遗传算法实现TSP问题
遗传算法实现TSP问题
文章目录
- 遗传算法实现TSP问题
- 1.算法介绍
- 1.1 遗传算法原理
- 1.2 TSP问题描述
- 2.算法实现
- 2.1 代码实现
- 2.2 运行结果展示
- 3参数分析
- 3.1改变种群数量
- 3.2改变迭代次数
- 3.3改变交叉概率
- 3.4改变变异概率
- 3.5改变城市个数
1.算法介绍
1.1 遗传算法原理
详见博客https://blog.csdn.net/lzydelyc/article/details/102906590
1.2 TSP问题描述

2.算法实现
2.1 代码实现
2.1.1选择数据
在命令行窗口实现以下语句

然后将mat文件load出来即可。
2.1.2代码
(1)main函数
%main
clear;
clc;
%%%%%%%%%%%%%%%输入参数%%%%%%%%
N=25; %%城市的个数
M=100; %%种群的个数
ITER=1000; %%迭代次数
m=2; %%适应值归一化淘汰加速指数
Pc=0.8; %%交叉概率
Pmutation=0.05; %%变异概率
%生成城市的坐标
load city_25;
%pos=city_100;
%生成城市之间距离矩阵
D=zeros(N,N);
for i=1:N
for j=i+1:N
dis=(pos(i,1)-pos(j,1)).^2+(pos(i,2)-pos(j,2)).^2;
D(i,j)=dis^(0.5);
D(j,i)=D(i,j);
end
end
%生成初始群体
popm=zeros(M,N);
for i=1:M
popm(i,:)=randperm(N);%随机排列,比如[2 4 5 6 1 3]
end
%随机选择一个种群
R=popm(1,:);
figure(1);
scatter(pos(:,1),pos(:,2),'rx');%画出所有城市坐标
axis([-3 3 -3 3]);
figure(2);
plot_route(pos,R); %%画出初始种群对应各城市之间的连线
axis([-3 3 -3 3]);
%初始化种群及其适应函数
fitness=zeros(M,1);
len=zeros(M,1);
for i=1:M%计算每个染色体对应的总长度
len(i,1)=myLength(D,popm(i,:));
end
maxlen=max(len);%最大回路
minlen=min(len);%最小回路
fitness=fit(len,m,maxlen,minlen);
rr=find(len==minlen);%找到最小值的下标,赋值为rr
R=popm(rr(1,1),:);%提取该染色体,赋值为R
for i=1:N
fprintf('%d ',R(i));%把R顺序打印出来
end
fprintf('\n');
fitness=fitness/sum(fitness);
distance_min=zeros(1000+1,1); %%各次迭代的最小的种群的路径总长
nn=M;
iter=0;
while iter<=1000
fprintf('迭代第%d次\n',iter);
%选择操作
p=fitness./sum(fitness);
q=cumsum(p);%累加
for i=1:(M-1)
len_1(i,1)=myLength(D,popm(i,:));
r=rand;
tmp=find(r<=q);
popm_sel(i,:)=popm(tmp(1),:);
end
[fmax,indmax]=max(fitness);%求当代最佳个体
popm_sel(M,:)=popm(indmax,:);
%%交叉操作
nnper=randperm(M);
for i=1:M*Pc*0.5
A=popm_sel(nnper(i),:);
B=popm_sel(nnper(i+1),:);
[A,B]=cross(A,B);
popm_sel(nnper(i),:)=A;
popm_sel(nnper(i+1),:)=B;
end
%%变异操作
for i=1:M
pick=rand;
while pick==0
pick=rand;
end
