java面试——2021校招提前批字节飞书后端面试问题集合
介绍一下微服务秒杀项目
redis成为热点怎么办?
利用的redis的(主从、哨兵、集群)做压力的均分
集群怎么解决
nginx负载均衡、配置、权重算法实现
令牌桶、漏桶区别,使用场景
jwt结构、为什么用jwt
JWT 的原理是,服务器认证以后,生成一个 JSON 对象,发回给用户,就像下面这样。
{
"姓名": "张三",
"角色": "管理员",
"到期时间": "2018年7月1日0点0分"
}
以后,用户与服务端通信的时候,都要发回这个 JSON 对象。服务器完全只靠这个对象认定用户身份。为了防止用户篡改数据,服务器在生成这个对象的时候,会加上签名(详见后文)。服务器就不保存任何 session 数据了,也就是说,服务器变成无状态了,从而比较容易实现扩展。
使用JWT的原因
鉴权逻辑无需访问数据库,任何情况下都不会击穿缓存打到数据库影响业务;
与数据库解耦,横向扩容性佳,Token发放、验证都可以脱离数据库
同样是提供Token,但JWT中可附带允许的权限/操作,业务无需实现复杂的权限控制逻辑,只需要判断Token中是否有对应权限即可;
数据平台主要的功能就是提供数据访问接口与数据上传接口,没有传统Web应用的那种上下文关系。过重的鉴权逻辑不太符合当前业务特点;
使用多版本私钥,通过更改固定版本签名所用的私钥可以批量废除发出的Token;使用Redis等缓存后亦可实现对单一Token的回收
业务只有上传/拉取这两个操作,只需要区分当前用户是谁即可
oauth2流程、有安全风险吗、state参数了解吗
新浪微博作为服务提供商,拥有用户的头像、昵称、邮箱、好友以及所有的微博内容,简书希望获取用户存储在微博的头像和昵称,假设它们是三个人:
- 简书问新浪微博:我想要获取用户 A 的头像和昵称,请你提供
- 微博说:我需要经过用户A 本人的许可,然后去问用户 A 是否要授权简书访问自己的头像和昵称
- 用户 A 对微博说:我给简书一个临时的钥匙,如果他给你出示了这把钥匙,你就把我的资料给他
- 简书使用户给它的钥匙获取用户头像和昵称信息。
以上是 OAuth 认证的大概流程。在使用微博授权之前,简书需要先在微博开放平台上注册应用,填写自己的名称、logo、用途等信息,微博开放平台颁发给简书一个应用 ID 和叫 APP Secret 的密钥,在实际对接中,会使用到这两个参数。
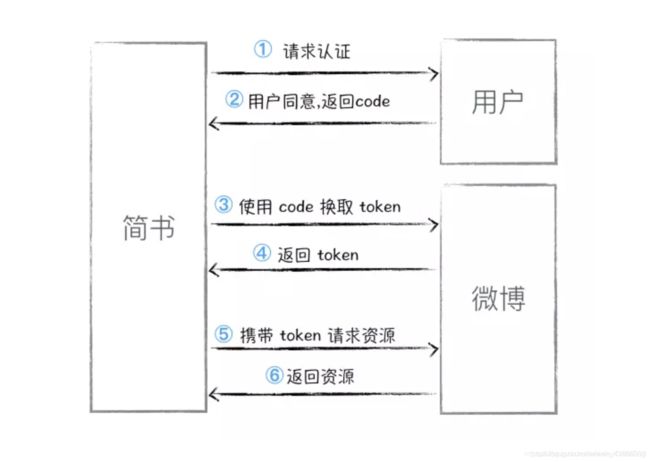
state 参数是为了保证申请 code 的设备和使用 code 的设备的一致而存在的。
对于开发者而言,要修复这个漏洞,就是必须加入state参数,这个参数既不可预测,又必须可以充分证明client和当前第三方网站的登录认证状态存在关联(如果存在过期时间更好)。其实,随机算一个字符串,然后保存在session,回调时检查state参数和session里面的值,就满足要求了。state生成随机算一个字符串,然后保存在当前用户的session,回调时检查state参数和当前用户session里面的值是否一致.攻击者无法猜对方的state值是多少. 就无法拼出用于攻击的url.。
csrf攻击是什么?怎么防范
一般来说,攻击者通过伪造用户的浏览器的请求,向访问一个用户自己曾经认证访问过的网站发送出去,使目标网站接收并误以为是用户的真实操作而去执行命令。常用于盗取账号、转账、发送虚假消息等。攻击者利用网站对请求的验证漏洞而实现这样的攻击行为,网站能够确认请求来源于用户的浏览器,却不能验证请求是否源于用户的真实意愿下的操作行为。
防范手段:
1 验证 HTTP Referer 字段:HTTP头中的Referer字段记录了该 HTTP 请求的来源地址。在通常情况下,访问一个安全受限页面的请求来自于同一个网站,而如果黑客要对其实施 CSRF攻击,他一般只能在他自己的网站构造请求。因此,可以通过验证Referer值来防御CSRF 攻击。
2 关键操作页面加上验证码,后台收到请求后通过判断验证码可以防御CSRF。但这种方法对用户不太友好。
3 在请求地址中添加token并验证:CSRF 攻击之所以能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于cookie中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的cookie 来通过安全验证。要抵御 CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有token或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。这种方法要比检查 Referer 要安全一些,token 可以在用户登陆后产生并放于session之中,然后在每次请求时把token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。对于 GET 请求,token 将附在请求地址之后,这样 URL 就变成 http://url?csrftoken=tokenvalue。而对于 POST 请求来说,要在 form 的最后加上 ,这样就把token以参数的形式加入请求了。
4 在HTTP 头中自定义属性并验证:这种方法也是使用 token 并进行验证,和上一种方法不同的是,这里并不是把 token 以参数的形式置于 HTTP 请求之中,而是把它放到 HTTP 头中自定义的属性里。通过 XMLHttpRequest 这个类,可以一次性给所有该类请求加上 csrftoken 这个 HTTP 头属性,并把 token 值放入其中。这样解决了上种方法在请求中加入 token 的不便,同时,通过 XMLHttpRequest 请求的地址不会被记录到浏览器的地址栏,也不用担心 token 会透过 Referer 泄露到其他网站中去。
rabbitmq协议、如何保证消息被投递(看到过但是没了解)
1.通过AMOP提供的事务机制:
2消息的确认机制 从confirm机制 在发送完消息后可以通过WaitForConfirm等待消息的投递结果,这里有个可选参数,就是阻塞等待的时间,如果返回结果为false则表示消息投递失败,则发送端这时候也就可以采取重试之类的策略了。一种同步的,一种异步通知的:异步回调的方式也就是通道订阅RabbitMQ的发送完毕确认事件,消息投递成功会回调这个方法给发送方,回调的参数包含当前消息在该通道中发送的编号DeliveryTag(批量提交的时候可以根据这个编号对应提交集合的索引,保证对应集合索引上的消息可靠投递)
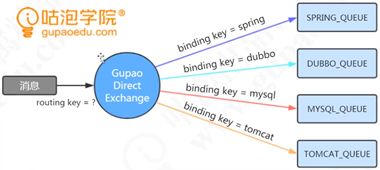
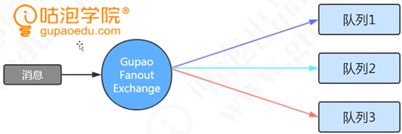
Exchange类型
三种类型:Direct exchange Topic exchange(可以使用通配符) Fanout exchange

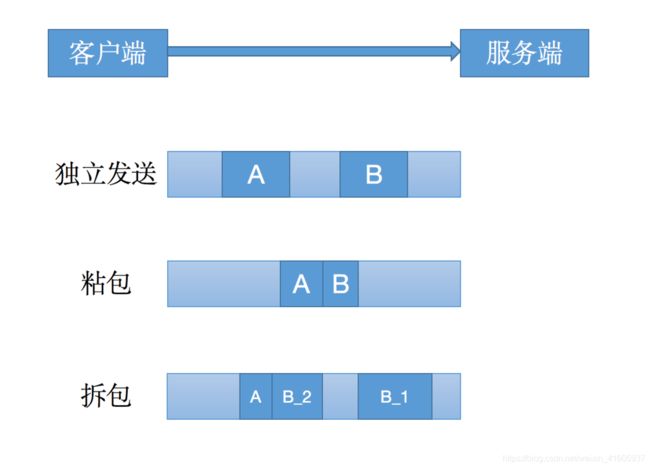
netty拆包 解决粘包和拆包的四种解决方案
在RPC框架中,粘包和拆包问题是必须解决一个问题,因为RPC框架中,各个微服务相互之间都是维系了一个TCP长连接,比如dubbo就是一个全双工的长连接。由于微服务往对方发送信息的时候,所有的请求都是使用的同一个连接,这样就会产生粘包和拆包的问题
