(SPP-net)Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition论文阅读笔记
文章目录
- (SPPNet)Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition论文阅读笔记2014
- Abstract
- 1. Introduction
- 2.Deep Networks With Spatial Pyramid Pooling
- 2.1 Convolutional Layers and Feature Maps
- 2.2 The Spatial Pyramid Pooling Layer
- 2.3 Training the Network
- 3.SPP-net For Image Classification
- 3.1 Experiments on ImageNet 2012 Classification
- 3.1.1 Baseline Network Architectures
- 3.1.2 Multi-level Pooling Improves Accuracy
- 3.1.3 Multi-size Training Improves Accuracy
- 3.1.4 Full-image Representations Improve Accuracy
- 3.1.5 Multi-view Testing on Feature Maps
- 3.1.6 Summary and Results for ILSVRC 2014
- 3.2 Experiments on VOC 2007 Classification
- 3.3 Experiments on Caltech101
- 4. SPP-net For Object Detection
- 4.1 Detection Algorithm
- 4.2 Detection Results
- 4.3 Complexity and Running Time
- 4.4 Model Combination for Detection
- 4.5 ILSVRC 2014 Detection
- 5. Conclusion
- APPENDIX A
(SPPNet)Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition论文阅读笔记2014
Abstract
目前的深层CNN都需要固定尺寸的输入图像。这种需要是“人工的”,可能会对任意尺度的图像识别的准确率有所降低。本文中,我们提出了一种新的网络,使用了另一种池化策略,“空间金字塔池化”,来消除上面的这种固定尺寸要求。**我们的新网络,SPP-net,无论输入图像的尺寸,都生成一个固定维度的表示representation。**金字塔池化同样对目标变形是鲁棒的,有着这些优点,SPP-net应该可以整体上提升所有基于CNN的图像分类方法的表现。在ImageNet2012数据集上,我们实验得出SPP-net可以提升了多种不同结构的CNN的表现效果。在PASCAL VOC2007以及Caltech101数据集上,SPP-net使用了单个整张图像表示,没经过微调,达到了目前最好的分类表现。
SPP-net的表现在目标检测领域也很重要。**使用SPP-net,我们只对整张图片计算一次,得到特征图,然后在任意区域(sub-images)进行池化,得到固定长度的representation,用来训练检测器。**这种方法避免了重复计算卷积特征。在处理测试图像时,我们的方法比R-CNN快24-102倍,而在PASCAL VOC2007上取得了和它相当的准确率。
在ILSVRC2014上,我们的方法在目标检测排名第二,在图像分类上排名第三。文章中同样介绍了针对比赛对网络进行的修改。
1. Introduction
我们见证着一个视觉领域高速发展、变革的时代,主要是由CNN以及大尺度训练数据的出现带来的。基于深度网络的方法目前极大地提升了在图像分类、目标检测以及其他识别和非识别任务的表现能力。
然而,在CNN的训练和测试中有一个技术问题:目前流行的CNN,需要的输入是固定尺寸的(比如224 * 224),这就限制了输入图像的长宽比和尺度。当应用到任意尺寸的图像上时,目前的方法大部分是将通过裁剪,或者变形输入图像转换为固定尺寸,如图1(top)所示。但是,**裁剪的区域可能不包含整个目标,而变形的区域可能会导致不需要的几何变形。**因为这种loss或变形会导致识别准确率下降,除此之外,提前确定好的尺度在目标尺度变化时,可能不适用了。
