网易 | 数据结构和算法 | 学习笔记03:树
视频课程:数据结构(浙江大学: 陈越、何钦铭)(第三讲、第四讲)
┏━━━━━━目录━━━━━━┓
3.1 树与树的表示
3.2 二叉树及存储结构
3.3 二叉树的遍历
4.1 二叉搜索树
4.2 平衡二叉树
4.3 堆
4.4 哈夫曼树与哈夫曼编码
4.5 集合及运算
┗━━━━━━━━━━━━━━┛
1、引子:查找——根据某个给定关键字K ,从集合R中找出关键字与K相同的记录
(1)静态查找:集合中记录是固定的——没有插入和删除操作,只有查找
〖方法1〗顺序查找:时间复杂度为O(n)
* 算法技巧:建立哨兵
〖方法2〗二分查找(Binary Search):时间复杂度O(logN)
[注]:为什么是logN?因为每次查找范围除以2,一直除到1
① 假设n个数据元素的关键字满足有序(比如:小到大)
② 并且是连续存放(数组),那么可以进行二分查找。
* left > right ? 查找失败,结束
* 二分查找判定树
(以11个元素为例)

① 判定树上每个结点需要的查找次数刚好为该结点所在的层数;
② 查找成功时查找次数不会超过判定树的深度
(查找效率是树的高度)
n个结点的判定树的深度为:[log(2,n)]+1.【以2为底n的对数,取整+1】
平均成功查找次数 ASL = (4*4+4*3+2*2+1)/11 = 3
(2)动态查找:集合中记录是动态变化的—— 除查找,还可能发生插入和删除
【见4.1二叉搜索树】
(3)对于任一棵非空树(n> 0),它具备以下性质:
① 树中有一个称为“ 根(Root)”的特殊结点,用 r 表示;
② 其余结点可分为m(m>0)个 互不相交的有限集T1,T2,... ,Tm,其中每个集合本身又是一棵树,称为原来树的“ 子树(SubTree)”
② 除了根结点外, 每个结点有且仅有一个父结点;
③ 一棵N个结点的树有 N-1条边。

2.树的度:树的所有结点中最大的度数
3.叶结点(Leaf):度为0的结点
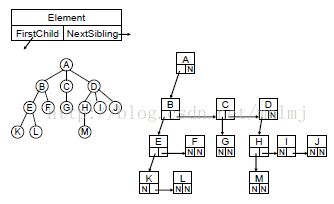
4.父结点(Parent):有子树的结点是其子树的根结点的父结点
5.子结点(Child):若A结点是B结点的父结点,则称B结点是A结点的子结点;子结点也称孩子结点。
6.兄弟结点(Sibling):具有同一父结点的各结点彼此是兄弟结点。

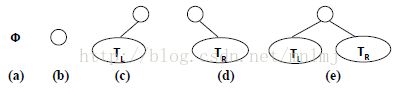
1、 二叉树的定义:一个有穷的结点集合。
(2)若不为空,则它是由 根结点和称为其 左子树TL和 右子树TR的两个不相交的二叉树组成。
(3)二叉树具体五种基本形态(空树、只有一个结点、左子树非空、右子树非空、都非空)

(3)对任何非空二叉树 T,若n0表示叶结点的个数、n2是度为2的非叶结点个数,那么两者满足关系n0 = n2 +1。
(2)数据对象集:一个有穷的结点集合。若不为空,则由根结点和其左、右二叉子树组成。
(3)操作集: BT BinTree, Item ElementType,重要操作有:
①Boolean IsEmpty( BinTree BT ): 判别BT是否为空;
②void Traversal( BinTree BT ): 遍历,按某顺序访问每个结点;
③BinTree CreatBinTree( ):创建一个二叉树。
①void PreOrderTraversal( BinTree BT ): 先序----根、左子树、右子树;
②void InOrderTraversal( BinTree BT ): 中序---左子树、根、右子树;
③void PostOrderTraversal( BinTree BT ):后序---左子树、右子树、根
④void LevelOrderTraversal( BinTree BT ):层次遍历,从上到下、从左到右
②结点(序号为 i )的左孩子结点的序号是 2i, (若2 i <= n,否则没有左孩子);
③结点(序号为 i )的右孩子结点的序号是 2i+1, (若2 i +1<= n,否则没有右孩子);
①访问根结点;
②先序遍历其左子树;(递归)
③先序遍历其右子树。(递归)
②访问根结点;
③中序遍历其右子树。(递归)
②后序遍历其右子树;(递归)
③访问根结点。