粘包和拆包
产生粘包和拆包问题的主要原因是,操作系统在发送TCP数据的时候,底层会有一个缓冲区,例如1024个字节大小,如果一次请求发送的数据量比较小,没达到缓冲区大小,TCP则会将多个请求合并为同一个请求进行发送,这就形成了粘包问题;如果一次请求发送的数据量比较大,超过了缓冲区大小,TCP就会将其拆分为多次发送,这就是拆包,也就是将一个大的包拆分为多个小包进行发送。如下图展示了粘包和拆包的一个示意图:
对于粘包和拆包问题,常见的解决方案有四种:
- 客户端在发送数据包的时候,每个包都固定长度,比如1024个字节大小,如果客户端发送的数据长度不足1024个字节,则通过补充空格的方式补全到指定长度;
- 客户端在每个包的末尾使用固定的分隔符,例如\r\n,如果一个包被拆分了,则等待下一个包发送过来之后找到其中的\r\n,然后对其拆分后的头部部分与前一个包的剩余部分进行合并,这样就得到了一个完整的包;
- 将消息分为头部和消息体,在头部中保存有当前整个消息的长度,只有在读取到足够长度的消息之后才算是读到了一个完整的消息;
- 通过自定义协议进行粘包和拆包的处理。
Netty提供的粘包拆包解决方案
3.1 FixedLengthFrameDecoder
对于使用固定长度的粘包和拆包场景,可以使用FixedLengthFrameDecoder,该解码一器会每次读取固定长度的消息,如果当前读取到的消息不足指定长度,那么就会等待下一个消息到达后进行补足。其使用也比较简单,只需要在构造函数中指定每个消息的长度即可。这里需要注意的是,FixedLengthFrameDecoder只是一个解码一器,Netty也只提供了一个解码一器,这是因为对于解码是需要等待下一个包的进行补全的,代码相对复杂,而对于编码器,用户可以自行编写,因为编码时只需要将不足指定长度的部分进行补全即可。
3.2 LineBasedFrameDecoder与DelimiterBasedFrameDecoder
对于通过分隔符进行粘包和拆包问题的处理,Netty提供了两个编解码的类,LineBasedFrameDecoder和DelimiterBasedFrameDecoder。这里LineBasedFrameDecoder的作用主要是通过换行符,即\n或者\r\n对数据进行处理;而DelimiterBasedFrameDecoder的作用则是通过用户指定的分隔符对数据进行粘包和拆包处理。同样的,这两个类都是解码一器类,而对于数据的编码,也即在每个数据包最后添加换行符或者指定分割符的部分需要用户自行进行处理。
3.3 LengthFieldBasedFrameDecoder与LengthFieldPrepender
这里LengthFieldBasedFrameDecoder与LengthFieldPrepender需要配合起来使用,其实本质上来讲,这两者一个是解码,一个是编码的关系。它们处理粘拆包的主要思想是在生成的数据包中添加一个长度字段,用于记录当前数据包的长度。LengthFieldBasedFrameDecoder会按照参数指定的包长度偏移量数据对接收到的数据进行解码,从而得到目标消息体数据;而LengthFieldPrepender则会在响应的数据前面添加指定的字节数据,这个字节数据中保存了当前消息体的整体字节数据长度。LengthFieldBasedFrameDecoder的解码过程如下图所示:

3.4 自定义粘包与拆包器
对于粘包与拆包问题,其实前面三种基本上已经能够满足大多数情形了,但是对于一些更加复杂的协议,可能有一些定制化的需求。对于这些场景,其实本质上,我们也不需要手动从头开始写一份粘包与拆包处理器,而是通过继承LengthFieldBasedFrameDecoder和LengthFieldPrepender来实现粘包和拆包的处理。