if pick<=Pmutation
popm_sel(i,:)=Mutation(popm_sel(i,:));
end
end
%%求适应度函数
NN=size(popm_sel,1);
len=zeros(NN,1);
for i=1:NN
len(i,1)=myLength(D,popm_sel(i,:));
end
maxlen=max(len);
minlen=min(len);
distance_min(iter+1,1)=minlen;
fitness=fit(len,m,maxlen,minlen);
rr=find(len==minlen);
fprintf('minlen=%d\n',minlen);
R=popm_sel(rr(1,1),:);
for i=1:N
fprintf('%d ',R(i));
end
fprintf('\n');
popm=[];
popm=popm_sel;
iter=iter+1;
%pause(1);
end
%end of while
figure(3)
plot_route(pos,R);
axis([-3 3 -3 3]);
figure(4)
plot(distance_min);
(2)计算染色体路程代价函数
function len=myLength(D,p)%p是一个排列
[N,NN]=size(D);
len=D(p(1,N),p(1,1));
for i=1:(N-1)
len=len+D(p(1,i),p(1,i+1));
end
end
(3)适应度函数
function fitness=fit(len,m,maxlen,minlen)
fitness=len;
for i=1:length(len)
fitness(i,1)=(1-(len(i,1)-minlen)/(maxlen-minlen+0.0001)).^m;
end
(4)交叉函数
function [A,B]=cross(A,B)
L=length(A);
if L<10
W=L;
elseif ((L/10)-floor(L/10))>=rand&&L>10
W=ceil(L/10)+8;
else
W=floor(L/10)+8;
end
%%W为需要交叉的位数
p=unidrnd(L-W+1);%随机产生一个交叉位置
%fprintf('p=%d ',p);%交叉位置
for i=1:W
x=find(A==B(1,p+i-1));
y=find(B==A(1,p+i-1));
[A(1,p+i-1),B(1,p+i-1)]=exchange(A(1,p+i-1),B(1,p+i-1));
[A(1,x),B(1,y)]=exchange(A(1,x),B(1,y));
end
end
(5)交换函数
%对调函数 exchange.m
function [x,y]=exchange(x,y)
temp=x;
x=y;
y=temp;
end
(6)变异函数
function a=Mutation(A)
index1=0;index2=0;
nnper=randperm(size(A,2));
index1=nnper(1);
index2=nnper(2);
%fprintf('index1=%d ',index1);
%fprintf('index2=%d ',index2);
temp=0;
temp=A(index1);
A(index1)=A(index2);
A(index2)=temp;
a=A;
end
(7)画图函数
function plot_route(a,R)
scatter(a(:,1),a(:,2),'rx');
hold on;
plot([a(R(1),1),a(R(length(R)),1)],[a(R(1),2),a(R(length(R)),2)]);
hold on;
for i=2:length(R)
x0=a(R(i-1),1);
y0=a(R(i-1),2);
x1=a(R(i),1);
y1=a(R(i),2);
xx=[x0,x1];
yy=[y0,y1];
plot(xx,yy);
hold on;
end
end
2.2 运行结果展示
运行结果展示了(1)城市分布(2)初始种群线路(3)最终线路(4)在设定的迭代次数下的路径长度变化。
