中英文分词后进行词频统计(包含词云制作)
文章目录
- 1、英文词频统计和词云制作
- 2、中文词频统计和词云制作
- 2.1 错误发现
- 2.2 错误改正
在之前的分词学习后,开始处理提取的词语进行词频统计,因为依据词频是进行关键词提取的最简单方法:
1、英文词频统计和词云制作
词云,又称文字云、标签云,是对文本数据中出现频率较高的“关键词”在视觉上的突出呈现,形成关键词的渲染形成类似云一样的彩色图片,从而一眼就可以领略文本数据的主要表达意思。
from nltk import word_tokenize #分词处理
from nltk.corpus import stopwords #停用词
from nltk import FreqDist #统计词频
from wordcloud import WordCloud #词云
from imageio import imread #导入图片进行处理
import matplotlib.pyplot as plt # 利用Python的Matplotlib包进行绘图
paragraph = 'Water has the property of dissolving sugar and sugar has the property being dissolved by water.'.lower()
cutwords1 = word_tokenize(paragraph)
print('【原句子为:】'+ '\n'+ paragraph)
print('\n【NLTK分词结果:】')
print(cutwords1)
interpunctuations = [',', '.', ':', ';', '?', '(', ')', '[', ']', '&', '!', '*', '@', '#', '$', '%'] #定义符号列表
cutwords2 = [word for word in cutwords1 if word not in interpunctuations] #去除标点符号
print('\n【NLTK分词后去除符号结果:】')
print(cutwords2)
stops = set(stopwords.words("english"))
words_lists = [word for word in cutwords2 if word not in stops] #判断分词在不在停用词列表内
print('\n【NLTK分词后去除停用词结果:】')
print(words_lists)
freq = FreqDist(words_lists)
print('\n【统计词频结果:】')
for key,val in freq.items():
print (str(key) + ':' + str(val))
print('\n【基于词频绘制折线图结果:】')
freq.plot(20,cumulative=False) #绘制折线图
words = ' '.join(words_lists) #绘制词云需要将单词列表转换为字符串
words
print('\n【基于词频绘制词云结果:】')
pic = imread('C:/Users/lenovo/Pictures/Saved Pictures/jiege.jpg')
wc = WordCloud(mask = pic,background_color = 'white',width=800, height=600)
wwc = wc.generate(words)
plt.figure(figsize=(10,10))
plt.imshow(wwc)
plt.axis("off")
plt.show()
运行结果:
【原句子为:】
water has the property of dissolving sugar and sugar has the property being dissolved by water.
【NLTK分词结果:】
[‘water’, ‘has’, ‘the’, ‘property’, ‘of’, ‘dissolving’, ‘sugar’, ‘and’, ‘sugar’, ‘has’, ‘the’, ‘property’, ‘being’, ‘dissolved’, ‘by’, ‘water’, ‘.’]
【NLTK分词后去除符号结果:】
[‘water’, ‘has’, ‘the’, ‘property’, ‘of’, ‘dissolving’, ‘sugar’, ‘and’, ‘sugar’, ‘has’, ‘the’, ‘property’, ‘being’, ‘dissolved’, ‘by’, ‘water’]
【NLTK分词后去除停用词结果:】
[‘water’, ‘property’, ‘dissolving’, ‘sugar’, ‘sugar’, ‘property’, ‘dissolved’, ‘water’]
【统计词频结果:】
water:2
property:2
dissolving:1