如果用户确实需要不通过继承的方式实现自己的粘包和拆包处理器,这里可以通过实现MessageToByteEncoder和ByteToMessageDecoder来实现。这里MessageToByteEncoder的作用是将响应数据编码为一个ByteBuf对象,而ByteToMessageDecoder则是将接收到的ByteBuf数据转换为某个对象数据。通过实现这两个抽象类,用户就可以达到实现自定义粘包和拆包处理的目的。如下是这两个类及其抽象方法的声明:
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter {
protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List128. 最长连续序列
class Solution {
public int longestConsecutive(int[] nums) {
Set num_set = new HashSet();
for (int num : nums) {
num_set.add(num);
}
int longestStreak = 0;
for (int num : num_set) {
if (!num_set.contains(num - 1)) {
int currentNum = num;
int currentStreak = 1;
while (num_set.contains(currentNum + 1)) {
currentNum += 1;
currentStreak += 1;
}
longestStreak = Math.max(longestStreak, currentStreak);
}
}
return longestStreak;
}
}
Spring为什么是final
MVCC
多版本并发控制,他无非就是乐观锁的一种实现方式。在Java编程中,如果把乐观锁看成一个接口,MVCC便是这个接口的一个实现类而已。
基本原理
MVCC的实现,通过保存数据在某个时间点的快照来实现的。这意味着一个事务无论运行多长时间,在同一个事务里能够看到数据一致的视图。根据事务开始的时间不同,同时也意味着在同一个时刻不同事务看到的相同表里的数据可能是不同的。
基本特征
- 每行数据都存在一个版本,每次数据更新时都更新该版本。
- 修改时Copy出当前版本随意修改,各个事务之间无干扰。
- 保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
有没有大表优化经历(没有,但是了解一些)
数据中的大表的查询优化操作
1优化shema、sql语句+索引;
2第二加缓存,memcached, redis;
3主从复制,读写分离;
4垂直拆分,根据你模块的耦合度,将一个大的系统分为多个小的系统,也就是分布式系统;
5水平切分,针对数据量大的表,这一步最麻烦,最能考验技术水平,要选择一个合理的sharding key, 为了有好的查询效率,表结构也要改动,做一定的冗余,应用也要改,sql中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表;
输入url发生的事情:就从计算机网络几个层讲了一下
1. 浏览器首先判断使用的是什么协议(ftp/http),然后对URL进行安全检查。最后浏览器查看缓存,如果请求的对象在缓存中并且是比较新的。那么直接跳到步骤9
2. 浏览器请求OS返回服务器的IP地址
3. 操作系统启动DNS查询并向浏览器返回服务器的IP地址
4. 浏览器使用TCP协议建立与服务器的连接