①遇到一个结点,就把它压栈,并去遍历它的左子树;
②当左子树遍历结束后,从栈顶弹出这个结点并访问它;
③ 然后按其右指针再去中序遍历该结点的右子树。
void InOrderTraversal( BinTree BT )
{ BinTree T=BT;
Stack S = CreatStack( MaxSize ); /*创建并初始化堆栈S*/
while( T || !IsEmpty(S) ){
while(T){ /*一直向左并将沿途结点压入堆栈*/
Push(S,T);
T = T->Left;
}
if(!IsEmpty(S)){
T = Pop(S); /*结点弹出堆栈*/
printf(“%5d”, T->Data); /*(访问)打印结点*/
T = T->Right; /*转向右子树*/
}
}
}(1)二叉树遍历的核心问题:二维结构的线性化
<Ⅰ> .从结点访问其左、右儿子结点
<Ⅱ>访问左儿子后,右儿子结点怎么办?
① 需要一个存储结构保存暂时不访问的结点
② 存储结构:堆栈、队列
③若该元素所指结点的左、右孩子结点非空, 则将其左、右孩子的指针顺序入队。

①先序遍历得到前缀表达式:+ + a * b c * + * d e f g
②中序遍历得到中缀表达式:a + b * c + d * e + f * g
③后序遍历得到后缀表达式:a b c * + d e * f + g * +
〖分析〗
①根据 先序遍历序列第一个结点确定 根结点;
②根据根结点在 中序遍历序列中 分割出左右两个子序列
③对左子树和右子树分别 递归使用相同的方法继续分解。
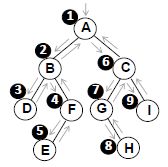
中序序列:c b e d a h g i j f

<Ⅱ>类似地,后序和中序遍历序列也可以确定一棵二叉树。
4.1 二叉搜索树(BST,Binary Search Tree)
(2)二叉搜索树:一棵二叉树,可以为空;如果不为空,满足以下性质:
① 非空 左子树的所有键值 小于其根结点的键值。
② 非空 右子树的所有键值 大于其根结点的键值。
③ 左、右子树都是二叉搜索树。
②Position FindMin( BinTree BST ):从二叉搜索树BST中查找并返回 最小元素所在结点的地址;
③Position FindMax( BinTree BST ) :从二叉搜索树BST中查找并返回 最大元素所在结点的地址。
④BinTree Insert( ElementType X, BinTree BST ) 插入
⑤BinTree Delete( ElementType X, BinTree BST ) 删除
①查找从根结点开始,如果树为空,返回NULL
②若搜索树非空,则根结点关键字和X进行比较,并进行不同处理:
③若X小于根结点键值,只需在左子树中继续搜索;
④如果X大于根结点的键值,在右子树中进行继续搜索;
⑤若两者比较结果是相等,搜索完成,返回指向此结点的指针。
①最大元素一定是在树的最右分枝的端结点上(沿着左分支,找到最后一个left)
②最小元素一定是在树的最左分枝的端结点上
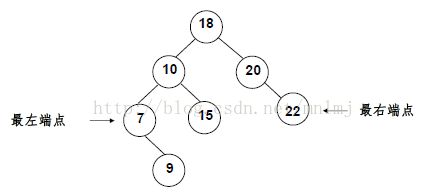
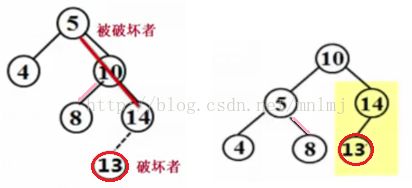
①要删除的是叶结点:直接删除,并再修改其父结点指针---置为NULL