sugar:2
dissolved:1
【基于词频绘制折线图结果:】
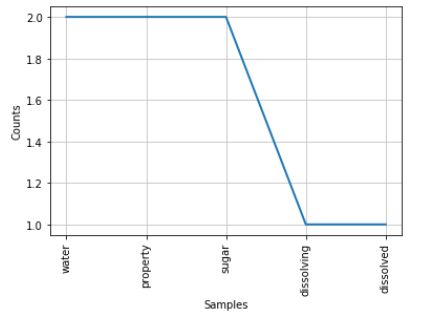
【基于词频绘制词云结果:】

总的来说,wordcloud做的是三件事:
- (1) 文本预处理
- (2) 词频统计
- (3) 将高频词以图片形式进行彩色渲染
从上面的代码可以看到,用 wordcloud.generate(text) 就完成了这三项工作。
2、中文词频统计和词云制作
2.1 错误发现
当我们用英文词频统计的方法去解决中文时,发现中文部分全部都显示的为框框,和自己预期的效果差距很大:

通过上图我们发现,采用matplotlib作图时默认设置下和词云制作是无法显示中文的,凡是汉字都会显示成小方块。那是因为:Matplotlib是一个很好的作图软件,但是python下默认不支持中文。实际上,matplotlib是支持unicode编码的,不能正常显示汉字主要是没有找到合适的中文字体,所以我们稍加修改即可:
- 中文的处理时,需要再导入模块:
import jieba
- matplotlib的中文问题,关键在Wordcloud中加入:
#解决matplotlib绘图中文显示问题
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
- 词云的中文问题,关键在Wordcloud中加入:
font_path='./fonts/simhei.ttf'
2.2 错误改正
from nltk import FreqDist
from wordcloud import WordCloud
from imageio import imread
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
import jieba
import re
#解决matplotlib绘图中文显示问题
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
filename = '白雪公主片段'
filepath1 = 'D:/大学工作所做文档/学习资料/毕业设计学习准备/编程学习/白雪公主片段.txt'
filepath2 = 'D:/大学工作所做文档/学习资料/毕业设计学习准备/编程学习/stop_words.txt'
def stopwordslist(filepath2): # 定义函数创建停用词列表
stopword = [line.strip() for line in open(filepath2, 'r').readlines()] #以行的形式读取停用词表,同时转换为列表
return stopword
def pretext(filename,filepath1): #定义函数
try:
with open(filepath1,encoding='UTF-8') as file:
contents = file.read() #读取文本文件
print('【读取的文本为:】'+'\n'+contents)
content1 = contents.replace(' ','') # 去掉文本中的空格
print('\n【去除空格后的文本:】'+'\n'+content1)
pattern = re.compile("[^\u4e00-\u9fa5^a-z^A-Z^0-9]") #只保留中英文、数字,去掉符号
content2= re.sub(pattern,'',content1) #把文本中匹配到的字符替换成空字符
print('\n【去除符号后的文本:】'+'\n'+ content2)
except FileNotFoundError:
message = "Sorry, the file " + filename + " does not exist."
print(message)
else:
cutwords = jieba.lcut(content2,cut_all=False) #精确模式分词
print ('\n【精确模式分词后:】'+ '\n'+"/".join(cutwords))
stopwords = stopwordslist(filepath2) # 这里加载停用词的路径
words = ''
for word in cutwords: #for循环遍历分词后的每个词语
if word not in stopwords: #判断分词后的词语是否在停用词表内
if word != '\t':
words += word
words += " "
print('\n【去除停用词后的分词:】'+ '\n'+ words )
words_lists = [word for word in words.split()]
freq = FreqDist(words_lists)
print('\n【统计词频结果:】')
for key,val in freq.items():
print (str(key) + ':' + str(val))
