微机系统与汇编语言
文章目录
- 基础知识(历史知识回顾)
- 进制
- 数据转换
- 码制
- 浮点小数
- 浮点型计算方式
- 字符数据
- ASCII码
- Unicode
- 特殊的数据表示
- 80x86微机系统
- 计算机系统
- 硬件组成(由物理元器件构成的数字电路系统):
- 微处理器(MPU)
- 内存储器
- 外存储器
- 外部设备
- 接口电路
- 总线
- 软件:
- 系统软件
- 应用软件
- 总线与主板
- 总线类型结构
- 控制总线(CB)
- 地址总线
- 数据总线
- 总线的层次结构
- CPU总线
- 系统总线
- 局部总线
- 外部总线
- 数据传输
- 存储器
- 内存
- 分类
- 详解
- 优势
- RAM内存器介绍
- SRAM
- DRAM
- 串行存储器
- ROM
- 高速缓冲存储器(Cache)
- 工作原理
- 外部存储器
- 存储器的分段技术
- 存储器寻址
- 物理地址
- 逻辑地址
- 存储单元的地址和内容
- 8086的内部寄存器
- flag标志寄存器详解
- 数据寄存器(就是上面的通用寄存器)
- 地址指针寄存器
- 变址寄存器
- 中央处理机
- 处理器组成(8088)
- 8086的内部结构图
- 指令的执行过程
- 指令执行
- 8086CPU的内部寄存器
- 4个16位段寄存器
- 内存中存放三类信息
- 外部设备
- 寄存器与存储器的对比
- 存储器的逻辑地址与物理地址
- 通用接口
- 专用接口
- 接口的另一种分类
- 接口电路的功能
- 接口电路的基本结构
- I/O端口的编址方式
- CPU与外设数据传送的方式
- 程序传送方式
- 中断传送方式
- DMA传送方式
- 汇编语言
- 指令系统和寻址方式
- 指令系统
- 寻址方式
- 与转移地址有关的寻址方式
- 段内寻址
- 段间寻址
- 段寄存器的使用规定
- 程序格式
- 数据定义
- DOS显示字符串功能
- 数据传送指令
- 累加器专用传送指令
- IN
- OUT
- XLAT/XLAT OPR
- 地址传送指令
- 有效地址传送
- 指针+DS传送
- 指针+ES传送
- 标志寄存器传送指令
- 标志送AH
- AH送标志
- 标志进栈
- 标志出栈
- 类型转换指令
- CBW
- CWD
- 算术指令
- 加法指令
- 减法指令
- 乘法指令
- 除法指令
- 十进制调整指令
- 逻辑指令
- 逻辑运算指令
- 移位指令
- 串处理指令
- 设置方向标志指令
- 串处理指令
- 串重复前缀
- 控制转移指令
- 无条件转移指令
- 条件转移指令
- 循环指令
- 子程序条用和返回指令
- 中断与中断返回指令(仅介绍,建议看书)
- 处理机控制与杂项操作指令
- 标志处理指令
- 其他处理机控制与杂项操作指令
- debug介绍
- DEBUG启动
- debug命令大全(偷个懒,直接截图)
- 地址格式
- 常用的汇编命令
- -A
- -U
- -R
- -D
- -E
- -T
- -G
- 语言格式
- 处理器伪操作(在集成的MASMPLUS中基本不出现)
- 段定义伪操作
- 存储模式与简化段定义伪操作
- MODEL伪操作
- 程序开始和结束伪操作
- 数据定义及存储器分配伪操作
- LABEL伪操作
- 表达式赋值伪操作
- 地址计数器与对准伪操作
- ORG伪操作
- EVEN
- 基数控制伪操作
- 格式
- 表达式操作符
- 算术操作符
- 逻辑和移位操作符
- 关系操作符
- 数值回送操作符
- 属性操作符
- 循环
- 分支
- 子程序
- 过程定义伪操作
- 子程序的调用与返回
- 保存与恢复寄存器
- 子程序的参数传送
- 子程序的嵌套与递归
- I/O端口
- DOS键盘中断(int 21H)
- 高级语言和汇编语言
- 宏汇编
- 子程序与宏定义的对比
- 宏定义的格式
- 宏定义调用的方法
- 宏定义的展开
- 宏汇编操作符
- 重复汇编
- 条件汇编
基础知识(历史知识回顾)
进制
1K=1024= 2 10 2^{10} 210(Kilo)
1M=1024K= 2 20 2^{20} 220(Mega)
1G=1024M= 2 30 2^{30} 230(Giga)
1个二进制位:bit(比特)
8个二进制位:Byte(字节) 1Byte=8bit
2个字节: word(字)
1word=2Byte=16bit
数据转换
十进制->二进制
- 整数除2取余
- 小数乘2取整
八进制->二进制(八进制为中间进制)
- 一位展开成三位
- 三位一分割,查表(从尾部开始分割,前面缺几位补几个)
十六进制->二进制(十六进制为中间进制)
- 一位展开成4位
- 4位一分割,查表(从尾部开始分割,前面缺几位补几个)
码制
原码:
- 最高位符号位,负值为1,正值为0
反码:
- 最高位符号位,负值为1,正值为0
- 负值数值部分取反,正值不变
补码:
- 最高位符号位,负值为1,正值为0
- 负值数值部分取反+1,正值不变
注意部分:87、-87的原码,反码,补码的结果是开放的,因为他没有指定87、-87的数据宽度(就是类型,不知道是几进制)
浮点小数
单精度浮点小数:
32位,4个字节,3个部分,1位符号位,8位阶码,23位尾数
双精度浮点:
64位,8个字节,分成3个部分,1位符号位,11位阶码,52位尾数
计算机内部浮点表达:
80位,10个字节,分成3个部分,1位符号位,15位阶码,64位尾数,没有隐含的1
浮点型计算方式
直接举例吧
-12.5转化
整数12化为二进制1100
小数0.5化为二进制1
因此补全以后就是1100.10000000000000000000(PS:后面补0是因为他是32位,23位的尾数,补成24位是因为最开始的那个1将要隐藏)
小数点前移:1.10010000000000000000000* 2 3 2^{3} 23
阶码为3+127=130(PS:127为偏移量),化为二进制就是10000010
-12.5为负数,因此符号位为1
连起来以后就是1 10000010 10010000000000000000000
后面化成中间进制就不演示了
字符数据
ASCII码
一个字符采用一个字节表示,只用7位,后来增补了128个字符,称为扩展ASCII
Unicode
解决了ASCII码的表达数量不足的问题
16位表示字符,未得到广泛的应用
(老师说未得到广泛应用的原因是每个国家的编码需要把握在自己手上,不能用公用的编码)
注:所以在汇编语言中基本采用ASCII码表示字符
特殊的数据表示
BCD码:
4位二进制位可以表示一个十进制数字
一个字节表示一个,非压缩的BCD
半个字节表示一个,压缩的BCD
知识点:ASCII码可以直接拿来作为非压缩的BCD码
BCD码的作用:
可以直接拿来与外部的输出设备对接,例如:8段显示数码管,精确的大数据表示
计算机的基本分为数据和指令,数据就是以上的类型,指令就是计算机内部用来控制交互的程序
80x86微机系统
计算机系统
硬件组成(由物理元器件构成的数字电路系统):
硬件基本组成依然遵循冯·诺依曼结构:CPU(运算器、控制器)、存储器、I/O设备(输入设备、输出设备)

微处理器(MPU)
将运算器和控制器集成在一片半导体芯片上,叫做中央处理器,在微型计算机中称为微处理器
基本功能:执行程序的指令控制和协调系统中其他部件工作,进行数据运算或传输,完成程序的功能
内存储器
主存或内存,是微型计算机中的存储和记忆装置,用来存放微处理器当前处理的数据和程序
外存储器
- 硬盘
- 光盘
- 由于外存储器速度较慢,在微机系统结构中,外存储器不与微处理器直接进行数据交流,而是通过接口将数据传送到内存才被微处理器访问。
外部设备
I/O设备,提供了人机交互操作的界面
输入设备将外部信息转换为微型计算机能够识别和接受的电信号
输出设备将微型计算机内的信息转换成人或其他设备能接受和识别的形式(如图形、文字和声音等)
常用的输入设备有键盘、鼠标、扫描仪等
常用的输出设备有显示器、打印机等
接口电路
由于I/O设备和微处理器之间存在速度、数据类型、信号格式等差异,因此还需要一个中间部件实现它们之间的信息转换等操作。这个中间部件就是接口电路,也称为适配器。
接口电路两端分别连接微处理器和I/O设备,在它们之间传送数据、状态和控制信息
微信计算机中的显卡、声卡、网卡等,即是微机中的I/O接口部件
总线
微型计算机中,各功能部件之间通过地址总线、数据总线和控制总线相连接
线代微型计算机中的主板(或称母版),便是一块集成电路板,用于固定各部件产品,以及分布各部件之间的连接总线、接口等
软件:
为了使用微机硬件所必备的各种程序和文档的集合,也称为微机系统的软资源
分为:系统软件和应用软件
系统软件
用于管理、监控和维护计算机软件硬件资源,想用户提供一个基本的操作界面,是应用软件的运行环境,是人和硬件系统之间的桥梁
系统软件包括操作系统、监控程序、计算机语言处理程序
应用软件
为了解决用户需求,在数据处理、事务管理、工程设计等时机应用领域开发的各种应用程序
总线与主板
总线类型结构
计算机中连接各部件的一组公共通信线
总线速度是微机性能的主要指标之一
目前在微型计算机中常吧总线作为一个独立的部件看待
微机系统中的I/O接口本质上是I/O设备与微机系统总线的接口
优点:
- 便于采用模块化结构设计方法,简化系统设计
- 标准总线得到各厂商的支持,便于开发相互兼容硬件板卡和软件
- 模块结构便于系统的扩充和升级
- 便于故障诊断和维修