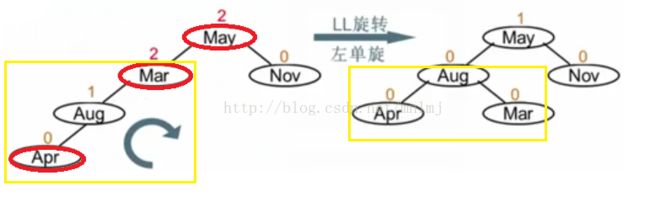
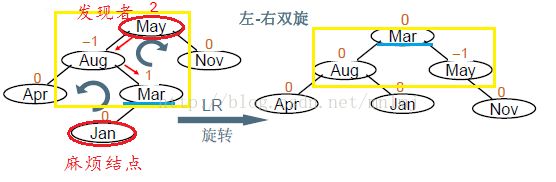
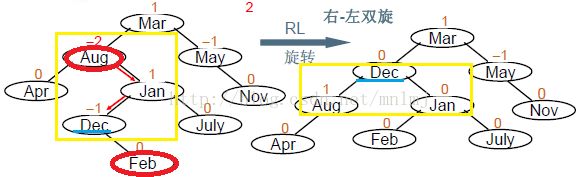
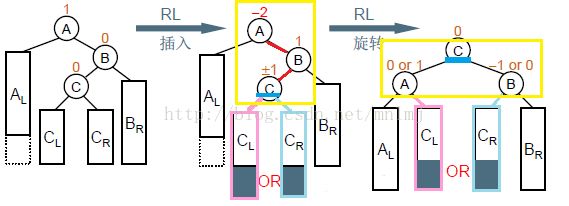
1、定义



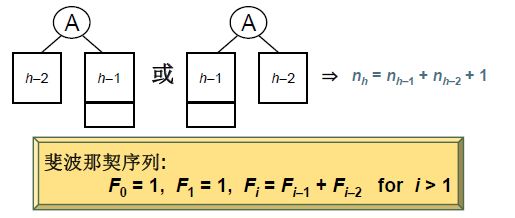






4.3 堆(heap)
1、 优先队列(Priority Queue):特殊的“队列”,取出元素的顺序是 依照元素的优先权(关键字)大小,而 不是元素进入队列的 先后顺序。
插入 — 元素总是插入尾部 ~ Θ ( 1 )
删除 — 查找最大(或最小)关键字 ~ Θ ( n )
去需要移动元素 ~ O( n )
插入 — 元素总是插入链表的头部 ~ Θ( 1 )
删除 — 查找最大(或最小)关键字 ~ Θ( n )
删去结点 ~ Θ( 1 )
插入 — 找到合适的位置 ~ O( n ) 或 O(log2 n )
移动元素并插入 ~ O( n )
删除 — 删去最后一个元素 ~ Θ( 1 )
【有序链表】
插入 — 找到合适的位置 ~ O( n )
插入元素 ~ Θ( 1 )
删除 — 删除首元素或最后元素 ~ Θ( 1 )

②有序性:任一结点的关键字是其子树所有结点的最大值(或最小值)
——“最大堆(MaxHeap)”,也称“大顶堆”:最大值
——“最小堆(MinHeap)”,也称“小顶堆” :最小值