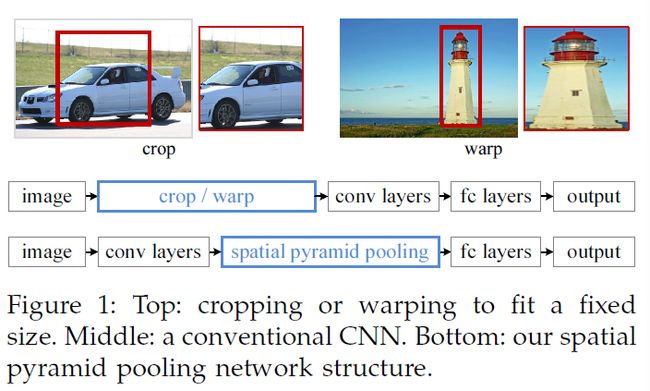
那么,CNN为什么需要固定尺寸的输入呢?CNN主要由两部分组成,卷积层和之后的FC层。卷积层使用滑窗的方式进行计算,输出特征图(代表激活值的空间分布)。实际上,卷积层不需要固定的输入尺寸,可以对任意尺寸的图像生成特征图。FC层需要固定的输入尺寸,因此,固定尺寸这个要求主要来自于FC层,FC层一般存在于网络的深层。
本文中,我们介绍一种空间金字塔池化(SPP)层,来移除固定尺寸的限制。==我们在最后一层卷积层后加入SPP层,SPP层对特征图进行池化,然后生成固定长度输出,再送入到FC层(或其他分类器)。==也就是说,我们在卷积层和FC层之间进行某种信息聚合,来取消一开始的裁剪或者变形操作。图1(bottom)展示出加入SPP层之后的网络结构变化,我们将这个新网络叫做SPP-net。
空间金字塔池化(更多叫做空间金字塔匹配SPM),作为词袋模型的一种扩展,是计算机视觉中最成功的方法之一。**它将图片分区成不同等级,从细致到粗糙,然后在每个等级中聚合本地特征。**在CNN流行之前,SPP一直都是分类和检测的优秀模型的关键成分之一。不过,SPP一直没有被考虑应用到CNN中。我们注意到SPP对CNN有几个显著的特点:
- SPP可以生成固定长度的输出,无论输入尺寸是多大,然而通常CNN使用的滑窗的池化层不可以。
- SPP使用了多尺度的空间bins,然而滑窗的池化只是用了单个尺度。多等级的池化对目标变形具有更好的鲁棒性。
- 由于输入尺度的灵活性,SPP可以对在多种尺度生成的特征进行池化。
通过实验证明,上面几种特点都提升了深度网络的准确性。
SPP-net不仅可以在测试时对任意尺寸图像或窗口生成表示,而且可以让我们在训练时使用多种尺寸尺度的图像来进行训练。**使用多种尺寸图像训练可以提升尺度不变性,减少过拟合。**我们采取一个简单的多尺寸训练方法。**为了使单个网络接受可变的输入大小,我们可以通过共享所有参数的多个网络对它进行近似,而每个网络都使用固定的输入大小进行训练。**在每个epoch,我们使用一个固定尺寸训练网络,然后在下一个epoch使用另一个尺寸进行训练。实验证明这种训练方式收敛地跟单尺寸训练一样快,还有着更好的测试准确率。
SPP的优点与特定的CNN设计正交。在一系列的在ImageNet2012数据集上的控制实验中,我们发现SPP提升了四种不同的CNN结构的表现,相对于没有SPP的对应模型。这些结构有着不同的卷积核数量、尺寸、步长、深度以及其他参数。**因此我们可以认为SPP对更复杂的CNN结构同样有所提升。**SPP在Caltech101以及PASCAL VOC2007数据集上,在使用单一整张图像表示以及没有微调的情况下,取得了当今领先的分类表现。
SPP-net在目标检测上同样展现出强劲实力。目前领先的R-CNN方法中,候选区域的特征是通过深度卷积网络来提取到的。这种方法在VOC和ImageNet上都取得了好的结果。**但是R-CNN中的特征计算十分耗时,因为它重复将CNN应用在每张图的上千个raw pixels的变形区域。**本文中,我==们的方法只需要在整张照片上计算卷积一次(无论候选框的个数),然后再特征图上提取特征。==这种方法使得比R-CNN提升了近百倍速度。注意到在特征图上进行训练或测试(而不是在原始图像区域)是更流行的方法。SPP-net不止继承了深层CNN的特征图的能力,而且有着SPP在任意尺寸上的灵活性,这就使得网络取得了杰出的准确率和效率。随着最近的快速proposal方法EdgeBoxes的出现,我们的系统可以在0.5s处理一张图像,这使得我们的方法在真实世界应用成为可能。
2.Deep Networks With Spatial Pyramid Pooling
2.1 Convolutional Layers and Feature Maps
对经典的七层结构,前五层是卷积层,有的后边接了池化,这些池化也应该被当做“卷积的”,因为它们使用滑窗来进行。最后两层是FC层,输出N维的softmax。
上面介绍的深度网络需要固定尺寸的图像。**然而我们发现,这个需求只是由于FC层需要固定尺寸的输入,卷积层可以接受任意尺寸的输入。**卷积层使用滑窗计算,输出的特征图与输入有着同样的长宽比,包含着响应值信息以及空间位置信息。