控制总线(CB)
传送一个部件对另一个部件的控制信号
在总线上,可以控制其他部件的部件称为总线主控或总控,被控部件称为从控
根据不同的使用意义,有的为双向,有的为三态(高态、低态、使能态),有的非三态
解释:传送的时序
地址总线
传送地址信号,总线主控用地址信号指定其需要访问的部件(如外设、存储器单元)
总线主控发出地址信号后,总线上所有的部件需感受到该地址信号,但只有竞购译码电路选中的部件才接收主控的控制信号,并与之通信
地址总线的单向的,即地址信号只能由总线主控至从控。地址总线也是三态,非主控部件不能驱动地址总线
解释:内存的大小和外设的访问机制
数据总线
传送数据信息,数据总线是双向的,数据信息可由主控至从控(写),也可以有从控至主控(读)
数据总线是三态的,违背地址信号选中的部件,不驱动数据总线(其数据引脚为高阻)
数据总线的根数称为总线的欢度。16位总线,指其数据总线为16根。
解释:数据宽度
总线的层次结构
组成为CPU总线、系统总线、局部总线、外部总线
CPU总线
CPU、RAM、ROM、控制芯片组(主板中最重要的东西,决定了其他部件是否可替换等)等芯片之间的信号连接关系称为CPU总线,包括控制总线、地址总线和数据总线
CPU总线实现了CPU与主存储器、Cache、控制芯片组、以及多个CPU之间的连接,并提供了与系统总线的接口
注:这个CPU针对具体处理器设计,没有统一的规范 Host Bus连接Second Level Cache和Host-to-PCI Bridge
Host Bus连接Second Level Cache和Host-to-PCI Bridge
Second Level Cache 分为Cache和Tag,Tag是一个标志
Host-to-PCI Bridge是一种高速桥接,对应芯片82349和82439,用来连接DRAM
DRAM是一种高速的随机访问
Host Bus桥接了PCI Bus总线,一直由高速总线连接到外部的慢速设备
系统总线
主机系统(专指CPU+缓存等,与硬盘等存储器无关)与外围设备之间的通行通道
在主板上,系统总线表现为与扩展插槽相连接的一组逻辑电路和导线,所以系统总线也叫I/O通道总线
系统总线必须有统一的标准,以便按标准设计各类适配卡
例如:ISA、EISA、MCA、VESA、PCI、AGP
局部总线
用于主机内部特定子系统之间的紧密连接,设置局部总线的目的是为了提高CPU与高带宽占用部件(如显卡)之间的数据传输速率
PCI、VESA、AGP为局部总线
外部总线
提供I/O设备与系统中其他部件间的公共通信通路
外部总线标准化程度最高,使用各种处理器
SCSI—小型计算机系统接口
USB—通用串行总线
外部总线本质上应该算作主机与外设的接口

ISA总线详解
ISA总线也称为PC总线或XT总线
共有62引脚,其中数据线8根,地址线20根、控制线21根、状态线2根、还有时钟、电源、地线

注:虽然我们区分了总线的种类和层次,但是在实体结构中他们是一个芯片插槽,集成在了一起
- 地址线A19~A0
存储器地址A19~A0,最大存储器1M( 2 20 2^{20} 220计算得到)
I/O地址A15A0,最大64K,在PC机及XT机上世纪使用A9A0,I/O范围为0000~03FFH - 数据线D7~D0
- 控制线21条
AEN:地址允许信号
PC总线可由CPU或DMA控制器控制,当DMAC控制总线时,他产生AEN信号,用于禁止CPU控制总线。即:
AEN=0,CPU控制总线
AEN=1,DMA控制器控制总线
等等具体引脚可搜索查看

数据传输
数据传输由启动方(主控)和目标方(从控)共同完成
所有事件在时钟下降沿同步,在时钟上升沿对信号线采样



存储器
存储器的基本参数:
- 容量:以字节数表示
- 速度:已访问时间 T A T_{A} TA、存储周期 T M T_{M} TM或带宽 B M B_{M} BM表示
- T A T_{A} TA:从接收读申请到读出信息到存储器输出端的实践
- T M T_{M} TM:连续两次启动存储器所需的最小时间间隔 T M < T A T_{M} < T_{A} TM<TA
- B M B_{M} BM: B M = w / T M B_{M}=w/T_{M} BM=w/TM w是数据总线宽度 - 成本:以每位价格表示

从上到下成本越来越低,从左右到速度越来越慢
在CPU内部的两块最贵,分别是寄存器和Cache(高速缓存)
有一部分主板增加了二级Cache,在主板外面,甚至有些主板增加了三级Cache
上图可以看出,寄存器和Cache和连接的,磁盘和磁带是连接的,说明内存和外存是分离的(磁盘是由机械驱动的,所以他的速度受限很大)
外存平均访问时间ms级:
- 硬盘9~10ms
- 光盘80~120ms
内存平均访问时间ns级
- SRAM Cache1~5ns(静态RAM)
- SDRAM内存7~15ns
- EDO内存60~80ns
- EPROM存储器100~400ns(可电擦除的内存)

存储器访问的局部性原理:
解释------存储器访问的局部性指处理器访问存储器时,无论取指令还是取数据,所访问的存储单元都趋向于聚集在一个较小的连续单元区域中。
- 时间上的局部性------最近的将来要用到的信息很可能就是现在正在使用的信息。主要由循环造成
- 空间上的局部性------最近的将要用到的信息很可能与现在正在使用的信息在空间上是邻近的。主要由顺序执行和数据的聚集存放造成(数组造成)
性能由命中率来衡量------对层级结构存储系统中的某一级存储器来说,要访问的数据正好在这一级的概率
内存
分类
RAM
静态RAM(SRAM)
动态RAM(DRAM)
ROM
掩膜型ROM
可编程ROM(PROM)
可擦除可编程ROM(EPROM)
电可擦除可编程ROM( E 2 P R O M E^{2}PROM E2PROM)
详解

优势

RAM内存器介绍

SRAM

注:这个内存只要失去电源连接,上面的内容就会消失,一般用来放在CPU内部构件Cache


DRAM


结构图


串行存储器

就是因为这个串行存储器为后面Flash技术的诞生奠定了基础
注:虽然内存是在CPU中的,但是CPU不会和内存直接连接,都是通过控制芯片控制,也就是说CPU只和控制芯片做交互
ROM



高速缓冲存储器(Cache)
是在内存和CPU之间建立的一个缓存通道,可以弥补CPU和内存之间的速度差异,使得差异变得平稳

工作原理

因为这种方式用的是哈希算法,直接映射到地址,当Cache较小时,命中率会很低,导致效率低


我们不可能一直对于缓存区内的内容无限写入,以及不可能每次都在一块区域内进行操作,一定会使用新的区域,因此我们需要替换算法和写入策略

外部存储器
磁表面存储器和光盘存储器
存储器的分段技术
- 分段技术就是吧1MB空间分成若干逻辑段,每个逻辑段的容量 ≤ \le ≤ 64KB。段内地址是连续的,短语段之间是相互独立的。
- 段基址存放在段寄存器DS,ES,SS或CS中,并表明了相应逻辑段的性质。
- 段内存储单元距离段首地址的偏移量(以字节数计算),叫做偏移地址(EA,有效地址)。偏移地址可以存放在IP,SP,BP,SI,DI,BX中,或者是通过计算给出的一个16位偏移量(PS:这个可以和后面的寻址方式相结合)


存储器寻址
物理地址
- 8086:20根地址线,可以寻址 2 20 ( 1 M B ) 2^{20}(1MB) 220(1MB)个存储单元
- CPU送到地址总线AB上的20位的地址称为物理地址
逻辑地址
- 程序设计中描述地址的规范:<段基址>:<偏移地址>
注:BIU中的地址加法器就是用来实现从逻辑地址到物理地址的变换的

注:从上图可以看出来存储器并不一定是完全分开的,也就是说物理地址可以用多个逻辑地址来表达

各段首地址是物理地址,是20位的,所以要乘以16
存储单元的地址和内容
- 存储器以字节(8bit)为变成单位
- 每个字节单元都有唯一的地址编码
- 地址用无符号整数来表示(变成用16进制表示)
- 一个字节要占用相继的两个字节
- 低位字节存入低地址,高位字节存入高地址
- 字单元地址用它的低地址来表示
- 机器以偶地址访问(读/写)存储器(也就是说不能直接访问01003H地址,需要通过低地址来访问)
8086的内部寄存器
- 8个通用寄存器
数据寄存器(AX,BX,CX,DX)
地址指针寄存器(SP,BP)
变址寄存器(SI,DI)

