大数据学习——数据处理工具Pig入门使用
简介
Pig是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转为一系列经过优化处理的MapReduce运算。
特点
- 专注于大量数据集分析
- 运行在集群的计算架构上,Yahoo Pig提供了多层抽象,简化并行计算让普通用户使用,这些抽象完成自动把用户请求queries翻译成有效的并行评估计划,然后在物理集群上执行这些计划;
- 提供类似SQL的操作语法
- 开放源代码
Pig与Hive区别
- Pig是一种编程语言,简化了Hadoop常见的工作任务。Pig可加载数据、表达转换数据以及存储最终结果。Pig内置的操作使得半结构化数据变得有意义(如日志文件)。同时Pig可扩展使用Java中添加的自定义数据类型并支持数据转换。
- Hive在Hadoop中扮演数据仓库的角色。Hive添加数据的结构在HDFS,并允许使用类似于SQL语法进行数据查询。
Pig相比Hive轻量,主要的优势是可大幅消减代码量。
Pig运行模式
- 本地模式,只涉及到一台计算机
- MapReduce模式,需要能访问Hadoop集群,并且装上HDFS
Pig的调用方式
- Grunt shell方式:通过交互的方式,输入命令执行任务
- Pig script方式:通过Script脚本的方式来运行任务
- 嵌入式方式:通过Java调用
安装
实验环境:已安装好Hadoop环境,CentOS7
下载地址:
http://pig.apache.org/
wget http://mirror.bit.edu.cn/apache/pig/pig-0.16.0/pig-0.16.0.tar.gz
tar -zvxf pig-0.16.0.tar.gz
mv pig-0.16.0 pig
修改/etc/profile
export PIG_HOME=/usr/local/pig
export PIG_CLASSPATH=${PIG_HOME}/conf/
export PATH=.:${PIG_HOME}/bin:$PATHsource /etc/profile设置 Pig与Hadoop关联
进入$PIG_HOME/conf,vi pig.properties,添加:
fs.defaultFS=hdfs://hadoop-master:9000
mapreduce.jobtracker.address=hadoop-master:9001使用示例
进入与退出
cd $PIG_HOME/bin
./pig --进入grunt shell
quit; --退出grunt- pig -x local 本地模式
- pig -x mapreduce 集群模式
命令行
ls / --列出目录
cd aa --进入文件夹
cat a.txt --查看文件
Pig latin
Pig Latin是一个相对简单的语言,它可以执行语句。
命令换行时,可用放在行尾 \
- LOAD : 指出载入数据的方法
- FOREACH:逐行扫描进行某种处理
- FILTER:过滤行
- DUMP:把结果显示到屏幕
- STORE:把结果保存到文件
通常书写顺序
Created with Raphaël 2.1.0LOAD 从文件系统读取数据FOREACHSTORE 对数据执行一系列操作
测试
cat /whr/daily/stats/2017/03/21/cmd
a = LOAD '/whr/daily/stats/2017/03/21/cmd' USING PigStorage(',') AS (col1:chararray,col2:chararray,col3:chararray,col4:chararray,col5:int);
describe a;
b = GROUP a BY(col2);
describe b;
c = FOREACH b GENERATE COUNT(a.col2); 计算输入文件记录数
dump c;语法解释 :
- LOAD 加载文件 , 其中PigStorage用来定义列分隔符
- STORE 语句,存储结果集
- explain 解释执行逻辑或物理视图
- describe 显示schema的关系
别名:
- dump \d
- describe \de
- explain \e
- illustrate \i
- 退出 \q
Java嵌入PigLatin(未测试代码)
import java.io.IOException;
import org.apache.pig.PigServer;
public class WordCount {
public static void main(String[] args) {
PigServer pigServer = new PigServer();
try {
pigServer.registerJar("/mylocation/tokenize.jar");
runMyQuery(pigServer, "myinput.txt";
}
catch (IOException e) {
e.printStackTrace();
}
}
public static void runMyQuery(PigServer pigServer, String inputFile) throws IOException {
pigServer.registerQuery("A = load '" + inputFile + "' using TextLoader();");
pigServer.registerQuery("B = foreach A generate flatten(tokenize($0));");
pigServer.registerQuery("C = group B by $1;");
pigServer.registerQuery("D = foreach C generate flatten(group), COUNT(B.$0);");
pigServer.store("D", "myoutput");
}
}shiyanlou 实验
vi /etc/hosts192.168.40.2 f764... hadoopcd /app/hadoop-1.2.2/bin
./start-all.sh
cd /home/shiyanlou/install-pack
tar -xzf pig-0.13.0.tar.gz
mv pig-0.13.0 /app
sudo vi /etc/profile内容
export PIG_HOME=/app/pig-0.13.0
export PIG_CLASSPATH=/app/hadoop-1.1.2/conf
export PATH=$PATH:$PIG_HOME/binsource /etc/profile
echo $PATH
pig
quit进入grunt shell命令行模式。 
运行示例
cd /home/shiyanlou/install-pack/class7
unzip website_log.zip
ll
hadoop fs -mkdir /class7/input
hadoop fs -copyFromLocal website_log.txt /class7/input
hadoop fs -cat /class7/input/website_log.txt | less
pig输入(不要带中文注释)
//加载HDFS中访问日志,使用空格进行分割,只加载ip列
records = LOAD 'hdfs://hadoop:9000/class7/input/website_log.txt' USING PigStorage(' ') AS (ip:chararray);
// 按照ip进行分组,统计每个ip点击数
records_b = GROUP records BY ip;
records_c = FOREACH records_b GENERATE group,COUNT(records) AS click;
// 按照点击数排序,保留点击数前10个的ip数据
records_d = ORDER records_c by click DESC;
top10 = LIMIT records_d 10;
// 把生成的数据保存到HDFS的class7目录中
STORE top10 INTO 'hdfs://hadoop:9000/class7/out';查看结果
quit
hadoop fs -ls /class7/out
hadoop fs -cat /class7/out/part-r-00000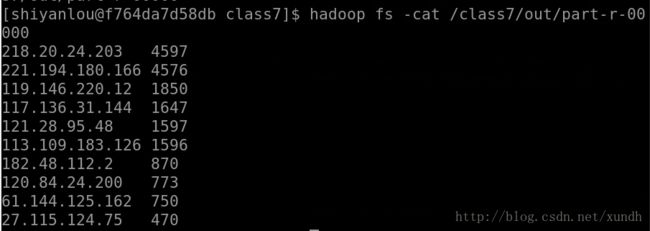
一些高级语法:
http://www.cnblogs.com/siwei1988/archive/2012/08/06/2624912.html