5. 浏览器通过TCP连接发出HTTP请求
6. 浏览器收到HTTP响应。这时候浏览器可能关闭TCP连接,或者继续使用它来请求其他数据。
7. 浏览器检查响应报文的状态码。并根据不同的状态码做不同的处理。
8. 如果响应是可缓存的,那么就存储在缓存区。
9. 浏览器解码响应报文(比如文件是压缩的就需要解压缩)
10. 浏览器渲染响应的数据。
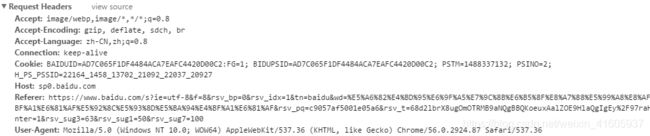
http有哪些header
每个HTTP请求和响应都会带有相应的头部信息。默认情况下,在发送XHR请求的同时,还会发送下列头部信息:
- Accept:浏览器能够处理的内容类型
- Accept-Charset:浏览器能够显示的字符集
- Accept-Encoding:浏览器能够处理的压缩编码
- Accept-Language:浏览器当前设置的语言
- Connection:浏览器与服务器之间连接的类型
- Cookie:当前页面设置的任何Cookie
- Host:发出请求的页面所在的域
- Referer:发出请求的页面的URL
- User-Agent:浏览器的用户代理字符串
HTTP响应头部信息:
- Date:表示消息发送的时间,时间的描述格式由rfc822定义
- server:服务器名字。
- Connection:浏览器与服务器之间连接的类型
- content-type:表示后面的文档属于什么MIME类型
- Cache-Control:控制HTTP缓存
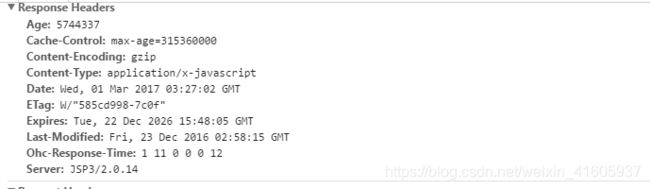
http状态码

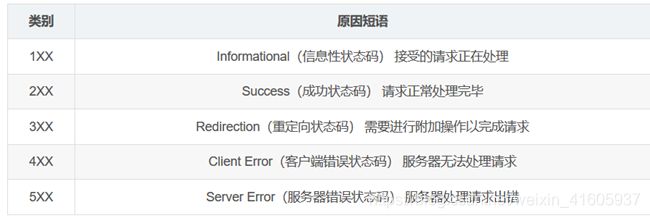


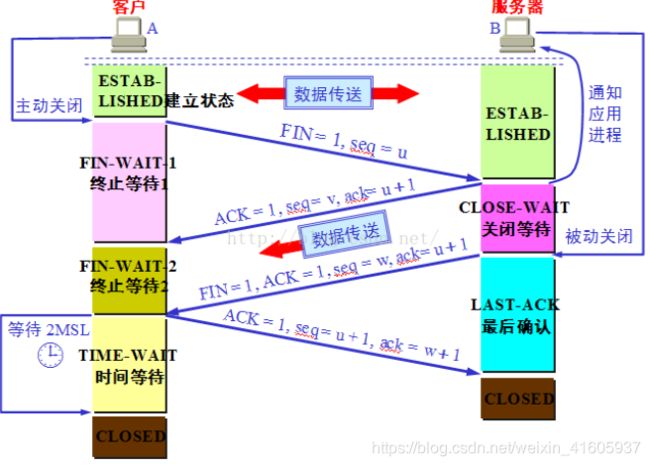
TCP三次握手,四次挥手
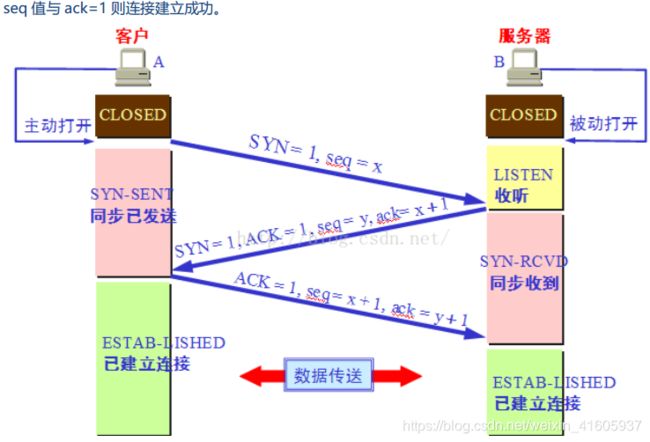
TCP建立连接时socket相关函数:
socket的基本操作:
(1)socket()函数:
(2)bind()函数:
(3)listen(),connect()函数;
(4)accept()函数;
(5)socket中的发送与接收函数:
(6)close()函数:
(7)服务器上调用socket函数:
(8)客户端调用socket函数:
(9)IP地址转换函数:inet_pton, inet_ntop, inet_addr:
TCP拥塞控制,流量控制:慢开始等
滑动窗口
UDP如何实现可靠连接:我就说在报文数据段自己定义一下相关字段,在应用层实现可靠的操作
GET、POST

进程和线程区别
进程是资源分配的最小的单位,线程是执行的最小的单位,。
进程是资源分配的最小单位,线程是程序执行的最小单位。进程是系统中正在运行的一个程序,程序一旦运行就是进程。一个进程可以拥有多个线程,每个线程使用其所属进程的栈空间。线程与进程的一个主要区别是,同一进程内的一个主要区别是,同一进程内的多个线程会共享部分状态,多个线程可以读写同一块内存(一个进程无法直接访问另一进程的内存)。同时,每个线程还拥有自己的寄存器和栈,其他线程可以读写这些栈内存。
进程控制块PCB
进程间如何通讯方法:
信号量 内存共享 socket 管道通信 消息队列
线程间如何通讯:
使用volatile关键字
使用Object类的wait() 和 notify() 方法、
使用JUC工具类 CountDownLatch、基本LockSupport实现线程间的阻塞和唤醒。
进程有哪些状态,状态切换

堆、栈:我从JVM角度答的
Mysql事务怎么声明
Mysql索引结构
索引类型:这个当时没反应过来是什么