- 4个段寄存器
- 2个控制寄存器(IP,地址寄存器,内容为下一条要执行的指令的偏移地址;flag,标志寄存器,有状态标志和控制标志,这些标志在下文中文详细解释)
flag标志寄存器详解

现在的:

数据寄存器(就是上面的通用寄存器)
8086含有4个16位数据寄存器,可以分为8个8位寄存器(增加可以操作的寄存器数量)
常用来存放参与运算的操作数或运算结果
- AX:累加器,多用于存放中间运算结果。所有I/O指令都必须通过AX与接口传送信息
- BX:基址寄存器,在间接寻址中用于存放基地址
- CX:计数寄存器,用于在循环或串操作指令中存放循环次数或重复次数
- DX:数据寄存器,在32位乘除法运算时,存放高16位数;在间接寻址的I/O指令中存放I/O端口地址
地址指针寄存器
- SP:堆栈指针寄存器,其内容为栈顶偏移地址
- BP:基址指针寄存器,常用于在访问内存时存放内存单元的偏移地址
注:
- BX与BP作为通用寄存器,二者均可以用于存放数据
- 作为基址寄存器,BX通常用于寻址数据段,BP则通常用于寻址堆栈段
- BX一般与DS或ES搭配使用
变址寄存器
- SI:源变址寄存器
- DI:目标变址寄存器
- 变址寄存器常用语指令的间接寻址或变址寻址。特别是在串操作指令中,用于SI存放源操作数的偏移地址,而用DI存放目标操作数的偏移地址
(源操作数:要操作的对象;目标操作数:用来对操作对象进行操作的数)

中央处理机
处理器组成(8088)
内部结构有两个独立的工作部件
- 执行部件EU(完成计算机运算的部件)
- 总线接口部件BIU (与外设进行数据交换,控制CPU的部件)

ALU为算术逻辑部件,用来完成运算
标志表示当前运算的标志,当前运算的状态
右边是完成运算的最核心部分
左边是为了完成运算而准备的部件,EU中是4组+4个寄存器,整个执行是运用在寄存器中数据完成的
BIU中的指令流字节队列,1-4表示的是4个字节,而不是4条指令,因此其中所能存储的指令条数会随着指令大小的改变而改变
BIU左边的部分有5个寄存器,用来进行地址计算(主要用于针对内存中的地址进行定位)


物理地址(20位)=段基址(16位)*10H(16D)+偏移地址(16位)
8086的内部结构图

指令的执行过程

其中的系统初始化指的是电脑刚刚启动(注意要和软件启动区分开来)
指令执行

8086CPU的内部寄存器
4个16位段寄存器
- CS:代码段寄存器(存放的是指令)
- DS:数据段寄存器(存放的是数据)
- SS:堆栈段寄存器(一个非常重要的概念,用来管控数据,用来存放返回地址,保存寄存器内容传递参数)
- ES:附加数据段寄存器(用来存放额外的数据)
内存中存放三类信息
- 代码,即指令操作码,指出CPU执行什么操作
- 数据,即数值和字符等,程序加工对象
- 堆栈,即临时保存的返回地址和中间结果 (例如:函数返回地址)
外部设备
外设必须通过接口电路与CPU相连接
按通用性分为两类:通用接口和专用接口

寄存器与存储器的对比
- 寄存器:在CPU内部,访问速度快,容量小,成本高,用名字表示,没有地址
- 存储器:在CPU外部,访问速度慢,容量大,成本低,用地址表示,地址可用各种方式形成(较现在的硬盘来说存储器就是容量小成本高,其他都一样)
存储器的逻辑地址与物理地址

通用接口
可供多种外部设备使用的标准接口,目的是使微机正常工作;通用接口通常制造成集成电路芯片,称为接口芯片

专用接口
为某种用途或某类外设而专门哦设计的接口电路,目的在于扩充微机系统的功能
专用接口通常制造成接口卡,插在主板总线插槽上使用
-通用接口和专用接口的界限并不严格
接口的另一种分类
按照可编程性,接口芯片分成硬步线逻辑接口芯片和可编程接口芯片
-可编程接口芯片的功能可以由指令来控制
接口电路的功能
- 缓存锁存数据
针对于输入输出的数据进行缓存,锁存数据的状态(地址啥的) - 地址译码
- 传递命令
- 码制转换
- 电平转换
接口电路的基本结构
接口电路通常包含一组能够与处理器交换信息的寄存器,称为I/O端口寄存器,简称为I/O端口
-数据端口—存放数据信息
-状态端口—存放状态信息,即反映外设当前工作状态的信息
-控制端口—存放控制信息
状态信息与控制信息可以广义的看做数据信息,因此可以通过数据总线传送
I/O端口的编址方式
- I/O端口与存储单元统一编址
- I/O端口独立编址
PC系列机采用I/O端口独立编址方式

端口地址是一种重要资源
端口的寻址 - 把端口地址放在DX寄存器中,对该端口进行读写
IN AL,DX //输入
OUT DX,AL //输出
—可寻址的端口号为0~65535(FFFFH) - 端口地址小于或等于FFH(255),可以用立即数表示端口
IN AL,42H
OUT 43H,AL
CPU与外设数据传送的方式
程序传送方式
CPU与外设间的数据交换在程序控制下进行
(一)无条件传送
- 不查询外设状态,认为外设已经准备就绪,直接与外设传送数据
外设准备就绪
对于输入设备,已经把数据放入接口电路的数据输入寄存器,CPU可以读取
对于输出设备,已经准备好接收数据(接口电路的数据寄存器已空),CPU可以向它输出数据 - 由于不查询外设状态,接口电路不需要状态寄存器输入缓存
- 接口简单,适用于那些能随时读写的设备
(二)程序查询传送
在执行输入输出前,要先查询接口中状态寄存器的状态
输入时,状态寄存器的状态指示要输入的数据是否已经准备就绪
输出时,状态寄存器的状态指示输出设备是否空闲
中断传送方式
使用查询方式,CPU必须检测接口电路的状态寄存器,如果设备为准备好,CPU就要不断地查询,降低了CPU的运行效率
终端方式:当外设作好传送准备后,主动向CPU请求中断,CPU响应中断后在中断处理程序中与外设交换数据。若外设为准备还,CPU可以执行其他程序,提高了CPU的利用率
每条指令完成后,CPU均可响应中断,因此当设备准备好时,可及时与CPU交换数据,提高了实时性
DMA传送方式
对于高速外设(如磁盘、高速A/D),中断方式不能满足数据传输速度的要求
DMA直接存储器访问
DMA方式是一种由专门的硬件电路执行I/O的数据传送方式,它可以让外设接口直接与内存进行高速的数据传送,而不必经过CPU。这种硬件电路称为DMA控制器,简称DMAC
汇编语言
指令系统和寻址方式
指令系统
解释:实际上就是一组指令的集合
指令:操作码—操作数……操作数
操作数有三种:
- 立即数,即常数,在指令中不可改变
- 内存
- 寄存器
寻址方式
解释:用来寻找内存中的数据
| 寻址方式 | 指令 | 解释 | 注意事项 |
|---|---|---|---|
| 立即寻址 | mov AX,3096H | 将3096H传递给AX,一般用来常量赋值 | 其中3096H这样的立即数只能用来赋值给AX,不能将AX赋值给立即数;立即数要和AX的长度一样 |
| 寄存器寻址 | mov AL,BH | 将BH中的内容传递给AL(BH,AL可以查看上文中寄存器的解释) | 字节寄存器只有AX,BX,CX,DX以及他们的字单元;用来赋值的寄存器需要和被赋值的字长一样;CS,IP不能使用mov指令改变 |
| 直接寻址 | mov AX,[2000H] | 物理地址=DS*10H+2000H以DS作为段基址,[2000H]作为偏移量,将计算得出的物理地址的内容赋值给AX | DS为隐含的段基址;可以使用其他段基址来代替,需要改成mov AX,ES:[3000H];操作数可以使用变量代替,但是要注意变量的属性VALUE DB 10—mov AX,WORD PTR VALUE(WORD PTR将VALUE转化为字单元) |
| 寄存器间接寻址 | mov AX,[BX]/ES:[BX] | 物理地址=DS*10H+BX以DS作为段基址,BX中的内容作为偏移量,将计算得出的物理地址的内容赋值给AX(EA在基址寄存器中(BX/BP)或变址寄存器中(SI/DI),使用BP是段基址的默认段寄存器为SS) | 不允许使用AX,CX,DX存放EA,SRC和DST(源操作数和目的操作数)的字长一致,适用于数组,字符串,表格的处理 |
| 寄存器相对寻址 | mov AX,COUNT[SI] /[COUNT+SI] | 物理地址=DS*10H+COUNT(BX/BP/SI/DI)段基址+SI偏移量 | 适用于数组,字符串,表格的处理 |
| 基址变址寻址 | mov AX,[BX] [DI]/[BX+DI]/ES:[BX][SI] | 物理地址=DS*10H+BX/BP+SI/DI | 适用于数组,字符串,表格的处理;必须是一个基址寄存器(BP/BX),一个变址寄存器(SI/DI) |
| 相对基址变址寻址 | mov AX,MASK[BX][SI]/MASK[BX+SI]/[MASK+BX+SI] | 物理地址=DS*10H+BX/BP+SI/DI+MASK偏移量 | 同基址变址寻址 |
与转移地址有关的寻址方式
确定转移指令:针对一个程序对应位置的地址的确定
JUMP指令:无条件跳转,无条件将下一条我们要执行的指令迁移到JUMP后面的地址中
注:要注意跳转的跨度为多大,跨度大于范围时跨度变为负数,向上跨越,例如short 0C6H,0C6H大于127,因此为负
段内寻址
- 段内直接寻址:JMP NEAR PTR NEXT;有效地址:当前(IP)+位移量(8/16bit)
NEXT解释:这是一个语句标号,默认为FAR PTR,代表了符号地址


