python进阶学习笔记-数组array用法
数组
如果我们需要一个只包含数字的列表,那么 array.array 比 list 更高效。数组支持所有跟可变序列有关的操作,包括 .pop、.insert 和 .extend。另外,数组还提供从文件读取和存入文件的更快的方法,如 .frombytes 和 .tofile。
语法:array.array(typecode,[initializer]) (在使用之前需要先import array)
typecode:元素类型代码
initializer:初始化器,就是要在这个地方放一个包含数值的数组,若创建一个空的数组,则省略初始化器
创建数组需要一个类型码,这个类型码用来表示在底层的 C 语言应该存放怎样的数据类型。array内的数组成员必须是同一种类型。
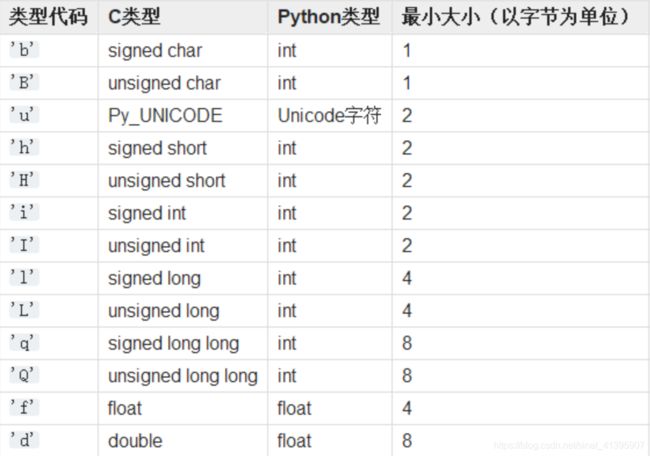
元素类型代码:
eg:
>>> from array import array
>>> from random import random
>>> floats = array('d', (random() for i in range(10**7))) #利用一个可迭代对象来建立一个双精度浮点数组(类型码是 'd'),这里我们用的可迭代对象是一个生成器表达式;random() 方法返回随机生成的一个实数,它在[0,1)范围内。
>>> floats[-1] #查看数组的最后一个元素
0.07802343889111107
>>> fp = open('floats.bin', 'wb')
>>> floats.tofile(fp) #把数组floats存入一个二进制文件fp里,这就是array。tofile的用法
>>> fp.close()
>>> floats2 = array('d') #新建一个双精度浮点空数组
>>> fp = open('floats.bin', 'rb')
>>> floats2.fromfile(fp, 10**7) #从文件fp中把 1000 万个浮点数从二进制文件里读取出来;在array.fromfile()中,第一个参数是文件名,第二个参数是指读取多少个数值出来
>>> fp.close()
>>> floats2[-1] #查看新数组的最后一个元素
0.07802343889111107
>>> floats2 == floats #检查两个数组的内容是不是完全一样
True
array.tofile 和 array.fromfile 用起来很简单,速度也很快。用 array.fromfile从一个二进制文件里读出 1000 万个双精度浮点数只需要 0.1 秒,这比从文本文件里读取的速度要快 60 倍,因为后者会使用内置的 float 方法把每一行文字转换成浮点数。另外,使用 array.tofile 写入到二进制文件,比以每行一个浮点数的方式把所有数字写入到文本文件要快 7 倍。另外,1000 万个这样的数在二进制文件里只占用 80 000 000 个字节(每个浮点数占用 8 个字节,不需要任何额外空间),如果是文本文件的话,我们需要 181 515 739 个字节。
列表和数组的属性和方法
s.iadd(s2) :s += s2,就地拼接
s.append(e) :在尾部添加一个元素
s.byteswap :翻转数组内每个元素的字节序列,转换字节序
s.clear() :删除所有元素
s.contains(e) :s 是否含有 e
s.copy() :对列表浅复制
s.copy() :对 copy.copy 的支持
s.count(e) :s 中 e 出现的次数
s.deepcopy() :对 copy.deepcopy 的支持
s.delitem§ :删除位置 p 的元素
s.extend(it) :将可迭代对象 it 里的元素添加到尾部
s.frombytes(b) :将压缩成机器值的字节序列读出来添加到尾部
s.fromfile(f, n) • 将二进制文件 f 内含有机器值读出来添加到尾部,最多添加 n 项
s.fromlist(l) :将列表里的元素添加到尾部,如果其中任何一个元素导致了 TypeError 异常,那么所有的添加都会取消
s.getitem§ :s[p],读取位置 p 的元素
s.index(e) :找到 e 在序列中第一次出现的位置
s.insert(p, e) :在位于 p 的元素之前插入元素 e
s.itemsize :数组中每个元素的长度是几个字节
s.iter() :返回迭代器
s.len() :len(s),序列的长度
s.mul(n) :s * n,重复拼接
s.imul(n) :s *= n,就地重复拼接
s.rmul(n) :n * s,反向重复拼接*
s.pop([p]) :删除位于 p 的值并返回这个值,p 的默认值是最后一个元素的位置
s.remove(e) :删除序列里第一次出现的 e 元素
s.reverse() :就地调转序列中元素的位置
s.reversed() :返回一个从尾部开始扫描元素的迭代器
s.setitem(p,e) :s[p] = e,把位于 p 位置的元素替换成 e
s.sort([key],[revers]) :就地排序序列,可选参数有 key 和 reverse
s.tobytes() :把所有元素的机器值用 bytes 对象的形式返回
s.tofile(f) :把所有元素以机器值的形式写入一个文件
s.tolist() :把数组转换成列表,列表里的元素类型是数字对象
s.typecode :返回只有一个字符的字符串,代表数组元素在 C 语言中的类型
array的其它用法
array只是指代数组名称,放在具体情境中使用时,将array换成你的程序中具体的数组名称就可以啦~
array.typecodes:查看所有可用类型代码
array.typecode:查看用于创建数组的类型代码字符
array.itemsize:查看数组元素个数
array.append(x):将一个新值x附加到数组的末尾
array.buffer_info():获取数组在存储器中的地址、元素的个数,返回一个元组:(地址、长度)
array.count(x):获取元素x在数组中出现的次数
array.extend(iterable):将可迭代对象的序列iterable(总搞英文参数,看的人一头雾水,其实这个参数就是另一个数组的名称)附加到数组的末尾,将两个序列合并,附加元素数值类型必须与调用对象的元素的数值类型一致
array.fromlist(list):将列表list中的元素追加到数组后面,相当于for x in list:a.append(x)
array.index(x):返回数组中数值x的最小下标
array.insert(i,x):在下表i(负值表示倒数)之前插入值x
array.pop(i):删除索引为i的项,并返回它(pop也叫弹出)
array.remove(x):删除元素x,但是如果在数组中,元素x多次出现,只会删除第一个出现的元素x
array.reverse():反转数组中的元素值的排列顺序
array.tolist():将数组转换为列表