•MaxHeap Create( int MaxSize ):创建一个空的最大堆。
•Boolean IsFull( MaxHeap H ):判断最大堆H是否已满。
•Insert( MaxHeap H, ElementType item ):将元素item 插入最大堆H。
•Boolean IsEmpty( MaxHeap H ):判断最大堆H是否为空。
•ElementType DeleteMax( MaxHeap H ):返回H中最大元素(高优先级)。
① 将N个元素按输入顺序存入,先满足完全二叉树的结构特性
② 调整各结点位置,以满足最大堆的有序特性。
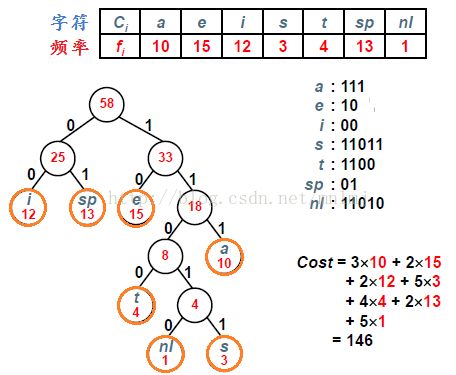
4.4 哈夫曼树与哈夫曼编码
* 如何根据结点不同的查找频率构造更有效的搜索树?
最优二叉树(哈夫曼树)为带权路径长度WPL值最小的二叉树

WPL =1×3+2×3+3×2+4×2+5×2=33
WPL=1×1+2×2+3×3+4×4+5×4=50

(1)没有度为1的结点;(因为是两两合并构造的)
(2)n个叶子结点的哈夫曼树共有2n-1个结点;
(4)对同一组权值{w1 ,w2 , …… , wn},是否存在不同构的两棵哈夫曼树呢?
* 例:对一组权值{ 1, 2 , 3, 3 },不同构的两棵哈夫曼树:

〖分析〗
(1)用等长ASCII编码:58 ×8 = 464位;(每个ASCII码占1个字节=8bit)
(2)用等长3位编码:58 ×3 = 174位;(3位可以表示2^3=8个不同的字符)
(3)不等长编码:出现频率高的字符用的编码短些,出现频率低的字符则可以编码长些? (见下文解答)
(1)左右分支:0、1
(2)字符只在叶结点上(此时不会出现一个字符的编码是另一字符编码的前缀,不会有二义性)

1、 集合的表示
(1) 集合运算: 交、并、补、差,判定一个元素是否属于某一集合
(2) 并查集:集合并、查某元素属于什么集合
* 并查集问题中集合存储如何实现?——可以用树结构表示集合,树的每个结点代表一个集合元素
〖例〗有10台电脑{1,2,3,...,9,10},一直下列电脑之间实现了链接:
1和2,2和4,3和5,4和7,5和8,6和9,6和10
问:2和7之间,5和9之间是富士连通的
〖分析〗
①将10台电脑看成10个集合,{1},{2},{3},...,{9},(10);
②已知一种连接“x和y”,就将x和y对应的集合合并;
③查询“x和y是否是连通的”就是判别x和y是否属于同一集合。
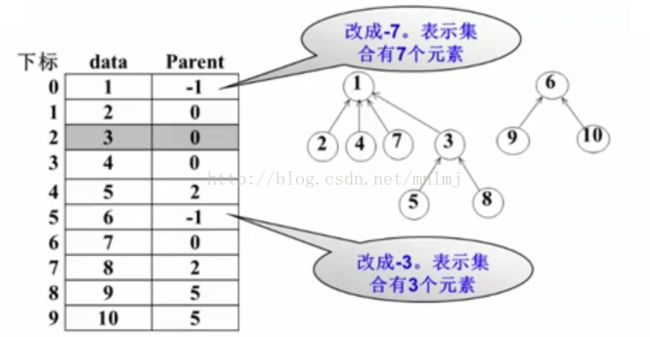
〖例〗有三个整数集合 S1={1,2,4,7},S2={3,5,8},S3={6,9,10}
* 双亲表示法:孩子指向双亲。

* 采用数组存储形式——parent位置为负数(-1)表示根结点;非负数表示指向父亲结点的下标位置。

2、集合运算
(1)查找某个元素所在的集合(用根结点表示)
(2) 集合的并运算
① 分别找到X1和X2两个元素所在集合树的根结点
② 如果它们不同根,则将其中一个根结点的父结点指针设置成另一个根结点的数组下标。
* 树越来越高导致Find效率变低:为了改善合并以后的查找性能,可以采用小的集合合并到相对大的集合中。(修改Union函数)
* 需要记录集合中元素个数:parent 负数的绝对值可以用来表示根节点下有几个元素