学习笔记:MySQL数据库入门实战精讲
- 目前仍在学习中,欢迎多多交流
- 学习笔记的代码都是参考此课程的
一、数据库的基本概念
MYSQL属于RDMS:关系型数据库管理系统
二、数据库与表的基本操作
(一)、DDL之数据库
- sql创建管理数据库、数据表、存储过程、视图等,插入修改、删除、查询记录、事务控制和权限管理
- sql语言的分类
sql语言按功能来分
- ddl:数据定义语言:CREATE、ALTER、DROP等
- dml:数据操纵语言:INSERT、DELETE、UPDATE
- dcl:数据控制语言:COMMIT、ROLLBACK、GRANT等
- dql:数据查询语言:SELECT
DDL:
CREATE DATABASE database_name;
DROP DATABASE database_name;
(二)、DDL之数据表
- 查看存储引擎:show engines;【MyISAM:不支持事务;InnoDB:支持事务】
- 数据类型:
- 数值类型:int(4),decimal( , )
- 日期和时间类型:date(3),datetime(8)
- 字符串类型:varchar(0-65535)变长字符串,text(0-65535)
建表语法:
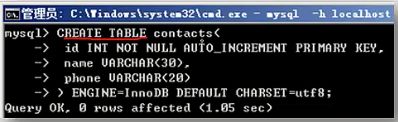
【!!!】engine=myisam default charset=utf8;
- add field:ALTER TABLE table_name ADD field type(byte);
- alter field type:ALTER TABLE table_name MODIFY field new_type;
- drop field:ALTER TABLE table_name DROP COLUMN field;
- drop table:DROP TABLE table_name;
[show tables; desc table_name(表明)]
(三)、DML:插入、修改、删除数据
- INSERT INTO table_name VALUES();
- UPDATE table_name SET field1=value1,field2=value2 [WHERE range];
- DELETE FROM table_name [WHERE range];
【select * from table_name;】
1.字符串里面本身有单引号用转义“\”,不然会报错;
如:

也可以在外面用双引号
如:

(四)、数据完整性
:数据在库里的一致性和可靠性
1.实体完整性:【行】每个对象都可区别
- 每张表都要唯一标识符,每张表的主键字段不能为空且重复
- 约束方法:唯一性、主键、标识符
2.参照完整性:表与表之间的关系(外键)
- 要求关系中不允许引用不存在的实体
- 约束方法:外键约束
- 外键就是其他表的主键
3.用户定义完整性:存储过程、触发器
- 反映某一具体应用所涉及的数据必须满足的语义要求
- 约束方法:规则、存储过程、触发器
4.域完整性:【列】限制类型、格式、值的范围
- 针对某一关系型数据库的约束条件
- 保证某些列不能输入无效值
- 约束方法:限制数据类型、检查约束、默认值、非空约束
- 唯一性:unique
- 外键:foreign key(从表与主表相同的字段) references 主表名(主表与从表相同的字段)
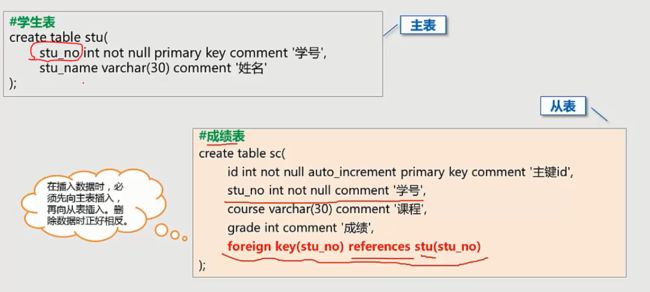
- [学校教的外键命令是这个,暂时不知道跟上面的有什么区别]
constraint 外键名 foreign key(从表与主表相同的字段)
references 主表名(主表与从表相同的字段)
关外键:set foreign_key_checks=0;
开外键:set foreign_key_checks=1;
二、数据查询语言DQL
(一)、简单查询
mysql官网(查具体命令用法):https://dev.mysql.com/doc/refman/8.0/en/numeric-types.html