print('\n【基于词频绘制折线图结果:】')
freq.plot(20,cumulative=False) #绘制折线图
print('\n【基于词频绘制词云结果:】')
pic = imread('C:/Users/lenovo/Pictures/Camera Roll/sk.jpg')
wc = WordCloud(
mask = pic,
#解决m词云制作中文显示问题
font_path='./fonts/simhei.ttf', #使用字体
background_color = 'white', #背景颜色
#max_words=200, #显示最大词数
#min_font_size=15,
#max_font_size=50,
width=600, #图幅宽度
height=600) #图幅高度
wwc = wc.generate(words)
plt.figure(figsize=(10,10))
plt.imshow(wwc)
plt.axis("off")
plt.show()
stopwordslist(filepath2) #调用函数
pretext(filename,filepath1) #调用函数
运行结果:
【读取的文本为:】
镜中的她有着棕黄色的头发, 直挺的鼻梁,以及如同大理石般的白色肌肤……。皇后非常重视肌肤的保养,不惜重金从先进的法国买来护肤的配方,并使用各种草药制成油膏,每天早上都给肌肤做最好的按摩。 然而岁月不饶人,皇后的美貌、是有衰退的一天。 不知从何时开始,皇后的肌肤已逐渐松弛, 眼角出现了细纹,而国王也似乎不再那么的享受鱼水之欢了;看来,国王已经对皇后不再感兴趣。
皇后当然也听说过国王想在 贵族千金 中寻找宠妃的传闻,因为在不打仗的时候,即使留在城内,国王也把大部分时间都花在探访皇亲国威上。
【去除空格后的文本:】
镜中的她有着棕黄色的头发,直挺的鼻梁,以及如同大理石般的白色肌肤……。皇后非常重视肌肤的保养,不惜重金从先进的法国买来护肤的配方,并使用各种草药制成油膏,每天早上都给肌肤做最好的按摩。然而岁月不饶人,皇后的美貌、是有衰退的一天。不知从何时开始,皇后的肌肤已逐渐松弛,眼角出现了细纹,而国王也似乎不再那么的享受鱼水之欢了;看来,国王已经对皇后不再感兴趣。
皇后当然也听说过国王想在贵族千金中寻找宠妃的传闻,因为在不打仗的时候,即使留在城内,国王也把大部分时间都花在探访皇亲国威上。
【去除符号后的文本:】
镜中的她有着棕黄色的头发直挺的鼻梁以及如同大理石般的白色肌肤皇后非常重视肌肤的保养不惜重金从先进的法国买来护肤的配方并使用各种草药制成油膏每天早上都给肌肤做最好的按摩然而岁月不饶人皇后的美貌是有衰退的一天不知从何时开始皇后的肌肤已逐渐松弛眼角出现了细纹而国王也似乎不再那么的享受鱼水之欢了看来国王已经对皇后不再感兴趣皇后当然也听说过国王想在贵族千金中寻找宠妃的传闻因为在不打仗的时候即使留在城内国王也把大部分时间都花在探访皇亲国威上
【精确模式分词后:】
镜中/的/她/有着/棕黄色/的/头发/直挺/的/鼻梁/以及/如同/大理石/般的/白色/肌肤/皇后/非常重视/肌肤/的/保养/不惜重金/从/先进/的/法国/买来/护肤/的/配方/并/使用/各种/草药/制成/油膏/每天/早上/都/给/肌肤/做/最好/的/按摩/然而/岁月不饶人/皇后/的/美貌/是/有/衰退/的/一天/不知/从/何时/开始/皇后/的/肌肤/已/逐渐/松弛/眼角/出现/了/细纹/而/国王/也/似乎/不再/那么/的/享受/鱼水之欢/了/看来/国王/已经/对/皇后/不再/感兴趣/皇后/当然/也/听说/过/国王/想/在/贵族/千金/中/寻找/宠妃/的/传闻/因为/在/不/打仗/的/时候/即使/留在/城内/国王/也/把/大部分/时间/都/花/在/探访/皇亲/国威/上
【去除停用词后的分词:】
镜中 有着 棕黄色 头发 直挺 鼻梁 如同 大理石 般的 白色 肌肤 皇后 非常重视 肌肤 保养 不惜重金 先进 法国 买来 护肤 配方 使用 草药 制成 油膏 每天 早上 肌肤 最好 按摩 岁月不饶人 皇后 美貌 衰退 一天 不知 皇后 肌肤 逐渐 松弛 眼角 出现 细纹 国王 似乎 享受 鱼水之欢 国王 皇后 感兴趣 皇后 听说 国王 贵族 千金 寻找 宠妃 打仗 留在 城内 国王 大部分 时间 探访 皇亲 国威
【统计词频结果:】
镜中:1
有着:1
棕黄色:1
头发:1
直挺:1
鼻梁:1
如同:1
大理石:1
般的:1
白色:1
肌肤:4
皇后:5
非常重视:1
保养:1
不惜重金:1
先进:1
法国:1
买来:1
护肤:1
配方:1
使用:1
草药:1
制成:1
油膏:1
每天:1
早上:1
最好:1
按摩:1
岁月不饶人:1
美貌:1
衰退:1
一天:1
不知:1
逐渐:1
松弛:1
眼角:1
出现:1
细纹:1
国王:4
似乎:1
享受:1
鱼水之欢:1
感兴趣:1
听说:1
贵族:1
千金:1
寻找:1
宠妃:1
打仗:1
留在:1
城内:1
大部分:1
时间:1
探访:1
皇亲:1
国威:1
【基于词频绘制折线图结果:】

【基于词频绘制词云结果:】