引擎Mysam和Innodb区别
B+树
Mysql几种隔离级别,读已提交,可重复读
网站如何防止重复提交
redis几种数据类型
redis String类型自增的命令:inc
linux父子进程,fork(),如何判断哪个是父哪个是子进程
一个二维数组循环的时候是按行读还是按列读快,我从缓存角度答了一下按行读快。
easy算法题:
单例模式
大数相加
redis为什么快
redis有没有并发问题
redis的数据结构
sorted set的使用场景和底层实现,复杂度
mybatis的缓存
spring boot和spring的优劣势
mysql的索引
给定一个表,获取所有课程得分均大于80分的学生的平均得分
有一个 1GB 大小的文件,文件里每一行是一个词,每个词的大小不超过 16B,内存大小限制是 1MB,要求返回频数最高的 100 个词
二叉树的对称性判断,判断一颗二叉树是否对称
网络
1.http和https区别
2.说一下加密算法(说的比较详细,面试官让简单点说)
多线程
1.synchronized和lock区别
2.说一下各自原理
3.乐观锁悲观锁说一下
4.syn和lock是乐观还是悲观
5.乐观锁有啥?原理和ABA问题
6.重入锁说一下
OS
1.页面置换算法
2.LRU缓存,让我设计LRU思路,这个还得好好看啊,说的稀里糊涂的,还好没让手撕(有点凉)
JVM
1.说一下垃圾回收这块,知道的都说出来吧
2.新生代和老年代都用什么算法?
3.双亲委派说一下
4.类加载过程
数据库
1.索引作用?
2.索引的数据结构
3.聚簇索引是什么?
4.innodb是什么索引?
5.查字典是什么索引?
代码
1.单例模式(写的双重检验)
追问syn和volatile作用
2.Z字型遍历二叉树
2.编程,leetcode03
网络
3.http和https的区别
4.https建立连接的过程
5.https抓包工具是如何实现的
语言
6.java的equals()和==的区别
7.java常用的容器有哪些
8.java的多态和继承是如何实现的
9.java的内存管理机制
10.java多线程中的锁你用过哪些
操作系统
11.进程间通信哪几种方式
12.线程间通信有哪几种方式
13.虚拟内存,共享内存和常驻内存的区别
14.虚拟地址,逻辑地址和物理地址的区别
15.逻辑地址如何转成物理地址
16.死锁发生的条件
一面:
1. 从浏览器敲入baidu.com到回车的过程中发生了什么
2. client 如何通过ip地址找到目标机器(路由转发)
3. 了解arp吗
4. http和https的区别
5. redis有哪些数据结构? 如何用这些数据结构实现一个发布订阅的功能?
6. kafka为什么快?好处在哪?(主要是实习中用到了kafka)
7. 字符串压缩算法了解过吗?
8. threadlocal知道吗,如果让你实现一个类似的功能你如何实现?(当时不记得threadlocal了,然后面试官给了我个场景,让我实现以下。。我说用map然后key是thread的地址,value是存储变量)
9. 100w个数据求出前100大的数据
10. 手撕单例模式,双重判断
11. 单例模式为啥要用volatile,volatile的原理
12. jvm的数据结构?堆的结构?minor gc的算法?年轻代gc后没死的对象放哪?如何才能进入老年代,没进入老年代的从from to区间中的存放过程是怎样的(复制算法)?
13. 12m的对象放入年轻代10m的堆中会发生什么?(主要看老年代是否够大)
14. OOM后如何定位问题在哪?
二面:
主要是问项目
1. redis的缓存穿透问题如何解决?
2. 在实习时数据库性能优化你做了什么工作?
3. 了解grpc吗?