此处展示的是城市个数为25,种群个数为50,迭代次数2000,交叉概率0.8,变异概率0.05的情况下的路线情况。
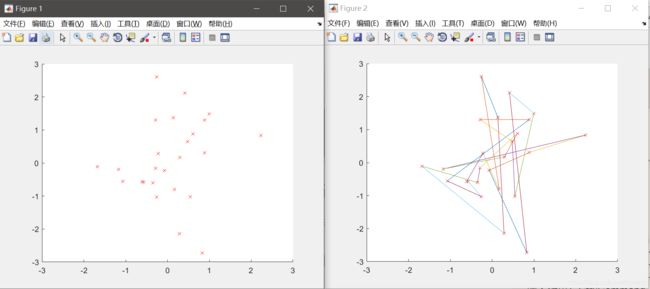
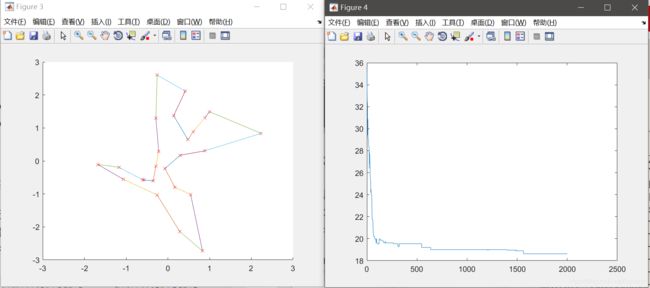
3参数分析
3.1改变种群数量
城市数量25,迭代总次数2000,交叉概率0.8,变异概率为0.05
| 种群数量 | 迭代达到最短距离的次数 | 最短距离 | 运行时间 |
|---|---|---|---|
| 50 | 364 | 2.000404 | 51.247 |
| 100 | 506 | 1.938898 | 50.784 |
| 200 | 1086 | 1.863281 | 51.296 |
| 300 | 433 | 2.136286 | 47.653 |
由上表可知,最短距离随着种群规模的增大先增加后减少,所以种群数量设置在100-200较好。
3.2改变迭代次数
城市数量25,种群数量100,交叉概率0.8,变异概率为0.05
| 迭代次数 | 迭代达到最短距离的次数 | 最短距离 | 运行时间 |
|---|---|---|---|
| 500 | 392 | 2.044818 | 13.247 |
| 1000 | 493 | 2.027277 | 27.702 |
| 2000 | 506 | 1.938898 | 50.784 |
| 3000 | 506 | 1.914200 | 79.134 |
由上表可知,随着迭代次数的增大,最短距离会递减,但是运行时间会增大,并且没有太大的意义,将迭代次数设在1000-2000较好。
3.3改变交叉概率
城市数量25,种群数量100,迭代次数2000,变异概率为0.05
| 变异概率 | 迭代达到最短距离的次数 | 最短距离 | 运行时间 |
|---|---|---|---|
| 0.2 | 421 | 1.854877 | 27.718 |
| 0.5 | 319 | 1.823316 | 27.897 |
| 0.8 | 272 | 1.939617 | 25.606 |
| 1 | 649 | 2.204067 | 25.912 |
由表中可知交叉概率在0-1上变化时,最短距离呈现出先减小后增大,运行时间随变异概率增大而减小,交叉概率在0.2-0.8之间较好。
3.4改变变异概率
城市数量25,种群数量100,迭代次数1000,交叉概率为0.8
| 变异概率 | 迭代达到最短距离的次数 | 最短距离 | 运行时间 |
|---|---|---|---|
| 0.005 | 179 | 1.872593 | 24.587 |
| 0.01 | 448 | 1.916578 | 25.638 |
| 0.05 | 448 | 1.963113 | 25.255 |
| 0.5 | 371 | 2.067011 | 39.533 |
变异概率在0.5的时候运行时间过长,呈现出破坏性,变异概率在0.005-0.01之间较好。
3.5改变城市个数
城市数量25,种群数量100,迭代次数2000,交叉概率为0.8
| 城市个数 | 迭代达到最短距离的次数 | 最短距离 | 运行时间 |
|---|---|---|---|
| 10 | 18 | 1.017932 | 15.757 |
| 25 | 448 | 1.916578 | 25.638 |
| 50 | 1528 | 3.493564 | 27.444 |
| 100 | 1984 | 6.706513 | 39.533 |
城市个数在50的时候迭代达到最短距离的次数已经快到2000了,运行时间也越来越长。
注:较优值取于我的实验结果,不代表标准答案。
一个尝试:
城市数量100,迭代次数4000的情况下运行:
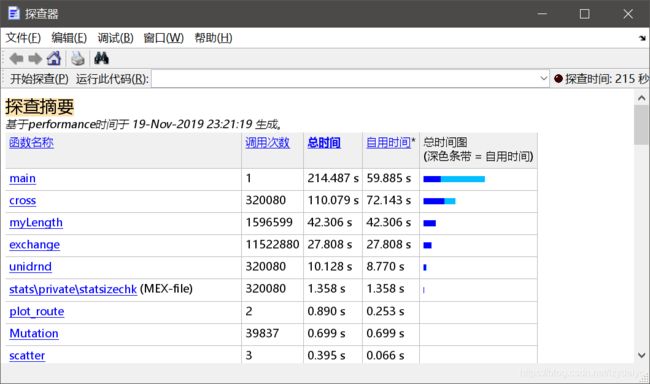
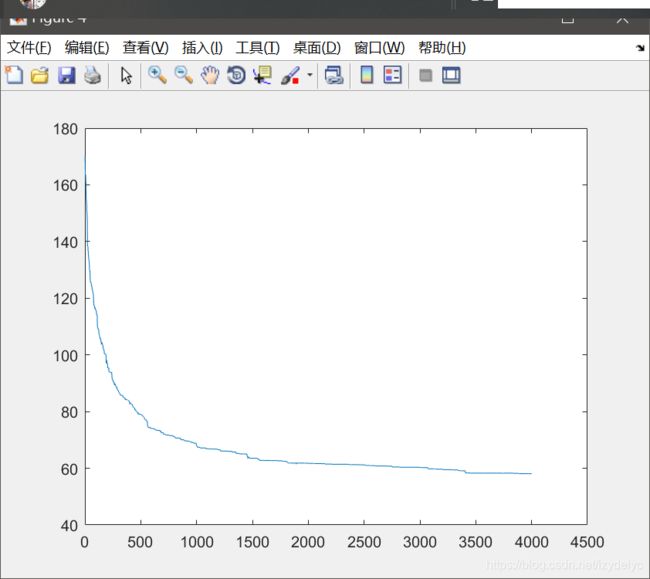
城市个数过大,迭代次数过多,GA一直不能完全收敛,可能的问题是陷入了局部最优解,因此对GA算法进行改进宜跳出局部最优解,可以采用类似于PSO或者蚁群算法的思想。