 a & b = ( v − u ) 2 a \& b=\frac{(v-u)}{2} a&b=2(v−u)。这是一个惊人的发现。我们再来对这些数以二进制的形式一点一点分析,我们设: x = v − u 2 x=\frac{v-u}{2} x=2v−u。如果对于 x x x 来说,在第 i i i 位上是 1 1 1,那么 a , b a,b a,b 这一位上都是 1 1 1,然后我们就可以发现, u u u 的第 i i i 位上就是 0 0 0。然而只有当 a , b a,b a,b 某一位上都是 0 0 0, u , x u,x u,x 在这一位上的数值也都是 0 0 0。这也是他们在某一位上唯一可能相等的情况。所以,如果 x & u ≠ 0 x\&u\neq 0 x&u=0,那么答案就为 3 3 3,否则答案可以为 2 2 2。我们继续分析,由于之前说过: a + b = a x o r b + 2 ⋅ ( a & b ) a+b=a\ xor\ b+2\cdot(a \& b) a+b=a xor b+2⋅(a&b),然而现在 x & u = 0 x\&u=0 x&u=0,所以 x + u = x x o r u x+u=x\ xor\ u x+u=x xor u,因此 ( u + x , x ) (u+x,x) (u+x,x) 是一组可行的二元组。
//#pragma GCC optimize("Ofast","-funroll-loops","-fdelete-null-pointer-checks")
//#pragma GCC target("ssse3","sse3","sse2","sse","avx2","avx")
#includeE. Ehab’s REAL Number Theory Problem
这,也是一道纯数论题,首先题目里有一句很重要的话:“every element in this array has at most 7 divisors”,然而我们知道,如果 p p p 表示质数,则:
a = Π i = 1 p i c i a=\Pi_{i=1}\ p_i^{c_i} a=Πi=1 pici
所以 a a a 共有:
Π i = 1 c i + 1 \Pi_{i=1}\ c_i+1 Πi=1 ci+1
个约数,然而这道题里的数,至多有 7 7 7 个约数,这代表,这道题里给出的数一定能用( p , q p,q p,q 为质数):
a = p x ⋅ q y a=p^x\cdot q^y a=px⋅qy
每个数最多只有两个不同质因子,这样这个就简单很多了。
我们不难想到,可以对 p , q p,q p,q 建边,若果 x , y x,y x,y 中有一个为0,那么就把另一个对应的底数与 1 1 1 相连。所以,对于样例3来说,就是这样的图:

发现了什么?这是一个环!!!所以在这样的图里,任意一个环,都代表着一个完全平方数的诞生,所以我们只需要找到最小环即可。
但为什么呢?我们发现,我们可以把每一条边想象成一个数,每次走过这条边,就相当于我们用了这个数。所以通过这条边,也相当于在最后我们所需要的形成的那个完全平方数上把其两个节点的编号乘上去。所以只要形成了环,那么每个节点被乘上去的次数就为 2 2 2,这样我们最后得到一个完全平方数。由于我们要找的数,越少越好,所以求得就算是最小环。
但是还有一个问题:最小环算法是 O ( n 2 ) O(n^2) O(n2) 的,会超时。其实我们只需要从编号 ≤ max a i \leq \sqrt{\max a_i} ≤maxai 即可,这个可以给读者思考为什么。算法的时间复杂度就降到了 O ( p ( n ) ⋅ p ( max a i ) ) O(p(n)\cdot p(\max a_i)) O(p(n)⋅p(maxai)), p ( x ) p(x) p(x) 指小于等于 x x x 的质数的个数。
//#pragma GCC optimize("Ofast","-funroll-loops","-fdelete-null-pointer-checks")
//#pragma GCC target("ssse3","sse3","sse2","sse","avx2","avx")
#includeF. Ehab’s Last Theorem
最后一道题,很有质量,是一道好的图论题。
我们定义 s q = ⌈ n ⌉ sq=\lceil \sqrt n\rceil sq=⌈n⌉。我们把原题中样例2的图搬过来作为举例:
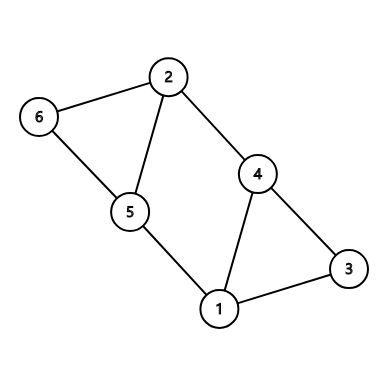
首先,我们随便以一个点作为起点进行 DFS。我们以1位起点。那么,我把DFS中经过过的边(也就是DFS树),边权为 1 1 1,其他为 0 0 0。那么原图就变成了这个样子:
 )
)
我们发现,由 1 1 1 边构成的图是一棵树,虽然这个性质对我们的解题毫无用处,但这个DFS树真的是没什么用,了解就好,他对我们的思路启发是有一点作用的。我们继续讲题,现在,如果在DFS时,我们从 u u u 出发,找到了一个点 v v v,如果之前 v v v 已经被搜到过了,而且 u , v u,v u,v 的在DFS树上深度差大于等于 s q − 1 sq-1 sq−1,就可以找到一个长度至少为 s q sq sq 的环,就可以回答第二个问题了。如果没有这样的边,那么我们一定可以回答的一个问题,具体证明很简单,这里不再赘述,应该是一个小学奥数的证明吧。
所以我们就可以快乐地写代码啦!
//#pragma GCC optimize("Ofast","-funroll-loops","-fdelete-null-pointer-checks")
//#pragma GCC target("ssse3","sse3","sse2","sse","avx2","avx")
#include