4. 你是如何测试dubbo dfs thrift三种rpc性能的,简单说说。(还和我讨论了下不同序列化方式对性能影响)
5. 你是如何解决你实习过程中full gc问题的
6. 从浏览器敲入baidu.com到回车的过程中发生了什么
7. left join 和 inner join的区别
算法题:
1. leetcode 二叉树右视图(我用bfs写的,其实也可以用dfs;我说我做过,然后面试官说那就快点写完进入下一题吧)
2. o表示住户,x表示快递柜地点。输出每个用户到快递柜的最近距离
输入:
o o o
o x o
o x o
输出
2 1 2
1 0 1
1 0 1
1、项目
2、进程和线程的区别
3、进程之间的通信
4、线程之间的同步
5、Java里面的锁,优先队列
6、TCP如何做到可靠性、TCP为什么四次分手
7、数据库底层结构、B和B+树的区别,数据库如何建索引,最左匹配是什么
8、hashmap讲一下
算法题:
1. 实现一个内存操作安全的memcpy函数,函数原型如下(看我用Java就不做了):void *memcpy(void *dst, void * src, size_t size);
2. 给定一个二叉查找树和一个数字N,请找出二叉查找树中大于等于N的最小节点。
3. 求一个数组的大于K且与K差距最小的子集,比如[65,30,52,17,98,20]这样一个数组,
求它的一个和大于等于100,且与100差值最小的那个子集,这个例子的最终输出回事[30,52,20].因为这个子集和为102,是原数组所有和大于等于100中的子集里与100差值最小的那个。
4. 两个线程交替打印,线程1先开始打印数字1,线程2接着打印字母a,接着线程1打印数字2,线程2打印字母b,依次类推,每个线程各打印5次。
算法:链表奇数位升序、偶数位降序->得到一个最终升序
基础:
TCP-三次握手/四次握手的必必要性
go相关go协程为什么轻量?
其他的忘了,反正很基础
算法:链表k个一旋转
项目&实习情况
redis的zset
如果让你实现kafka(自己说项目中用到过、自己给自己挖坑)如何实现?
如果你实现的kafka按照时间来查找并消费你怎么做?
分布式锁你怎么实现?
TCP-三次握手/四次握手的必必要性
操作系统的内存管理-->段页式->逻辑地址到物理地址的映射->TLB
mysql的引擎
mysql的索引
b树 b+树区别、各自优缺点
问背景、家庭情况
项目&实习情况
如何建立索引
mysql索引的建立什么情况下那些列会生效之类的
es的底层原理(???)
算法:一个循环数组(是循环的吗?我那时候有点眼花记不清了),相邻的不可同时拿,问怎么拿值最大时间O(n) 空间O(1)?、LFU 时间O(1)、我特么看了LRU的O(1)咋就没看LFU的O(1)
结果式俩算法题一紧张都没做来 哭
第一个算法:如果不是循环的跳梯子dp,循环的话那我zhen'bu'h
第二个算法:一个map (频率->频率下的map(key->节点)) ,节点{key,freq}
说一下TCP和UDP协议的头部数据
HTTP2.0有哪些改动。
keep-alive是1.0还是1.1加进去的
http默认端口号是什么
说一下https,为什么安全,具体说一下https建立连接的流程
redis用过吗
说一下redis五种数据类型,置换算法说一下(FIFO,LRU,LFU)
用redis五种数据类型,手撕一个LRU算法(说了思路,不会。当时说的是用hash做储存,list实现一个双向链表维护)
redis的hashmap和java的hashmap有何异同
数据库学过吗?
说一下建索引用索引的条件,索引的弊端
有没有遇到过建了索引但是没走索引这种情况
给一个Linux 命令说明这命令干什么的 drwxr-xr-x 7 chris staff 224B Mar 4 11:20 go(太菜,不记得了,曾经似乎看到过)
给一个学生表,一个成绩表,查询性别是女的学生的成绩和姓名,按降序排列
说一下左连接和内连接的区别
然后一个动态规划题,给你一个日志文件,上面有每个用户登录登出时刻,求每一时刻同时在线的人数
logs[] = [[1,0,1],[2,2,3],[3,0,5]]
日志格式 是 uid,login_time,logout_time ,要求算法时间复杂度为O(n),只写出O(n^2)