在图2中,我们可视化一些特征图,他们有conv5的一些卷积核生成,(c)展示出在ImageNet数据集上最强响应的图像,一些filter可以被一些语义成分所激活。比如,第55个filter最易被圆形激活,第66个filter最易被^形激活…输入图像中的这些形状(图2a)在相应的位置激活了特征图。
值得注意的是,我们在没有固定输入尺寸的情况下,生成了图2中的特征图。这些通过深度CNN生成的特征图与传统方法生成的特征图类似。在那些方法中,SIFT或image patches密集提取,然后被编码成向量、稀疏coding或Fisher kernels。这些编码特征组成了特征图然后使用词袋或空间金字塔进行池化。相似地,CNN以相似方法进行池化。
2.2 The Spatial Pyramid Pooling Layer
卷积层接收任意输入尺寸,但是生成的也是不同尺寸的输出。分类器(SVM/softmax)以及FC层需要固定长度的向量。一般可以通过词袋BoW来将特征池化,生成向量。**空间金字塔池化对词袋有所提升,它可以保留空间信息,在局部空间bins进行池化。**这些空间bins的尺寸与图像尺寸成比例,所以无论图像尺寸如何,生成的bins数量是固定的。这与输出尺寸依赖于输入的CNN相反。
**我们使用一个空间金字塔池化层取代了原网络的最后一个池化层,如图3所示。在每个空间bin,我们对每个filter的响应进行最大池化。**最后的输出为kM维度的向量,k为最后一层卷积层的卷积核数,M为bin的数量。最后这个固定维度的向量输入到FC层中。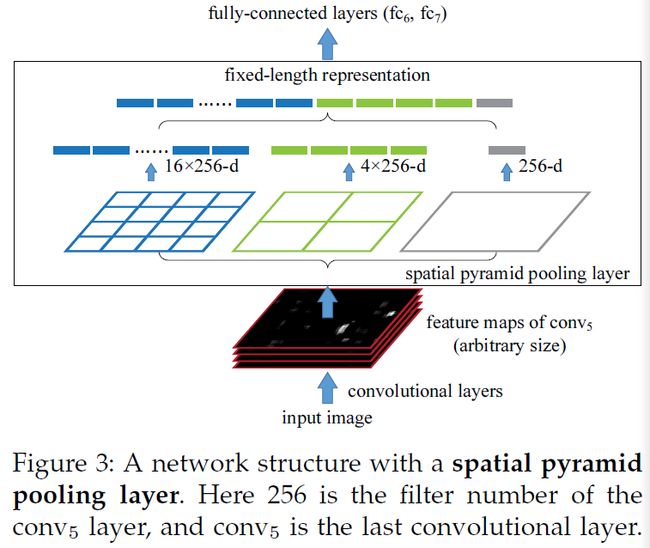
带有空间金字塔池化,输入图像可以是任意尺寸,任意长宽比。尺度在传统方法中扮演很重要的角色,比如SIFT向量通常在多个尺度提取,下面我们展示尺度对深度网络的准确率同样重要。
有趣的是,最粗糙的金字塔层只有一个bin,包含了整张图像,就是全局池化操作,在一些文章中,全局池化被用来降低模型尺寸等…
2.3 Training the Network
理论上,上面的网络可以使用标准的反向传播来训练,尽管输入尺寸不同。但是实际上GPU更适合于应用在固定输入尺寸任务中,下面我们描述我们如何利用GPU训练同时,加入SPP行为。
Single-size training。
在之前工作中,我们首先考虑网络固定输入224 * 224,有图像裁剪而来。裁剪的目的是数据增强。**对于一张给定尺寸的图像,我们可以提前计算出SPP需要的bin尺寸。**比如,**假设conv5的输出特征图尺寸为a * a,假设为13 * 13。对于n等级,使用n * n个bin,我们将池化看作滑窗池化,窗口尺寸和步长分别为a/n向下取整和向上取整。对于l个等级金字塔,我们使用l个这样的层,输出级联送入FC中。**图4展示了一个三层金字塔的例子,池化(3 * 3、2 * 2、1 * 1)。
Multi-size training。
为了考虑到多种尺寸,我们考虑了一系列预设尺寸。我们考虑两种尺寸:180 * 180和224 * 224。相比于裁剪成一个小的180 * 180区域,我们直接将上面的224 * 224 resize成180 * 180。所以两个不同尺度的区域只是尺寸不同,布局以及成分没有不同。对于180 * 180的输入,我们使用与224 * 224相同的操作,金字塔等级等…最后输出的长度是一致的,因此我们使用两个共享参数的SPP-net来处理不同尺寸的输入。
为了减少从一个网络切换到另一个的开销,我们在每个网络上训练一整个epoch,然后在另一个网络上训练下一个epoch(保留所有权值),迭代继续进行。实验中,我们发现这种方法收敛与单尺寸训练一昂快。
我们的多尺寸训练目的是模拟多尺寸输入的情况,同时应用优化好的现存的固定尺寸训练的方法。除了使用上述的两种尺度之外,我们也测试了在每个epoch使用随机的尺寸s * s,s在区间[180,224]随机。
注意,上述的单尺寸和多尺寸只是在训练中,测试阶段我们直接将任意尺寸图像输入到SPP-net中。
3.SPP-net For Image Classification
3.1 Experiments on ImageNet 2012 Classification
我们使用ImageNet2012训练1000类分类网络,图像resize到短边为256,然后从四个角落和中心裁剪共5个224 * 224。使用水平翻转和颜色改变(PCA)进行数据增强,即AlexNet的操作。在前两个FC层使用Dropout,学习率初始为0.01,表现不在提升,学习率除以10.