例如上图:使用了JMP 0010后,指令的地址由12A2:0005->12A2:0010,就是IP(0007)+偏移量(09),09是由EB09得来,其中EB是操作码,09是由0010经过计算机转换以后得来,当前IP是由当前位置的下一条指令所在,即指令所在位置为0005,IP为0007 - 段内间接寻址:JMP TABLE[BX]

段间寻址
- 段间直接寻址 JMP FAR PTR NEXT
用指令中提供的转向段地址和偏移地址取代CS和IP - 段间间接寻址 JMP DWORD PTR[BX]

段寄存器的使用规定
| 访问存储器的方式 | 默认的段存储器 | 可跨越的段寄存器 | 偏移地址 |
|---|---|---|---|
| 取指令 | CS | 无 | IP |
| 堆栈操作 | SS | 无 | SP |
| 一般数据访问 | DS | CS ES SS | 有效地址EA |
| BP作为基址的寻址 | SS | CS DS ES | BP |
| 串操作的源操作数 | DS | CS ES SS | SI |
| 串操作的目的操作数 | ES | 无 | DI |
程序格式
数据定义
DATA SEGMENT(数据段,象征着下面是数据定义部分)
STRING(变量名) DB 'HAPPY NEW YEAR!',0DH(回车),0AH(换行),'$'(在汇编语言中作为字符串的结束符)
COUNT DW 17(定义STRING变量的长度15+1+1)
DATA ENDS(数据段结束,象征着数据定义部分截止)
注:()中的内容是对于代码的理解;在汇编语言中单引号和双引号的效果是一样的
DOS显示字符串功能
mov dx,offset string ;string的偏移地址->dx(offset的作用)
;lea dx,string
mov ah,9
int 21h ;显示一串字符
注:80x86还有新增的寻址方式,详情可以查看IBM-PC第二版中内容
数据传送指令
通俗理解为赋值语句
注:在汇编中并没有数据类型,因此下列指令要求两个参数的数据长度要一致
- 数据传送指令
mov、push、pop、xchg - 累加器专用传送指令
in、out、xlat - 地址传送指令
lea、lds、les - 标志寄存器传送指令
lahf、sahf、pushf、popf - 类型转换指令
cbw、cwd
| 指令名称 | 传送指令 | 执行操作 | 注意事项 |
|---|---|---|---|
| 传送指令 | MOV DST,SRC | DST(内存/寄存器)<-SRC(SRC中的值,立即数/寄存器/存储器) | DST、SRC不能同时为段寄存器;立即数不能直接送段寄存器;DST不能是立即数和CS;DST、SRC不能同时为存储器寻址(为了减少执行周期);不影响标志位 |
| 进栈指令 | PUSH SRC | SP<-SP-2,(SP+1,SP)<-SRC(将SRC的内容存入堆栈中) | 堆栈:先进后出的存储区,段地址存放在SS中,SP任何时候都只想栈顶,进出站后自动修改SP;堆栈操作必须以字为单位;不影响标志位;不能用立即寻址方式(即不能使用PUSH 1234H);DST不能是CS(即不嗯呢该使用POP CS) |
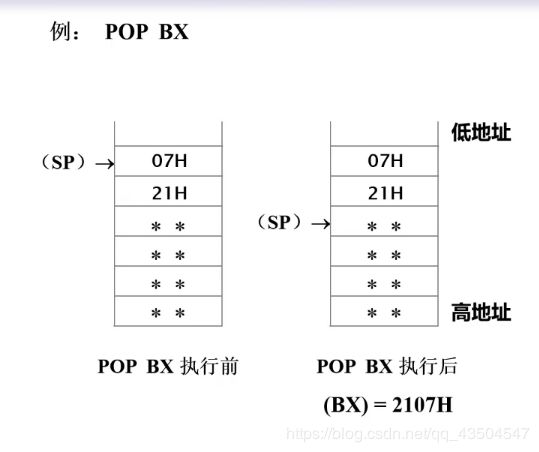
| 出栈指令 | POP DST | (DST)<-(SP+1,SP);SP<-SP+2 | 注意事项同进栈指令 |
| 交换指令 | XCHG OPR1,OPR2 | OPR1<->OPR2 | 不影响标志位;不允许使用段寄存器 |
- PUSH 举例

- POP举例
累加器专用传送指令
外设与CPU之间的信息传输指令
IN
输入指令 IN (I/O->CPU)
长格式:
IN AL,PORT(字节)
IN AX,PORT(字)
执行操作:
(AL)<-(PORT)
(AX)<-(PORT+1,PORT)
短格式:
IN AL,DX(字节)
IN AX,DX(字)
执行操作:
(AL)<-((DX))
(AX)<-((DX)+1,(DX))
OUT
输出指令 OUT(CPU->I/O)
长格式:
OUT PORT,AL(字节)
OUT PORT,AX(字)
执行操作:
(PORT)<-(AL)
(PORT+1,PORT)<-(AX)
短格式:
OUT DX,AL(字节)
OUT DX,AX(字)
执行操作:
((DX))<-(AL)
((DX)+1,(DX))<-(AX)
注:
- 不影响标志位
- 前256个端口号00H~FFH可直接在指令中指定(长格式)
- 如果端口号 ≥ \ge ≥ 256,端口号->DX(短格式)

XLAT/XLAT OPR
执行操作:(AL)<-((BX)+(AL))
MOV BX,OFFSET TABLE;(BX)=0040H
MOV AL,3
XLAT TABLE
注意:
- 不影响标志位
- 字节表格(长度不超过256)首地址->(BX)
- 需转换的代码位移量->(AL)

地址传送指令
有效地址传送
有效地址送寄存器指令:LEA REC,SRC
执行操作:(REG)<-SRC
LEA给的是SRC的偏移地址
指针+DS传送
指针送寄存器和DS操作:LDS REG,SRC
执行操作:
(REG)<-(SRC)
(DS)<-(SRC+2)
相继二字->寄存器+DS
LDS给的是SRC的内容
指针+ES传送
指针送寄存器和ES指令:LES REG,SRC
执行操作:
(REG)<-(SRC)
(ES)<-(SRC+2)
相继二字->寄存器+ES
LDS给的是SRC的内容

MOV BX,OFFSET TABLE将TABLE的偏移地址给BX
注:
- 不影响标志位
- REG不能是段寄存器
- SRC必须为存储器寻址方式
标志寄存器传送指令
标志送AH
标志送AH指令:LAHF
执行操作:(AH)<-(FLAGS的低字节)
AH送标志
AH送标志寄存器指令:SAHF
执行操作:(FLAGS的低字节)<-(AH)
标志进栈
标志进栈指令:PUSHF
执行操作:
(SP)<-(SP)-2
((SP)+1,(SP))<-(FLAGS)
标志出栈
标志出栈指令:POPF
执行操作:
(FLAGS)<-((SP)+1,(SP))
(SP)<-(SP)+2
注:影响标志位
类型转换指令
CBW
CBW AL ->AX
执行操作:
若AL的最高有效位为0,则AH=00H
若AL的最高有效位为1,则AH=FFH
CWD
CBW AX ->(DX,AX)
执行操作:
若AX的最高有效位为0,则DX=0000H
若AX的最高有效位为1,则DX=FFFFH

注:
- 无操作数指令
- 隐含对AL或AX进行符号扩展
- 不影响条件标志位

答案为ABD
算术指令
标志位:
S F = { 0 结果为负 1 否则 Z F = { 0 结果为0 1 否则 SF= \begin{cases} 0& \text{结果为负}\\ 1& \text{否则} \end{cases} ZF= \begin{cases} 0& \text{结果为0}\\ 1& \text{否则} \end{cases} SF={01结果为负否则ZF={01结果为0否则
C F = { 0 和的最高有效位有向高位的进位 1 否则 CF= \begin{cases} 0& \text{和的最高有效位有向高位的进位}\\ 1& \text{否则} \end{cases} CF={01和的最高有效位有向高位的进位否则
O F = { 0 两个操作数符号相同,而结果符号与之相反 1 否则 OF= \begin{cases} 0& \text{两个操作数符号相同,而结果符号与之相反}\\ 1& \text{否则} \end{cases} OF={01两个操作数符号相同,而结果符号与之相反否则
CF表示无符号数相加的溢出
OF表示带符号数相加的溢出
无符号数:数的第一位不是符号位(-128~127)
有符号数:数的第一位是符号位(0~255)
加法指令
加法指令:ADD DST,SRC
执行操作:(DST)<-(SRC)+(DST)
带进位加法指令:ADC DST,SRC
执行操作:(DST)<-(SRC)+(DST)+CF
加1指令:INC OPR
执行操作:(OPR)<-(OPR)+1
注:除INC指令不影响CF标志外,均对条件标志位有影响

