Tensorflow入门教程-001-基础函数使用
1、constant定义一个张量
a = tf.constant([1, 5], dtype=tf.int64)
print("a:", a)
print("a.dtype:", a.dtype)
print("a.shape:", a.shape)
2、Variable可迭代更新参数定义
import tensorflow as tf
w = tf.Variable(tf.constant(5, dtype=tf.float32))
lr = 0.2
epoch = 40
for epoch in range(epoch): # for epoch 定义顶层循环,表示对数据集循环epoch次,此例数据集数据仅有1个w,初始化时候constant赋值为5,循环100次迭代。
with tf.GradientTape() as tape: # with结构到grads框起了梯度的计算过程。
loss = tf.square(w + 1)
grads = tape.gradient(loss, w) # .gradient函数告知谁对谁求导
w.assign_sub(lr * grads) # .assign_sub 对变量做自减 即:w -= lr*grads 即 w = w - lr*grads
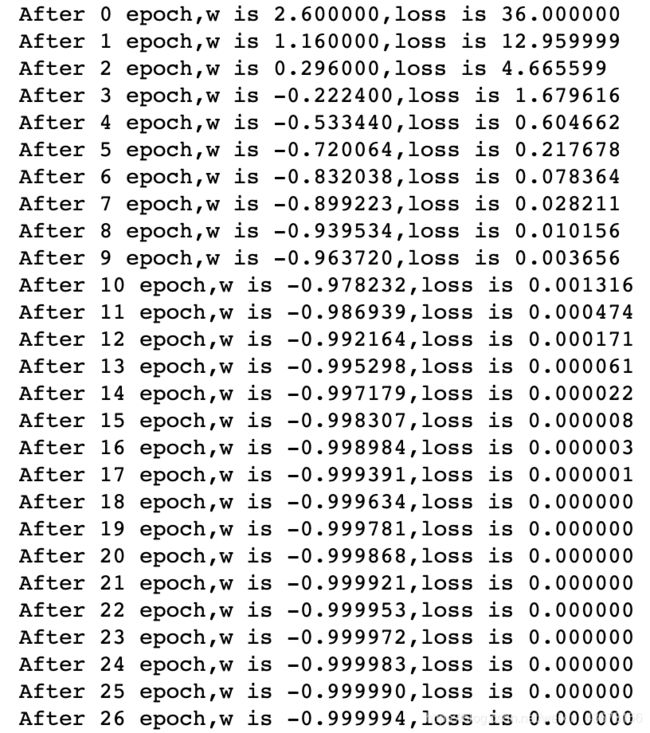
print("After %s epoch,w is %f,loss is %f" % (epoch, w.numpy(), loss))
# lr初始值:0.2 请自改学习率 0.001 0.999 看收敛过程
# 最终目的:找到 loss 最小 即 w = -1 的最优参数w
tf.Variable:定义一个可迭代的数,在参数的训练中更新,过程如下:
3、numpy转tensor
a = np.arange(0, 5)
b = tf.convert_to_tensor(a, dtype=tf.int64)
print("a:", a)
print("b:", b)
4、特征对应标签
features = tf.constant([12, 23, 10, 17])
labels = tf.constant([0, 1, 1, 0])
dataset = tf.data.Dataset.from_tensor_slices((features, labels))
for element in dataset:
print(element)
5、求导运算
with tf.GradientTape() as tape:
x = tf.Variable(tf.constant(3.0))
y = tf.pow(x, 2)
grad = tape.gradient(y, x)
print(grad)
out
tf.Tensor(6.0, shape=(), dtype=float32)
函数y对x求导,这里也用到了Variable。
6、独热编码(one-hot)
classes = 3
labels = tf.constant([1, 0, 2]) # 输入的元素值最小为0,最大为2
output = tf.one_hot(labels, depth=classes)
print("result of labels1:", output)
print("\n")
7、softmax函数
y = tf.constant([1.01, 2.01, -0.66])
y_pro = tf.nn.softmax(y)
print("After softmax, y_pro is:", y_pro) # y_pro 符合概率分布
print("The sum of y_pro:", tf.reduce_sum(y_pro)) # 通过softmax后,所有概率加起来和为1