3.1.1 Baseline Network Architectures
我们调查了四种不同的CNN结构作为对比,我们发现SPP对这四种结构改造之后,都提升了准确率。基础的结构在表1列出,下面简要介绍。
- ZF-5。基于ZF的fast模型,5代表着5层卷积层
- Convnet5。基于AlexNet的修改。我们在conv2和conv3后加入池化层,这样没层之后的特征图尺寸与ZF-5一致。
- Overfeat-5/7。基于Overfeat,做了一些修改。相比于上面两个结构,这种结构的特征图在最后一个池化层之前更大(18 * 18相比于13 * 13),在conv3以及后续卷积层中使用了更多的卷积核(512)。同样使用了一个7层的版本,conv3-conv7有同样的结构。
在基础模型中,最后一层卷积层输生成6 * 6的特征图,之后是两个4096维FC层和最后的1000维输出。我们使用这些基础模型的结果见表2(a),我们对ZF-5训练70个epoches,对其他训练90个epoches。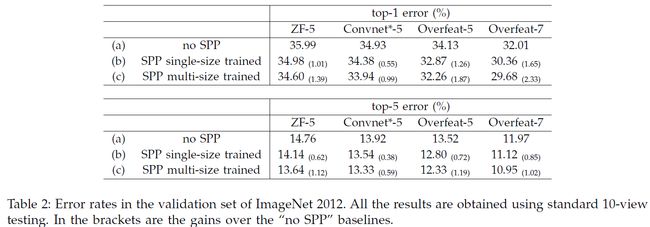
3.1.2 Multi-level Pooling Improves Accuracy
在表2(b)中,我们展示了使用单尺寸训练的结果。训练和测试尺寸均为224 * 224。在这些网络中,卷积层与相关的基础模型有相同的结构,只是最后一层卷积层后的池化替换成了SPP。表2中的结果,我们使用4级金字塔,6 * 6、3 * 3、2 * 2、1 * 1,一共50个bins。为了对比公平,我们对每个224 * 224crop使用标准的10-view prediction。
值得注意的是,多等级(金字塔等级)的池化带来的提升不只是因为更多的参数,而是因为多等级池化对目标变形和空间布局更加鲁棒。为了展示,我们使用另一种4等级的ZF-5网络进行训练,4 * 4、3 * 3、2 * 2、1 *1,总共30bins。这个网络的结果是35.06/14.04,与上面的50bin的网络的结果34.98/14.14相似,但是比不适用SPP的模型好(35.99/14.76)。
3.1.3 Multi-size Training Improves Accuracy
表2(c)中展示了我们使用多尺寸训练的结果。训练的尺寸为224和180,测试尺寸是224.我们同样使用标准10-view预测,所有的模型的错误率都下降了。
除了使用两个固定的尺寸,我们同样使用一个随机尺寸(180-224之间)来进行评估,SPP-net(Overfeat-7)的top-1和top-5错误率分别为30.06%和10.96%。尽管top–1错误率比固定的两种尺寸版本略差,因为用于测试的224尺寸在训练中较少被visit,但是结果仍比单尺寸版本好。
之前有一些CNN处理多尺度,但是它们大部分关注测试阶段。在Overfeat以及Howard的方法中,同一个网络在测试阶段被应用到多个尺度上,然后把分数平均。Howard在低/高分辨率图像区域训练两个不同的网络,然后把分数平均。据我们调查,我们是第一个在训练阶段,使用同一个网络训练多种尺度的输入图像的方法。
3.1.4 Full-image Representations Improve Accuracy
接下来我们以整张图像的视角研究。我们在保持图像长宽比的前提下,resize图像的短边到256。SPP-net直接应用到整张图像上来计算分数。作为对比,我们评估使用单张中心224 * 224的crop的准确率,如表3所示。我们比较ZF-5与Overfeat-7。**top-1错误率都是使用full-image的低,这表现出保留整体成分的重要性。**尽管我们只使用了正方形的图像训练,但是它对其他长宽比的图像的表现也很好。
比较表2和表3,我们发现多个尺寸仍然比单一的整张视角效果好,然而整张图像的representation也很重要。根据经验我们发现,即使组合了dozens of views,额外的两个full-image视角(原图+水平翻转)仍然可以提升准确率0.2%。而且整张图像的视角在方法论上与传统方法一致,比如SIFT就是将整张图像向量连接到一起。在其他应用,比如图像检索中,一个图像representation,而不是分类分数,是相似性排名所必需的。
3.1.5 Multi-view Testing on Feature Maps
受到我们检测算法的启发(下一部分介绍),我们进一步提出一个在特征图上的多视角测试方法。多亏SPP的灵活性,我们可以从任意尺寸的卷积的特征图上提取到windows(views)的特征。
在测试阶段,我们将图像resize到最短边为s,比如256。然后我们对整张图像计算特征图。我们同样对水平翻转图像计算特征图。==对图像中的任意view(window),我们将window映射到特征图,然后使用SPP来对这个window提取出特征,提取到的特征被送到fc层来计算这个window的softmax分数,取平均值作为最后的预测结果。==对于标准的10-view,我们使用s=256,views使用224 * 224,在角落以及中间。实验表明这种10-view预测,在特征图上比在原来的图像上,错误率相近。
我们进一步将这种方法扩展到对多尺度提取多个views。我们将图像resize到六个尺度:224、256、300、360、448、560,然后对每个尺度的整张图像计算特征图。对于每个尺度,使用224 * 224作为view size,所以这些view相对于不同的尺度,有着不同的相对尺寸。**对于每个尺度,使用18个views:一个中间、四个角、四个在每边的中间,以及它们的水平翻转。当s=224时,使用六个view。**组合总共96个views,使得top-5错误率从10.95%降低到9.36%,再组合两个full-image的view,可以继续降低到9.14%。
在Overfeat中,同样是从特征图中提取views,然而他们的view不是任意尺寸的,比我们的效果差。
3.1.6 Summary and Results for ILSVRC 2014
表4中,我们与之前的方法进行对比,我们只考虑单个网络的表现对比。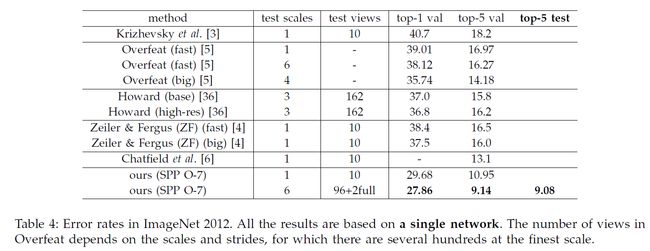
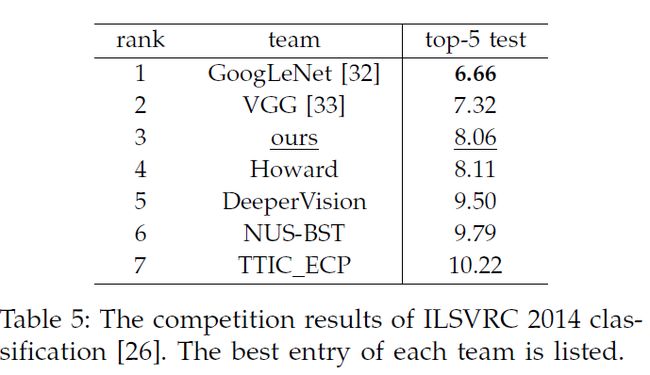
我们最好的单网络在验证集上取得9.14%的top-5错误率,我们将它提交到ILSVRC2014,在测试集上取得9.08%。组合七个模型之后,我们取得了8.06%,排名第三(如表5)。因为SPP的优点与网络的结构无关,我们期待它会提升更深更大的网络结构。
3.2 Experiments on VOC 2007 Classification
我们方法可以生成一个full-view的图像表示,使用上面在ImageNet进行预训练的网络,我们在目标数据集的图像中,提取这些representations,然后再训练SVM分类器。在SVM训练中,我们故意没有使用任何数据增强手段(flip/multi-view)。我们对特征进行L2归一化来进行SVM训练。
PASCAL VOC2007分类任务包括20类,9963张图像。5011张训练集,剩余是测试集。通过mAP来评估网络表现。表6总结了结果。
表中,(a)表示没有使用SPP的baseline,应用这个模型时,我们resize图片到短边为224像素,然后取中心的224 * 224crop。SVM通过一层的特征来进行训练。在这个数据集,网络越深,结果越好。(b)使用了SPP,第一步比较,我们仍然将其应用在224 * 224的crop上。可以看到,FC层的结果相对于提升了,这主要是由于我们SPP的多等级池化。
(c)展示我们在full图像的结果,图像被resize到短边为224,结果相对于(b)有所提升,这是因为full-image representation保持了完整成分内容。
因为我们网络的使用不依赖于尺度,我们resize图像到短边为s,然后使用相同的网络进行训练,我们发现s=392取得了最好的效果(d)。这主要是因为在VOC2007中目标占据区域较小,而在ImageNet上较大,所以这两个数据集的目标尺度相对来说不一样。这证明了尺度在分类任务中很重要,SPP可以部分解决这个尺度匹配的问题。
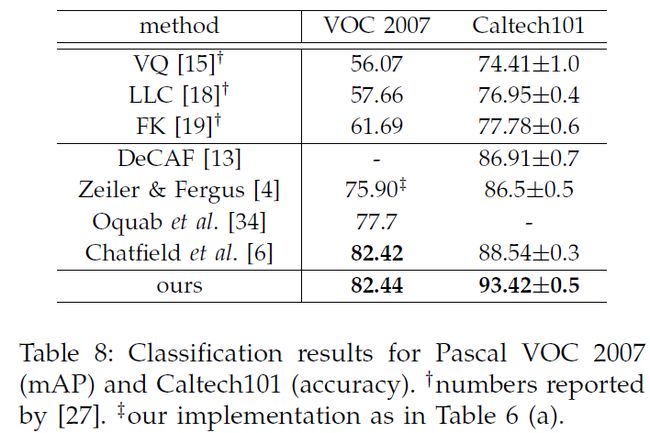
(e)网络使用了我们最好的模型(Overfeat-7,多尺度训练),mAP提升到82.44%。表8总结了我们的结果,并且和其他方法做了对比。这些方法中,VQ、LCC、FK都用了空间金字塔匹配。
3.3 Experiments on Caltech101
Caltech101数据集包含102类(包括一个背景类),9144张图像。我们对每一类随机取样30张进行训练,然后取最多50张每类用作测试。我们重复了十次,平均结果。表7总结了我们的结果。
在Caltech101与PASCAL VOC2007上得到了一些共同结果:SPP-net比no-SPP效果好,full-image representation比crop好。但是结果在Caltech上也有一些不同,FC层不够准确,SPP层更准确,这可能是因为这个数据集的目标类别与ImageNet上不够相关,深层更加category-specialized。此外,我们发现尺度224取得了最好的结果,主要是因为Caltech101与ImageNet一样,目标占据较大区域。
除了裁剪,我们来评估了将图像变形到224 * 224,这种情况保留了完整成分,但是变形了。在SPP(ZF-5)上,准确率是89.91%,比没有变形,使用fullimage的情况差。
4. SPP-net For Object Detection
深度网络最近用于目标检测,最新的就是R-CNN,它的原理略过,参见另一篇笔记。R-CNN主要的时间瓶颈主要就是对2000个proposals进行特征提取的过程。
我们的SPP-net也可以用来目标检测。**我们对整张图提取特征图一次(可能在多个尺度上),然后使用SPP,在特征图上的每个候选窗进行池化来得到固定长度的representation(见图5)。**因为耗时的卷积只用了一次,我们的方法速度非常快。
我们网络对特征图的区域按window提取特征,而R-CNN对图像区域提取特征。在之前的工作中,DPM对HOG特征图中提取窗口的特征,SS方法在编码的SIFT特征图中提取窗口的特征。Overfeat检测方法同样对卷积特征图中提取窗口的特征,但是需要提前确定window size。相反,我们的方法可以在卷积特征图上对任意尺度窗口进行特征提取。
4.1 Detection Algorithm
**我们使用SS算法的快速模式来对每张图像生成大约2000个候选窗口,然后将图像resize到短边为s,对整个图像提取特征图。**我们最开始使用时SPP-net的ZF-5版本(单尺度训练的)。对于每个候选窗口,我们使用4-level 空间金字塔(1 * 1、2 * 2、3 * 3、6 * 6,总共50bins)来生成特征。对于每个窗口,产生了12800维度的特征(256 * 50),这些表示送入FC层。之后我们对每一类训练一个二分线性SVM分类器。
对于SVM的训练,我们使用ground-truth windows生成正样本。负样本是那些与正样本IoU超过0.3的窗口,负样本中,如果互相之间IoU超过70%,那么就移除一个。我们使用标准的hard negative mining来训练SVM,并且该步骤迭代一次。测试阶段,分类器用于对候选框评分,然后我们对评分后的窗口使用非极大值抑制NMS(阈值30%)。
我们方法可以通过多尺度特征提取来提升。我们将resize的短边尺寸s取480、576、688、864、1200,然后对每个尺寸计算conv5的特征图。一个策略是将从这些尺度上提取到的特征组合到一起(在channel维度上)。但是我们根据经验找到了更好的方法。==对于每个候选窗,我们选择一个尺度s(在上面几个中),目的是使得候选窗口的像素数尽可能接近224 * 224,然后我们仅仅使用从这个选到的尺度生成的特征图来计算特征。==如果这个尺度足够dense,而且窗口近似于正方形,那么我们这种方法就近似于将窗口resize到224 * 224,然后进行提取特征。而我们的方法对一个尺度只需要计算一次特征图,而与候选窗数量无关。
我们也对我们的与训练网络进行微调。因为我们对任意尺寸窗口的特征由conv5特诊图池化得到,简单来说,我们只微调FC层。这种情况下,后面接fc6和fc7以及一个新的21-way(一个negative类)的fc8层。fc8层的权重使用高斯分布初始化 σ = 0.01 \sigma = 0.01 σ=0.01。学习率首先固定为1 * e-4,然后对后面三层调整为1 * e-5。微调阶段,正样本是与ground-truth重叠IoU大于等于0.5的窗口,负样本是0.1-0.5的窗口。在每个mini-batch,25%样本是正样本,我们使用1 * e-4学习率训练个250k minibatches,然后50k使用1 * e-5。因为我们只微调FC层,训练很快。同样与R-CNN一样,我们使用bounding box regression来再处理预测窗口。用于回归的特征是从conv5池化得到的,用于回归的窗口是那些与ground-truth重叠至少IoU50%的窗口。
4.2 Detection Results
我们在PASCAL VOC2007数据集的检测任务评估我们的模型,表9展示了我们不同层的结果,我们使用单尺度688或5尺度。R-CNN结果作为对比,它使用了AlexNet作为backbone,在pool5,我们的结果与R-CNN相当,使用没有微调的fc6,我们的结果稍差。主要是因为我们的fc层预训练使用的是image region,而不是特征图。**特征图在windows的边缘附近会有较大的激活值,而图像不会。**通过微调可以解决这个问题。使用了微调之后(ftfc),我们的结果与R-CNN相当或略好于R-CNN,加入bbox回归之后,我们的5尺度结果比R-CNN好0.7%。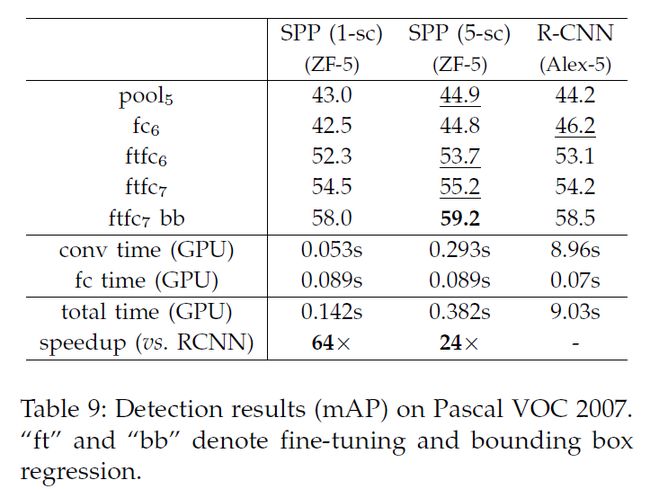
表10中,我们进一步将使用同样预训练模型的SPPnet(ZF-5)与R-CNN进行对比。这次,我们的方法与R-CNN有着相当的平均分数。R-CNN的结果通过预训练模型有所提升。这是因为ZF-5的结构比AlexNet的结构要好。表11展示了对每一类的结果。
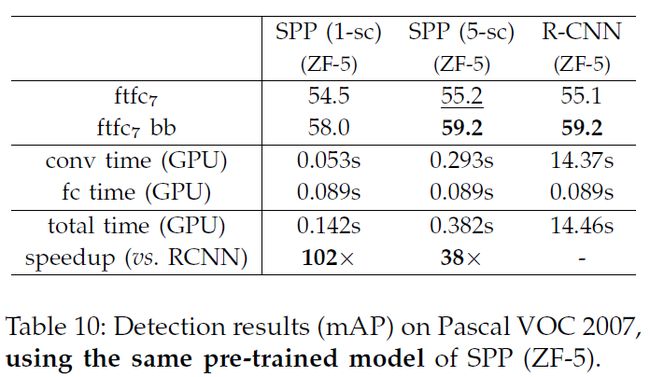
表11也包含其他的方法,SS在SIFT特征图上应用了特征金字塔,DPM和Regionlet依照HOG特征,通过组合不同的特征,Regionlet效果提升到了46.1%。DetectorNet训练了一个输出按像素的目标mask的深层网络。这个方法只需要对整张图像送入深度网络处理一次,这跟我们的方法一样。但是它们的方法mAP较低(30.5%)。
4.3 Complexity and Running Time
尽管有着相当的准确率,我们的方法比R-CNN要快很多。R-CNN中卷积特征计算的复杂度是O(n * 227^2),n为候选窗数量,大约2000。我们的复杂度是O(r * s^2),s为尺度,r为长宽比,单尺度版本s=688时,复杂度为R-CNN的1/160,5尺度版本,复杂度是R-CNN的1/24。
表10中,我们使用同一种ZF-5模型对特征计算的运行时间做了对比。R-CNN对每张图像平均花费14.97s来做卷积运算,而我们的单尺度版本只需要0.053s,我们的5尺度版本需要0.293s,速度都远超R-CNN。我们的卷积速度如此快以至于跟FC层运算时间相当,考虑到卷积和FC运算整体,我们比R-CNN快102倍和38倍(单尺度和5尺度)。
表9中,我们同样与使用AlexNet的R-CNN进行对比,我们方法比它快24-64倍,AlexNet与ZF-5每层卷积层参数一样,它比ZF-5的R-CNN快是因为,它在一些层分散到两个GPU上计算。
在最近的windowproposal方法的帮助下,我们得到了一个高效的整个系统。SS在CPU上每张图像需要1-2秒,而EdgeBoxes只需要0.2s。注意到,在测试阶段,采用快速地proposal方法就足够了。**我们训练采用SS,测试时候采用EdgeBoxes,不带bbox回归情况下的mAP为52.8%。**考虑到训练时没有使用EdgeBoxes,这个结果可以接受。然后我们在训练阶段使用两种方法,然后测试阶段只用EdgeBoxes,得到的没有bbox回归的结果mAP为56.3%。这种情况下,每张图的测试时间0.5s(包括proposal和recognition过程),这使得我们方法可用于现实世界应用。
4.4 Model Combination for Detection
对于提升CNN分类准确率来说,模型组合是很重要的策略,我们为检测提出了一个简单的组合方法。
我们在ImageNet上预训练另一个网络,使用相同的网络结构但是初始化不同。然后重复上面的检测算法,表12(SPP-net(2))展示出这个网络的结果。它的mAP与第一个网络相当,在11个类被超越第一个网络。
对于两个模型,**我们首先使用每个模型来对测试图像的所有候选窗进行评分,然后对两组评分的候选框的并集使用NMS。通过这种方法,一个模型得出的confident window可以抑制那些另一个模型给出的less confident windows。**在组合之后,mAP提升到了60.9%。在20类中,17类中组合模型都比任一个单独模型效果好。这说明这两个模型互补。
我们进一步发现互补主要是因为卷积层,我们曾试过将两个卷积层一致,对后面进行随机初始化微调的模型进行组合,发现没有效果增强。
4.5 ILSVRC 2014 Detection
ILSVRC2014检测任务包含200类,训练集、验证集、测试集分别有450k、20k、40k图像。
检测(DET)训练数据集和分类(CLS)训练数据集主要有三个不同,会影响预训练的质量。首先DET训练数据只有CLS训练数据的1/3,只能使用提供的DET数据,比较有挑战。第二,DET的类别数量只有CLS的1/5,为了克服这个问题,我们利用了提供的子类别来进行预训练,一共有499个不重叠的子类别(类似于树中的叶节点)。所以我们首先在DET训练集上预训练一个499-类的网络。第三,DET和CLS数据集中目标的尺度分布很不同,CLS中的大部分目标尺度为长度的0.8,而DET里大部分为0.5。为了解决尺度差异,我们将训练图像resize到短边400,而不是256,然后随机裁剪224 * 224进行训练。
我们在PASCAL VOC2007上验证了我们的预训练结果。之前采用CLS进行预训练,我们的pool5特征mAP为43.0%,如表9所示。替换成DET的200-类网络预训练后,降到了32.7%,采用499-类,结果是35.9%。有趣的是,即使训练数据量不再增加,训练有着更多类的网络也会提升feature的质量。最后,使用resize到400进一步训练, 提升到37.8%。即便如此,与使用CLS预训练相比还是有着很大的差距,这也显示出深度学习中大数据的重要性。
对于ILSVRC2014,我们训练了一个499-类的Overfeat-7 SPP-net,剩下的操作与VOC2007情况类似。我们使用验证集来生成正负样本,使用SS的fast模式来进行区域建议。我们微调FC层然后使用验证集和训练集的样本来训练SVM,bbox回归在验证集上进行训练。
我们的单模型在ILSVRC2014测试集上取得31.84%的mAP,我们组合了六个模型,得到了35.11%的mAP。
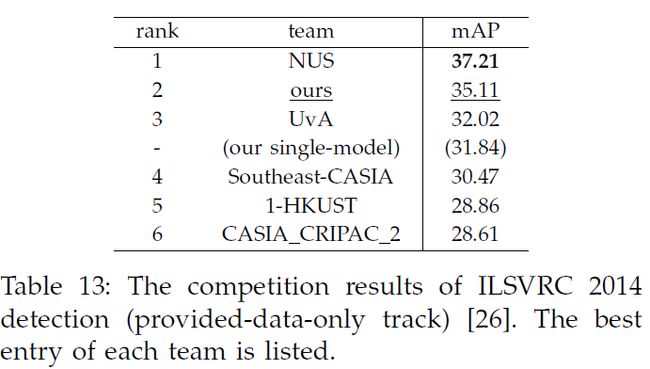
我们的系统仍然表现出速度的优势,对于单个模型,每张测试图像0.6s(5个尺度),使用相同的模型,R-CNN需要每张图像32s。
5. Conclusion
SPP是处理多尺度、尺寸、长宽比的一种灵活的方法。在视觉任务中这些问题很重要,但是在深度网络之中却很少考虑。我们提出一种解决方法来使用SPPlayer训练深层网络,训练出的SPP-net在分类和检测任务中取得了优异的表现。我们的研究同样北站驶出,在计算机视觉领域早就经过验证的技术,在深度网络中仍然可以扮演重要角色。
APPENDIX A
本附录中介绍一些应用细节。
Mean Subtraction。
224 * 224的crop通常经过减去per-pixel mean进行预处理。当输入图像为任意尺寸时,固定尺寸的mean image可能不直接适用。在ImageNet数据集上,我们将224 * 224的mean image变形到想要的尺寸再相减。在PASCAL VOC2007 和Caltech101上,我们使用常数mean(128)。
Implementation of Pooling Bins。
我们使用下面的方法来处理所有的bins。将conv5的宽和高设为w和h,对于有着n * n的金字塔层,第(i,j)个bin在以下范围中: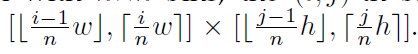
直观上,如果需要四舍五入,我们在左/上边界进行向下取整操作,在右/下边界进行向上取整操作。
Mapping a Window to Feature Maps。
在检测算法中(和在特征图上的多view测试),在image上给出window,需要使用它在特征图上进行裁剪,特征图已经对原来的图进行了几次下采样了,所以我们需要将这个窗口在特征图上对齐。
n * n的金字塔层,第(i,j)个bin在以下范围中:[外链图片转存中…(img-ueJIL0nZ-1590134904812)]
直观上,如果需要四舍五入,我们在左/上边界进行向下取整操作,在右/下边界进行向上取整操作。
Mapping a Window to Feature Maps。
在检测算法中(和在特征图上的多view测试),在image上给出window,需要使用它在特征图上进行裁剪,特征图已经对原来的图进行了几次下采样了,所以我们需要将这个窗口在特征图上对齐。
我们将window的角落点映射到特征图上的像素,使得image上的这个角落点最接近它在特征图上的像素感受野中心。映射过程由于padding和pooling的存在很复杂,为了简化操作,我们对于卷积核尺寸为p的,进行p/2的pad。这样对于一个中心在(x’,y’)的响应,它在图像上的有效感受野中心为(x,y)=(Sx’,Sy’),S为所有之前层的步长。我们模型中,ZF-5在conv5上S=16,对于Overfeat5/7在conv5/7,S =12。