减法指令
减法指令:SUB DST,SRC
执行操作:(DST)<-(DST)-(SRC)
带借位减法指令:SBB DST,SRC
执行操作:(DST)<-(DST)-(SRC)-CF
减1操作:DEC OPR
执行操作:(OPR)<-(OPR)-1
求补指令:NEG OPR
执行操作:OPR<–(OPR)
比较指令:CMP OPR1,OPR2
执行操作:(OPR1)-(OPR2)
此项指令会返回一个状态位,并不会修改操作数
注:除DEC指令不影响CF标志外均对条件标志位有影响
减法指令对条件标志位的影响:
C F = { 0 被减数的最高有效位有向高位的借位 1 否则 CF= \begin{cases} 0& \text{被减数的最高有效位有向高位的借位}\\ 1& \text{否则} \end{cases} CF={01被减数的最高有效位有向高位的借位否则
或
C F = { 0 减法转换为加法运算时无进位 1 否则 CF= \begin{cases} 0& \text{减法转换为加法运算时无进位}\\ 1& \text{否则} \end{cases} CF={01减法转换为加法运算时无进位否则
O F = { 0 两个操作数符号相反,而结果的符号与减数相同 1 否则 OF= \begin{cases} 0& \text{两个操作数符号相反,而结果的符号与减数相同}\\ 1& \text{否则} \end{cases} OF={01两个操作数符号相反,而结果的符号与减数相同否则
CF位表示无符号数减法的溢出
OF位表示带符号数减法的溢出
NEG指令对CF/OF的影响:
C F = { 0 操作数为0 1 否则 CF= \begin{cases} 0& \text{操作数为0}\\ 1& \text{否则} \end{cases} CF={01操作数为0否则
O F = { 0 操作数为-128或-32768(字节或字运算) 1 否则 OF= \begin{cases} 0& \text{操作数为-128或-32768(字节或字运算)}\\ 1& \text{否则} \end{cases} OF={01操作数为-128或-32768(字节或字运算)否则
乘法指令
无符号数乘法指令:MUL SRC
带符号数乘法指令:IMUL SRC
执行操作:
字节操作:(AX)<-(AL)*(SRC)
字操作:(DX,AX)<-(AX)*(SRC)
注:
- AL(AX)为隐含的乘法寄存器
- AX(DX,AX)为隐含的乘积寄存器
- SRC不能为立即数
- 除CF和OF外,对条件标志位无定义(不能作为判定的依赖,无影响是对标志位没有设置)
乘法指令对CF/OF的影响:
MUL指令:
C F , O F = { 00 乘积的高一半为0,即高八位全为0 11 否则 CF,OF= \begin{cases} 00& \text{乘积的高一半为0,即高八位全为0}\\ 11& \text{否则} \end{cases} CF,OF={0011乘积的高一半为0,即高八位全为0否则
IMUL指令:
C F , O F = { 00 乘积的高一半是低一半的符号扩展,即若一开始符号位为1,IMUL后搞八位也为1 11 否则 CF,OF= \begin{cases} 00& \text{乘积的高一半是低一半的符号扩展,即若一开始符号位为1,IMUL后搞八位也为1}\\ 11& \text{否则} \end{cases} CF,OF={0011乘积的高一半是低一半的符号扩展,即若一开始符号位为1,IMUL后搞八位也为1否则

除法指令
无符号数除法指令:DIV SRC
带符号数除法指令:IDIV SRC
执行操作:
字节操作:
(AL)<-(AX)/(SRC)的商
(AH)<-(AX)/(SRC)的余数
字操作:
(AX)<-(DX,AX)/(SRC)的商
(DX)<-(DX,AX)/(SRC)的余数
注:
- AX(DX,AX)为隐含的被除数寄存器
- AL(AX)为隐含的商寄存器
- AH(DX)为隐含的余数寄存器
- SRC不能为立即数
- 对所有条件标志位均无定义
十进制调整指令
在压缩的BCD码进行加法计算时,需要再加入110,如下图所示:

逻辑指令
逻辑运算指令
逻辑非指令:NOT OPR
执行操作:OPR<-(-OPR)
注:
OPR不能为立即数
不影响标志位
逻辑与指令:AND DST,SRC
执行操作:(DST)<-(DST) ∧ \land ∧(SRC)
逻辑或指令:OR DST,SRC
执行操作:(DST)<-(DST) ∨ \lor ∨(SRC)
异或指令:XOR DST,SRC
执行操作:(DST)<-(DST) ⊙ \odot ⊙(SRC)
测试指令:TEST OPR1,OPR2
执行操作:(OPR1) ∧ \land ∧(OPR2)
CF、OF为0
SF、ZF、PF根据结果设置
AF无定义
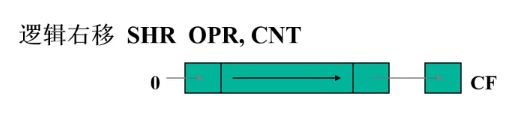
移位指令
汇编语言中最快的运算
逻辑左移:SHL OPR,CNT

逻辑右移:SHR OPR,CNT
算术左移:SAL OPR,CNT
同逻辑左移
算术右移:SAR OPR,CNT

循环左移:ROL OPR,CNT

循环右移:ROR OPR,CNT

带进位循环左移:RCL OPR,CNT

带进位循环右移:RCR OPR,CNT

注:
- OPR可用除立即数以外的任何寻址方式
- CNT=1,SHL OPR,1
- CNT>1:
MOV CL,CNT
SHL OPR,CL;以SHL为例 - 条件标志位:
CF=移入的数值
O F = { 1 CNT=1时,最高有效位的值发生变化 0 CNT=1时,最高有效位的值不变 OF= \begin{cases} 1& \text{CNT=1时,最高有效位的值发生变化}\\ 0& \text{CNT=1时,最高有效位的值不变} \end{cases} OF={10CNT=1时,最高有效位的值发生变化CNT=1时,最高有效位的值不变
也就是说当CNT>1时,OF无效 - 移位指令:SF、ZF、PF根据移位结果设置,AF无定义
- 循环移位指令:不影响SF、ZF、PF、AF
串处理指令
设置方向标志指令
CLD、STD
串处理指令
MOVS DST,SRC
MOVSB(字节)
MOVSW(字)
例:MOVS ES:BYTE PTR [DI],DS:[SI]
执行操作:
- (DI)<-(SI)将SI中的内容复制给DI
- 字节操作: ( S I ) ← ( S I ) ± 1 , ( D I ) ← ( D I ) ± 1 (SI)\leftarrow(SI)\pm1,(DI)\leftarrow(DI)\pm1 (SI)←(SI)±1,(DI)←(DI)±1
字操作: ( S I ) ← ( S I ) ± 2 , ( D I ) ← ( D I ) ± 2 (SI)\leftarrow(SI)\pm2,(DI)\leftarrow(DI)\pm2 (SI)←(SI)±2,(DI)←(DI)±2
方向标志DF=0时用+,DF=1时用-
REP MOVS:将数据段中的整串数据传送到附加段中。
源串(数据段) → \rightarrow →目的串(附加段)
执行REP MOVS之前,应先做好:
3. 源串首地址(末地址) → \rightarrow →SI
4. 目的串首地址(末地址) → \rightarrow →DI
5. 串长度 → \rightarrow →CX
6. 建立方向标志(CLD是DF=0,STD使DF=1)

当从尾部开始赋值时

当传递的是WORD(字)时,需要把CX/2,因为字=2字节(当然,这有可能会导致最后一位字母是否传递过去,看最后一位是奇数还是偶数)

STOS存入串指令:
STOS DST
STOSB(字节)
STOSW(字)
将内容存储到存储器
执行操作:
字节操作:(DI) ← \leftarrow ←(AL),(DI) ← \leftarrow ←(DI) ± \pm ± 1将AL的值存放到DI中,
字操作:(DI) ← \leftarrow ←(AX),(DI) ← \leftarrow ←(DI) ± \pm ± 2