1.select * from table_name;
2.select field1,field2 from table_name where range;
(二)、条件查询(单条件、多条件)
create table employee(
id int not null auto_increment primary key,
name varchar(30) comment '姓名',
sex varchar(1) comment '性别',
salary int comment '薪资(元)'
)engine=myisam default charsets=utf8;insert into employee(name, sex, salary)
values('张三', '男', 5500),('李洁', '女', 4500),('李小梅', '女', 4200),('欧阳辉', '男', 7500),
('李芳', '女', 8500),('张江', '男', 6800),('李四', '男', 12000),('王五', '男', 3500),
('马小龙', '男', 6000),('龙五', '男', 8000),('冯小芳', '女', 10000),('马小花', '女', 4000);
1、where子句(单条件查询)
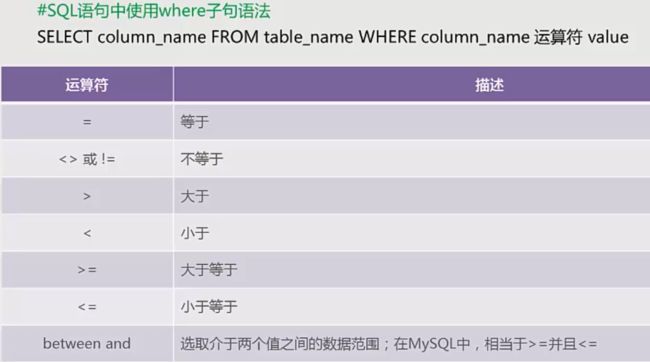
2、where子句(多条件查询)

【!!!区别and和or】

(三)、IN和LIKE的使用
1、运算法in的使用

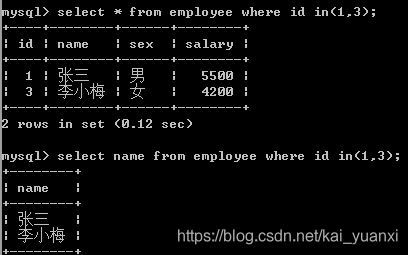
2、运算法like的使用

(1)、like等于=
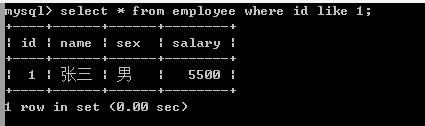
(2)、%任意匹配字符前、后
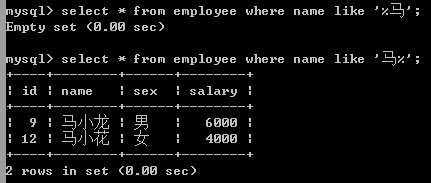
(3)、_单一匹配字符前、后

(四)、MySQL常用函数讲解-01
1、mysql的内置函数

(1)、函数now()用于返回当前的日期和时间


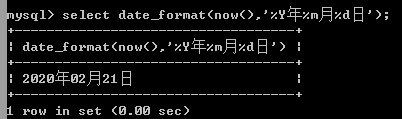
(2)、函数date_format()用于以指定的格式显示日期/时间

(3)、聚合函数是对一组值进行计算,并返回单个值
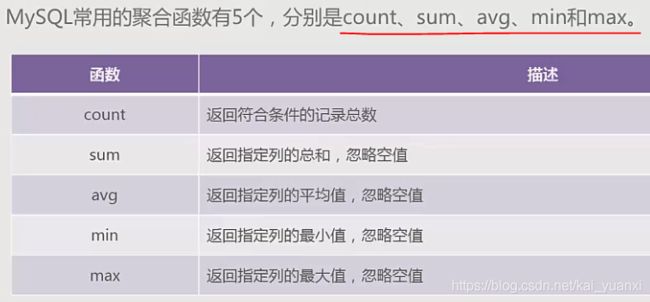
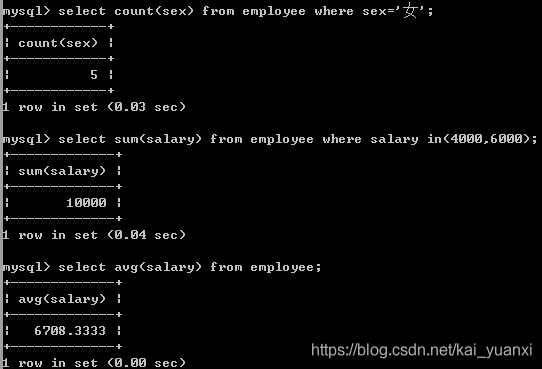
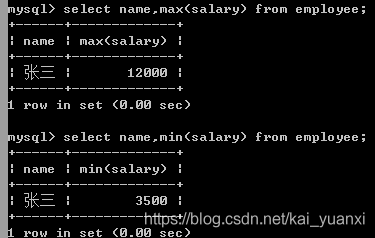
(4)、函数ifnull()用于处理null值
![]()
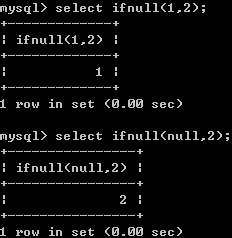
(5)、case when是流程控制语句,可以获取更加准确和直接的结果(类似if else或者switch)

insert into employee(name, sex, salary)
values('天天', '未知', 5500);
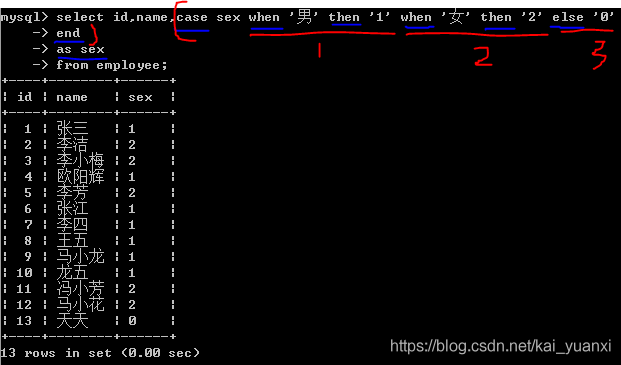
as:取别名
(五)、MySQL常用函数讲解-02
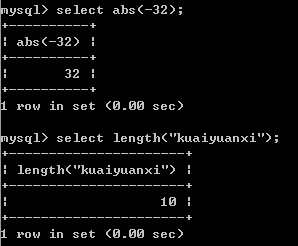 abs:绝对值;length:长度
abs:绝对值;length:长度
 dual:虚拟表
dual:虚拟表
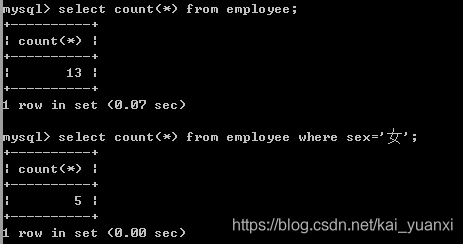 count:记录
count:记录
select id,name,case sex when '男' then 'F' when '女' then 'M' else '?'
end
as sex,salary
from employee;
(六)、查询结果排序与分页
1、order by 对查询结果集进行排序,可以按照一例或多例进行排序

(1)、asc
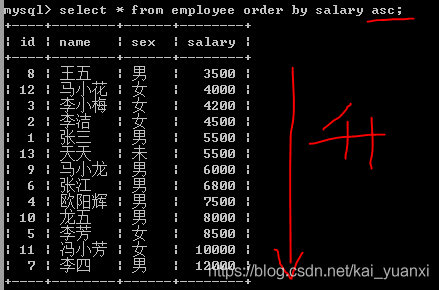
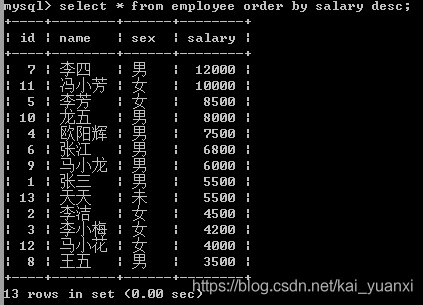
(2)、desc
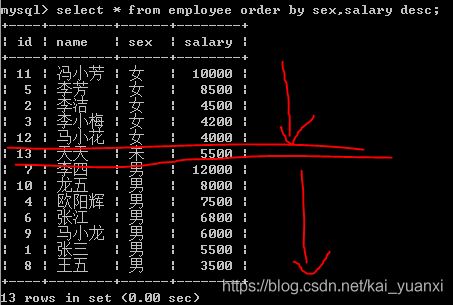
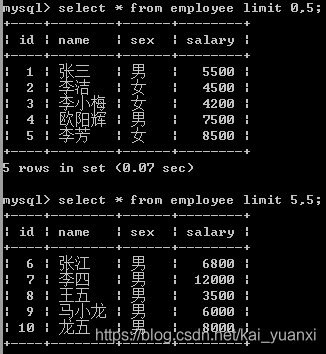
2、limit 用来约束要返回的记录数,通常使用limit实现分页

第1页:(1-1)*5,5【0,5】;第2页:(2-1)*5,5【5,5】;第3页:(3-1)*5,5【10,5】

(七)、GROUP BY和HAVING的使用
create table employee(
id int not null auto_increment primary key,
name varchar(30) comment '姓名',
sex varchar(1) comment '性别',
salary int comment '薪资(元)',
dept varchar(30) comment '部门');
insert into employee(name, sex, salary, dept) values('张三', '男', 5500, '部门A'),('李洁', '女', 4500, '部门C'),
('李小梅', '女', 4200, '部门A'),('欧阳辉', '男', 7500, '部门C'),('李芳', '女', 8500, '部门A'),('张江', '男', 6800, '部门A'),
('李四', '男', 12000, '部门B'),('王五', '男', 3500, '部门B'),('马小龙', '男', 6000, '部门A'),('龙五', '男', 8000, '部门B'),
('冯小芳', '女', 10000, '部门C'),('马小花', '女', 4000, '部门B'),('柳峰', '男', 8800, '部门A');
1、group by表示根据某种规则对数据进行分组,它必须配合聚合函数(count、sum、avg、max、min等)进行使用

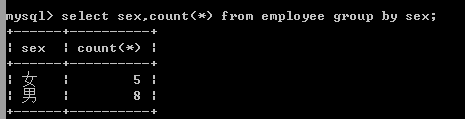
男女各有多少人?
记select sex,count(*) from employee group by sex;
:(为什么要写这个呢,因为我自己总是需要查的字段那里总是出错··· ···,所以··· ···)
1、按照性别进行分组—>group by sex
(2、多少人?那就是几条记录!聚合函数count—>count)
3、需要查的字段:(1)性别—>sex , (2)需要数据表的所有记录数—>count(*)
>>按照性别进行分组
男女各有多少人?:
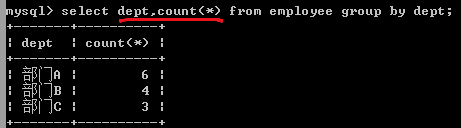
>>按照部门进行分组
所有部门各有多少人?:
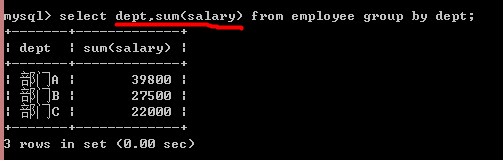
求各部门薪水之和:
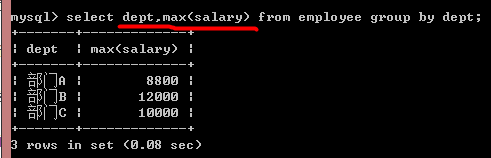
求各部门最高和最低的薪水:

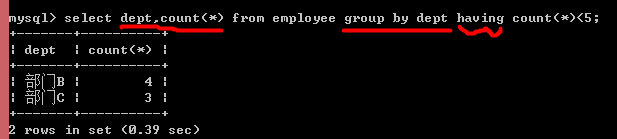
2、having子句对分组后的各组数据进行筛选(where关键字无法与聚合函数一起使用)

少于4人的部门(在各部门人数的基础上用having,因为不能用where)
哪个部门的哪位员工的薪资是过万的?

【group by必须和聚合函数一起使用,上图理解错误】