LODS从串取指令:
LODS SRC
LODSB(字节)
LODSW(字)
执行操作:
字节操作:(AL) ← \leftarrow ←(SI),(SI) ← \leftarrow ←(SI) ± \pm ± 1
字操作:(AX) ← \leftarrow ←(SI),(SI) ± \pm ± 1
注:
- LODS指令一般不予REP联用
- 源串一般在数据段中(允许使用段跨越前缀来修改),目的串不许在附加段中
- 不影响条件标志位
串重复前缀
REP
执行操作:
- 如果CX=0,则退出REP,否则进行2
- CX<-CX-1
- 执行MOVS/STOS/LODS
- 重复1~3
REPE/REPZ
REPNE/REPNZ
执行操作:
- 如(CX)=0或ZF=0(ZF=1)则退出串操作,否则转2
- (CX) ← \leftarrow ← (CX)-1
- 执行CMPS/CSAS
- 重复1~3
CMPS串比较指令:
CMPS SRC,DST
CMPSB(字节)
CMPSW(字)
执行操作:
- (SI)-(DI)根据比较结果设置条件标志位:相等ZF=1;不等ZF=0
- 字节操作:SI ← \leftarrow ←SI ± \pm ± 1,DI ← \leftarrow ← DI ± \pm ± 1
字操作:SI ← \leftarrow ←SI ± \pm ± 2,DI ← \leftarrow ← DI ± \pm ± 2
SCAS串扫描指令:
SCAS DST
SCASB(字节)
SCASW(字)
执行操作:
字节操作:(AL)-(DI),DI ← \leftarrow ←DI ± \pm ± 1
字操作:(AX)-(DI),DI ← \leftarrow ←DI ± \pm ± 2

控制转移指令
无条件转移指令
段内直接短转移:JMP SHORT OPR
执行操作:IP ← \leftarrow ← IP+8位位移量
注:IP为下一条指令位置(例如:现在在0010,即IP为0012)
段内直接近转移:JMP NEAR PTR OPR
执行操作:IP ← \leftarrow ←IP+16位位移量
段内间接转移:JMP WORD PTR OPR
执行操作:IP ← \leftarrow ←EA
段间直接远转移:JMP FAR PTR OPR
执行操作:
IP ← \leftarrow ←OPR的段内偏移地址
CS ← \leftarrow ←OPR所在段的段地址
段间间接转移:JMP DWORD PTR OPR
执行操作:
IP ← \leftarrow ←EA
CS ← \leftarrow ←EA+2
条件转移指令
注:只能使用段内直接寻址的8位位移量
- 根据单个条件标志的设置情况转移
{ J Z ( J E ) O P R ZF=1 J N Z ( J N E ) O P R ZF=0 \begin{cases} JZ(JE)\ \ \ \ OPR& \text{ZF=1}\\ JNZ(JNE)\ \ \ \ OPR& \text{ZF=0} \end{cases} {JZ(JE) OPRJNZ(JNE) OPRZF=1ZF=0
{ J S O P R SF=1 J N S O P R SF=0 \begin{cases} JS\ \ \ \ OPR& \text{SF=1}\\ JNS\ \ \ \ OPR& \text{SF=0} \end{cases} {JS OPRJNS OPRSF=1SF=0
{ J O O P R OF=1 J N O O P R OF=0 \begin{cases} JO\ \ \ \ OPR& \text{OF=1}\\ JNO\ \ \ \ OPR& \text{OF=0} \end{cases} {JO OPRJNO OPROF=1OF=0
{ J O O P R PF=1 J N O O P R PF=0 \begin{cases} JO\ \ \ \ OPR& \text{PF=1}\\ JNO\ \ \ \ OPR& \text{PF=0} \end{cases} {JO OPRJNO OPRPF=1PF=0
{ J C O P R CF=1 J N C O P R CF=0 \begin{cases} JC\ \ \ \ OPR& \text{CF=1}\\ JNC\ \ \ \ OPR& \text{CF=0} \end{cases} {JC OPRJNC OPRCF=1CF=0 - 比较两个无符号数,并根据比较结果转移
< < < JB(JNAE,JC) OPR CF=1
≥ \ge ≥ JNB(JAE,JNC) OPR CF=0
≤ \le ≤ JBE(JNA) OPR CF ∨ \lor ∨ZF=1
> > > JNBE(JA) OPR CF ∨ \lor ∨ZF=0
适用于地址或双精度低位字的比较 - 比较两个带符号数,并根据比较结果转移
< < < JL(JNGE) OPR SF ⊙ \odot ⊙OF=1
≥ \ge ≥ JNL(JGE) OPR SF ⊙ \odot ⊙OF=0
≤ \le ≤ JLE(JNG) OPR (SF ⊙ \odot ⊙OF) ∨ \lor ∨ZF=1
> > > JNLE(JG) OPR (SF ⊙ \odot ⊙OF) ∨ \lor ∨ZF=0
适用于带符号数的比较 - 测试CX的值为0则转移
JCXZ OPR CX=0

循环指令
注:
- CX中存放循环次数
- 只能使用段内直接寻址的8位位移量
LOOP
LOOPZ/LOOPE
LOOPNZ/LOOPNE
执行步骤:
- CX ← \leftarrow ←CX-1(只能用CX,不能用CL,CH)
- 检查是否满足测试条件,如满足则IP ← \leftarrow ←IP+8位位移量,实行循环;不满足则IP不变,退出循环
只有最多56/57次跳转,多了就不行了
循环指令:LOOP OPR
测试条件:CX ≠ \not= = 0
为0或相等时循环指令:LOOPZ(LOOPE) OPR
测试条件:ZF=1且CX ≠ \not= = 0
不为0或不相等时循环指令:LOOPNZ(LOOPNE) OPR
测试条件:ZF=0且CX ≠ \not= = 0

子程序条用和返回指令
中断与中断返回指令(仅介绍,建议看书)
形式:INT 中断号(对应实际转移的入口地址)
处理机控制与杂项操作指令
标志处理指令
CLC:CF ← \leftarrow ← 0
CMC:CF ← \leftarrow ← -CF
STC:CF ← \leftarrow ← 1
CLD:DF ← \leftarrow ← 0
STD:DF ← \leftarrow ← 1
CLI:IF ← \leftarrow ← 0
STI:IF ← \leftarrow ← 1
注:只影响本指令指定的标志位
其他处理机控制与杂项操作指令
NOP:无操作(机器码占一个字节)
HLT:暂停机(等待一次外中断,之后继续执行程序)
WAIT:等待(等待外中断,之后仍继续等待)
ESC:换码
LOCK:封锁(维持总线的锁存信号,知道其后的指令执行完)
注:不影响标志位
debug介绍
- DEBUG是专门为汇编语言设计的一种调试工具,他通过单步执行、设置断点等方式为汇编语言程序员提供了非常有效的调试手段
- DEBUG命令都是用单个字母表示的,其后可跟一个或多个参数。字母和参数之间可以不留空格,参数之间用空格或逗号分隔,命令和参数可以用大写、小写或混合方式输入
- DEBUG命令中输入的数据和显示的数据都是十六进制数,数据后面的H后缀省略
- DEBUG命令参数多数是地址或地址范围
DEBUG启动
- 32位的系统可以直接在模拟dos环境下启动(一般64位系统需要在虚拟机中使用)

- 所有的命令都是在提示符-后输入
- 在64位计算机中可以使用dosbox虚拟机

- 直接选中dos.exe,启动后,需要输入指令,手动建立虚拟盘和目录之间的对应关系,如图中mount所示
- 在虚拟dos环境下,执行debug的执行文件

- 吧虚拟盘映射到开发环境的源目录
debug命令大全(偷个懒,直接截图)

地址格式
- 具体地址
段地址:偏移地址
段地址可以是段寄存器或十六进制段址
例如:DS:200;1A09:200 - 地址范围的格式
段地址:起始偏移地址 终止偏移地址
例如:CS:200 3FF
段地址:起始偏移地址 L长度
例如:CS:200 L100
常用的汇编命令
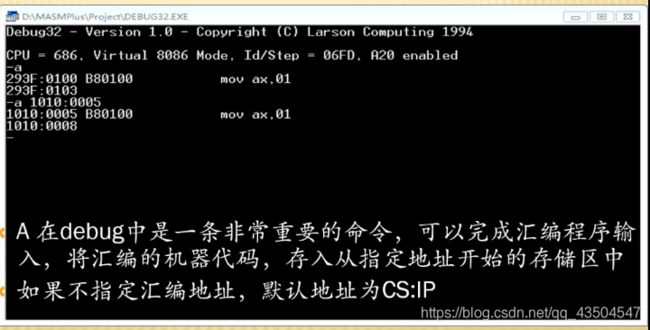
-A
用来完成汇编程序输入,将汇编的机器代码,存入指定地址开始的存储区中,如果不指定汇编地址,默认地址为CS:IP
适用范围:测试单条指令的作用
-U
U命令是将指定地址的机器代码翻译成汇编语言指令显示出来。如果未规定地址,则以上一个U命令的最后一条指令的地址作为下一条反汇编的起始地址,这样就可以进行连续的反汇编
如果前面没有用过U命令,则以DEBUG初始化的CS段寄存器作为段地址
-R
R命令是显示和修改CPU中寄存器的内容,或显示和修改标志寄存器的值。当R命令后面不带任何参数时,显示CPU内所有寄存器的内容
当R命令后面带参数时,显示该寄存器的内容,同时又可以进行修改
-D
D命令是显示指定地址或地址范围内存储单元的内容。D命令中地址的给定分三种情况
- 在输入的起始地址中,只输入一个相对偏移量,段地址在DS中。
- 若要显示指定范围的内容,则要输入显示的起始地址和结束地址
- 如果用D命令时没有指定地址,则当前D的开始地址是前一个D命令所显示的最后单元的后面的单元地址
-E
E命令是在指定的地址里修改一个或多个字节的内容,同时也可连续地修改多个字节的内容
具体修改策略如下三种情况:
- 连续修改多个字节的内容
- 用给定的内容代替指定范围的内存单元内容
- 输入一个连接号——,则显示前一个地址单元的内容。若修改就输入一个字节。然后按——,则显示前一个地址单元的内容。若显示的单元不修改,则按——。
-T
T命令是从起始地址开始跟踪执行指定条数的指令,美之心一条指令,显示所有寄存器内容、状态标志和一条要执行的指令
-G
G命令从起始地址开始,到终止地址结束的程序。如果程序能够正常执行到结束,则显示当前寄存器的执行结果以及下一条要执行的指令。
G命令使用中要注意一下几点:
- 一旦程序运行结束(DEBUG显示"Program teminated normally"信息),在他再次执行之前,必须重新启动程序
- 地址参数指向的位置必须含有合法的指令,如果指定第一个字节为非法指令,则可能出现不可预料的结果
- 堆栈指示器必须是合法的
语言格式


处理器伪操作(在集成的MASMPLUS中基本不出现)

段定义伪操作

在MASMPLUS中会将data segment简写成.data(用前一种方式可以不使用名字为data,可以命名,但是采用.data的简写方式就只能是.data不能另起名字)
assume是完成初始化,将code的段地址放到cs中,data的段地址放到ds中,extra的段地址放到es中

看两段代码的结尾有所不同:左边的代码结尾是ret,右边的代码就是int 21h,他们的区别就是ret并不能中断程序,而int 21h就是中断程序的方式
以及end start中的start一定是符号名称,表示一段程序开始的点

上面是段定义的方式,对于[]中的类型老师并未多做解释,等到下次看到并且想起来的时候再来记录,老师解释:使用这些类型的前提是将汇编语言作为一种独立开发的语言来使用,而到目前为止,汇编语言的使用越来越偏向于与其他语言结合,增强其他语言的效率,因此这些知识逐渐变得没有应用场景
存储模式与简化段定义伪操作
MODEL伪操作

.code是可以有多个的,因此在.code后面可以跟名字
.data是简化的data segment,他只能有一个,不可以有多个
.data?是表明没有初始化的数据
.fardata表名这个数据段是一个远程的数据段
.fardata?同样也是没有初始化的远程数据段
.const是一个常量数据段,里面存放的数据全是常量,不具有修改的可能性
.stack是堆栈段,后面的size表示你手动定义的堆栈的大小
下面是代码示例:
;#Mode=DOS
;MASMPlus 单文件代码模板 - 纯 DOS 程序
;--------------------------------------------------------------------
;单个文件需要指定编译模式,否则默认是EXE方式,在系统设置中可以设置默认是DOS还是Windows.
;编译模式自带了DOS/COM/CON/EXE/DLL/LIB这几种,如果有必要,可以更改ide.ini添加新的编译模式
;当然,更好的是创建为一个工程.更方便及易于管理,使用方法:按Ctrl多选->创建工程.必须有多个文件
;上面分号后面的内容都是注释,用来解释代码
;下面开始解释,为什么与上面的segment不同,没有end,因为他每一个段的开始都会自动结束上一个段,因此简化后可以不写end
.model small;这是model伪操作,后面的small是存储模式
.stack 200h
.data
szMsg db 'Hello World!',13,10,'$'
.CODE
START:
mov ax,@data
mov ds,ax
lea dx,szMsg
mov ah,9
int 21h
;暂停,任意键关闭
mov ah,1
int 21h
mov ah,4ch ;结束,可以修改al设置返回码
int 21h
END START

可以从上图看到简化的伪操作,大部分都已经在上面有过解释,其中的.startup可以对应到mov ax,@data~ mov ds,ax;.exit 0可以对应到mov ax,4c00h~end start
下面的DGROUP的作用是当数据段未加声明的时候会将所有数据放到GROUP中去,构成一个数据段的组,浅尝辄止,暂时对目前授课没有任何意义,但是示例如下:


程序开始和结束伪操作

虽然对于授课没有意义,但是还是要介绍一下:
TITLE:标题,在代码段中没有什么意义,但是在生成.list文件时,会用到这个
NAME:model_name,用来表明这个model的命名
END:就是前面代码中常见的end start,用来表明这段程序的起始点
数据定义及存储器分配伪操作

DB(real4):1字节
DW:2字节
DD:4字节
DF:6字节
DQ(real8):8字节
DT:10字节
右图是数据在存储器中的存储方式,从上到下是从低到高,?代表了不赋值,存储器中仍然是原来的值,而负值代如的时候我们需要将它变成补码的形式(由此可知求补码的时候符号位不变),以及要注意?的数据长度

上边是一个数组的定义,其中有一个需要记忆的地方就是DW ‘AB’,他与平常定义相反,会将B放到低8位,将A放到高8位,且这个DW只能放两个字节,就是如右图所示的样子
下面的对于ADDR_TABLE的存储存入的是PAR1和PAR2的偏移地址,而不是它们的内容
当ADDR_TABLE DD时,存放的PAR1和PAR2放的是他们的段地址和偏移地址
VAR中的内容就是将DUP()中的内容重复100次,如果是?就像上面说的开空间但是数据不变,DUP()中可以有多个数据,像后面那个定义所示

上面是针对变量定义的解释:当我们将OPR定义为字节时,赋值给0时,也是字节,定义为字时,0也是字。当然汇编的赋值规定不能破,两个值必须长度一样才能赋值,因此下面出现了类型不匹配的错误,图中也给出了解决方式,那就是将OPR的类型进行强制改变
| 高级语言(C++) | 汇编语言(x86) |
|---|---|
| 变量 | 符号地址 |
| 常量 | Name type ?(不初始化),value, dup(重复) |
| Char | DB(byte, sbyte) |
| Int(short, int, long) | DB,DW,DD,DF,DQ,DT |
| float | DB(dword,sdword,real4) |
| double | DQ(qword,sqword,real8)DF(fword,sfword)DT(tword,stword) |
| 指针 | 寻址方式 |
| 顺序语句 | |
| 分支语句 if else/switch | jx,jnx(状态位CF,SF,OF,ZF,PF) |
LABEL伪操作
LABEL伪操作:name LABEL type
LABEL仅仅代表一个标号,并不会有空间,会和他下面的指令指向同一位置

LABEL与WORD_ARRAY的区别:使用LABEL访问的话使用字节访问的,使用WORD_ARRAY是用字访问的
tos是自定义设置的栈顶
表达式赋值伪操作
表达式名 EQU 表达式(不允许重复定义)
ALPHA EQU 9
BETA EQU ALPHA+18
BB EQU [BP+8]
"="伪操作(允许重复定义)
EMP =7
EMP=EMP+1
地址计数器与对准伪操作
地址计数器$:保存当前正在汇编的指令的地址
ORG $+8;跳过8个字节的存储区
JNE $+6;转向地址是JNE的首地址+6(当JNE成立时,地址跳到当前地址的后六条指令)
JMP $+2;转向下一条指令
$用在伪操作的参数字段:
表示地址计数器的当前值

ORG伪操作

可以从ORG 10中看出,VAR1的首地址就是000A
从ORG 20中得出,VAR2的首地址是0014,而ORG $+8,VAR3的首地址是001E(0016+8)
上图中的框内指令时相等的:
BUFFER LABEL BYTE
ORG $+8
BUFFER DB 8 DUP(?)
EVEN

A DB ‘morning’
EVEN
B DW 2 DUP(?)
使B的首地址变为偶地址开始
基数控制伪操作
.RADIX 表达式;规定无标记数的基数
默认的情况为10进制(用.RADIX设置默认的进制)

注:上文中178D也是一个16进制数,计算机会认为十进制178,178时会变成0178H
格式

表达式操作符
算术操作符
+、-、*、/、Mod
这些在机器语言中不复存在,是伪指令的一种变种形式

注:符号地址可以进行 ± \pm ±操作,但是不可以进行乘除,以及对于寄存器是不能进行算术操作的
逻辑和移位操作符
AND、OR、XOR、NOT、SHL、SHR
只有在这里罗列的操作符才能在表达式中使用
所有的表达式都只能是常量值

在表达式中左移右移后面的CONT可以超过2
最后两条指令会将PORT_VAL放到端口
关系操作符
EQ(相等)、NE(不等)、LT(小于)、LE(小于等于)、GT(大于)、GE(大于等于)
他们得到的值只有1/0(真:0FFFFH;假:0000H)

数值回送操作符
OFFSET、SEG、TYPE、LENGTH、SIZE
OFFSET/SEG 变量/标号
功能:回送变量或标号的偏移地址/段地址
TYPE 变量/标号/常数
功能:回送数据类型长度-DB(1) DW(2) DD(4) DF(6) DQ(8) DT(10) NEAR(-1) FAR(-2) 常数(0)
LENGTH 变量
功能:回送有DUP定义的变量的单元数,其他情况回送1
SIZE 变量
功能:LENGTH*TYPE

ARRAY DW 5,100 DUP(?)
LENGTH ARRAY;1,因为LENGTH只能去用DUP定义的,如果要去取别的,就用LENGTHOF
ARRAY DW 100 DUP(?),5
LENGTH ARRAY;101因为一开始读到的是100DUP因此是成立的
属性操作符
PTR、段操作符、SHORT、THIS、HIGH、LOW、HIGHWORD、LOWWORD
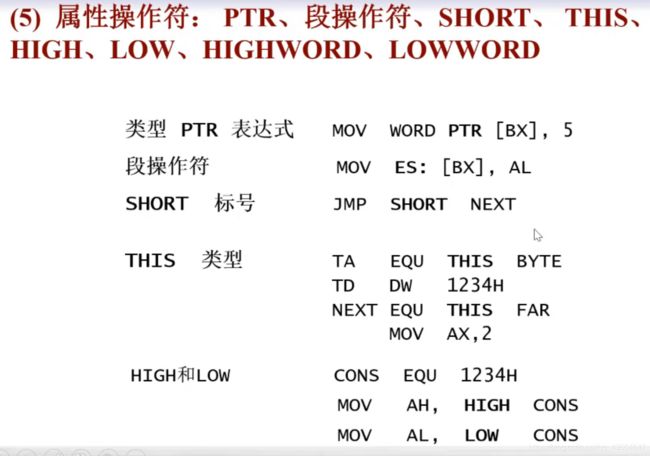
第一段:[BX]需要使用WORD PTR才行,不然会出错
第二段:使用段操作符可以实现段跨越(不会受段的限制)
第三段:强制转换符号标号的长度
第四段:将TA设置为当前的首地址,用BYTE类型
第五段:取符号地址的高/低8位
循环


输入的mov ah,1是用来输入
输出的mov ah,2是用来输出(单字符输出),输出的内容是放在dl中,要转换成ASCII码值

上图中应该是and al,0fh
下面是简便的代码:
str db '0123456789abcdef'
mov bx,offset str;也可以使用lea bx,str
mov al,35h;将5的ASCII码值给al
push ax;保存ax值不变
and al,ofh;萃取al的后四位
xlat;换码指令,将al+bx,即获取到bx中对应的al位数字
mov dl,al
pop ax
add al,08h
mov dh,al
完整代码:
.model samll
.stack 200h
.data
msg1 BYTE '0123456789abcdef'
td WORD 1234h,0abcdh
.CODE
START:
mov ax,@data
mov ds,ax;这两句数初始化寄存器参数
mov dx,td;将td的内容赋值给dx,避免bx被破坏
mov ch,4;设置外循环次数
r1:;标号,表示循环
mov cl,4;设置左移次数
rol dx,cl;实现左移
mov ax,dx;将dx赋给ax
push dx
and al,0fh;取出序号
mov bx,offset msg1;将msg1的偏移地址赋值给bx,方便换码
xlat;换码
mov dl,al;输出三连
mov ah,2
int 21h
dec ch;相当于循环中的i--
jnz r1;跳转回r1循环
pop dx
mov ah,1;默认四连
int 21h
mov ah,4ch
int 21h
END START
例2:

可以使用或操作代替add bx,ax




分支


现在的计算机高度依赖通道技术和中断技术
通道:针对外设进行控制的设备
中断:通道与CPU之间进行协同和交互的技术
子程序
过程定义伪操作

示例如下(定义+调用):

子程序的调用与返回

保存返回地址的方式:将IP压入堆栈(当是段间调用时压入CS和IP)
当前IP为0102时,调用的指令位置为00FF,但是压入的IP为0102
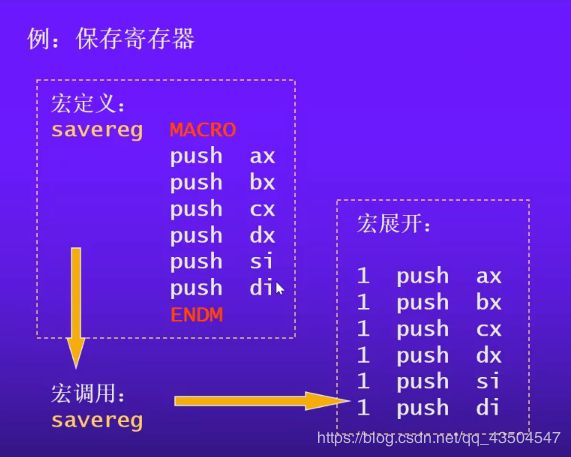
保存与恢复寄存器

子程序的参数传送

- 通过寄存器传送参数:即在调用子程序之前将参数传入寄存器


并且每一个子程序都必须有一个ret来返回 - 通过存储器传送参数:即在调用子程序之前将参数传入存储器

可以用add si,type(ary) 来代替add si,2 - 通过地址表传送参数

- 通过堆栈传送参数地址



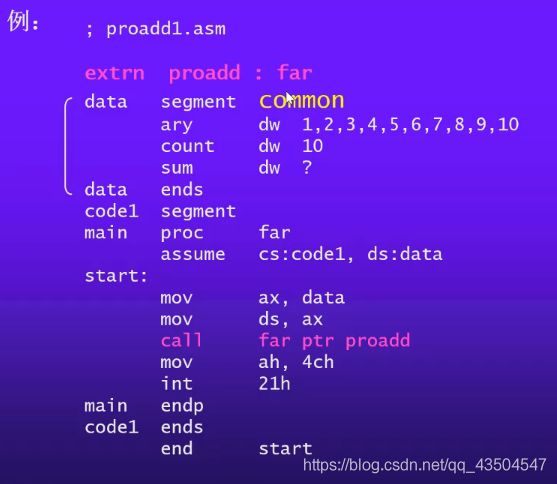
- 多模块之间的参数传送

代码中extrn proadd:far是必不可少的(类似于C++中的文件引用)较少用到这个方式

子程序的嵌套与递归

例题如下:



I/O端口
DOS调用:键盘输入,显示输出
mov AH,01;DOS功能号:键盘输入
INT 21H;DOS调用
MOV CHAR,AL;返回参数:(AL)
mov DL,'A';调用参数:输出字符
mov AH,02;DOS功能号:显示输出
INT 21H
DOS键盘中断(int 21H)

最常使用的是1号中断
9号中断是用来输出的
lea dx,szMsg
mov ah,9
int 21h
以上是输出szMsg中的内容
高级语言和汇编语言
宏汇编

宏汇编就类似于我们C++中的函数
宏的执行速度和效率是高于过程的,因为他是原本就开了空间
子程序与宏定义的对比

宏定义的格式

哑元对应的就是形参
实元对应的就是实参
宏定义调用的方法

宏定义的展开
宏定义在编译后会展开,将参数地址全部替换

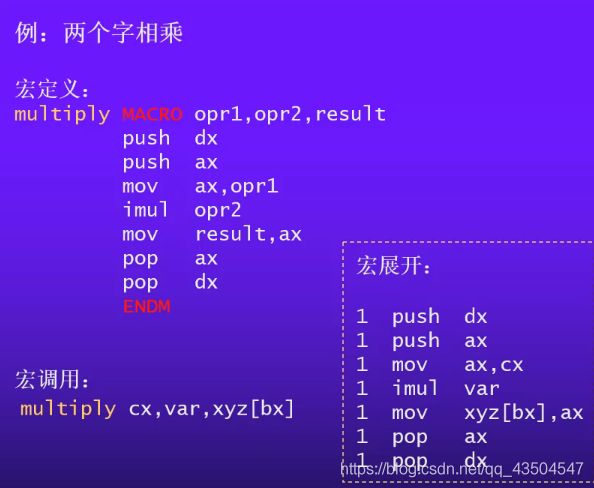
以上例题中可以看出opr1和opr2只能是8位的操作数,因为对于16位的计算时pop dx会将dx内的内容销毁,导致计算出错
宏汇编操作符

&符号的使用示例:


%符号的使用示例:

综合示例:

重复汇编
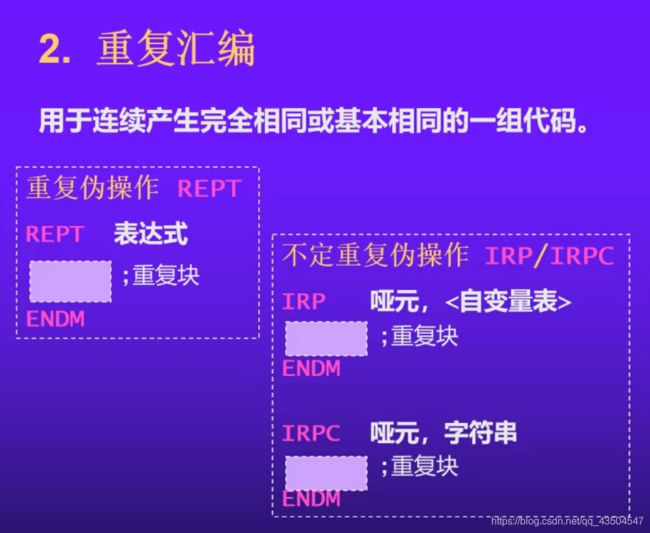
下面是对重复汇编中REPT进行示例:

下面是重复汇编中IRP/IRPC进行示例:


注:主要的应用场景就是对数据段的重复定义
条件汇编

下面是判断语句:

使用示例:
