Dgraph学习笔记1
//2019.08.05
一、相关概念
1、Dgraph:大规模分布式图数据库,提供ACID,
Dgraph is a horizontally scalable and distributed graph database, providing ACID transactions, consistent replication and linearizable reads. It's built from ground up to perform for a rich set of queries. Being a native graph database, it tightly controls how the data is arranged on disk to optimize for query performance and throughput, reducing disk seeks and network calls in a cluster.
Dgraph's goal is to provide Google production level scale and throughput, with low enough latency to be serving real time user queries, over terabytes of structured data. Dgraph supports GraphQL-like query syntax, and responds in JSON and Protocol Buffers over GRPC and HTTP.
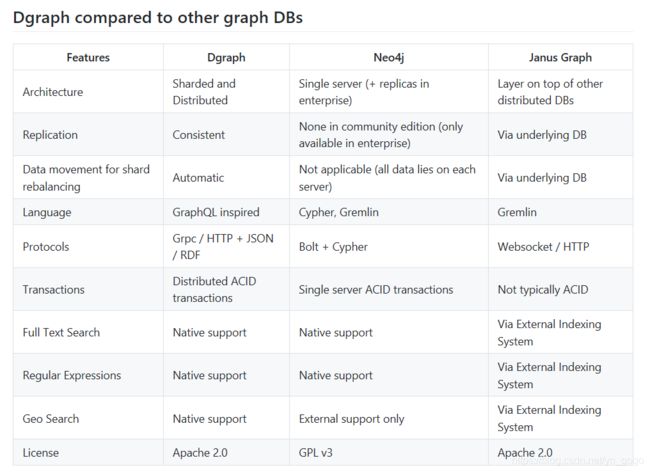
2、与其他数据库的比对
3、docker compose
(1)相关概念
*在使用docker时, 如果定义dockerfile文件,然后使用docker build 、docker run 等命令来操作容器,然而为服务器架构的应用系统一般包含若干个微服务,每个微服务会部署多个实例,如果每个都要手动启停,则效率太低。
*因而,docker compose 可以轻松、高效的管理容器,是一个用于定义和运行多容器docker的应用程序工具。
(2)相关操作
- 打包项目,获取jar包 mvn clean package
- 在jar包所在路径创建Dockerfile,添加内容
- 在jar包所在路径创建文件docker-compose.yml
- 在docker-compose.yml所在路径下执行该命令Compose就会自动构建镜像并使用镜像启动容器
docker-compose up(docker-compose up -d //后台启动并运行容器)
3、相关操作
(1)突变mutation:在Dgraph中添加或者删除数据
在这里有两种标准格式:RDF 和JSON,操作包含两个模式:Blank UID reference 或者 explicit UID reference
- ·Blank UID: _:michael and _:amit.
- Explicit UID: <0x4e030f>
"some new data" .
*只能引用存在的UIDs,如果对不存在的UID执行mutation,Dgraph将返回错误。使用blamk nodes创建新节点,Dgraph为新节点分配一个新的UID
(2)GraphQL+-的特性:
- 每个查询都有一个名字,返回结果也以该名字标记
- 检索条件 func:... 进行匹配
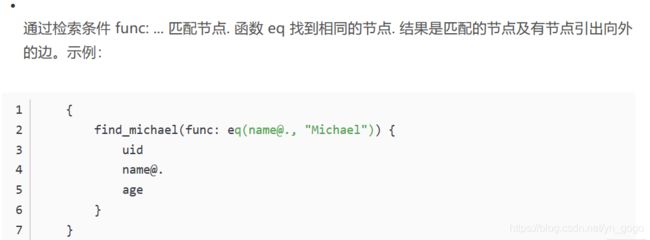
- 查询结果是图形,不是表或者数据列表
---------------------------------------------------------------------------------------------
Dgraph Tour
1、Install and run
*docker pull dgraph/dgraph
*执行:
mkdir -p ~/dgraph # Run dgraphzero docker run -it -p 5080:5080 -p 6080:6080 -p 8080:8080 -p 9080:9080 -p 8000:8000 -v ~/dgraph:/dgraph --name dgraph dgraph/dgraph dgraph zero # In another terminal, now run dgraph docker exec -it dgraph dgraph alpha --lru_mb 2048 --zero localhost:5080 # And in another, run ratel (Dgraph UI) docker exec -it dgraph dgraph-ratel
注意:该执行存在问题,Error while opening WAL store error: sync zw: invalid argument
2、Load Schema
*定义数据结构
name: string @index(term) @lang .
age: int @index(int) .
friend: uid @count .
3、load Data
存入数据
4、Mutation
向Dgraph中添加数据,增加或者删除数据。在这里有两种类型的标准形式:RDF和JSON.
对于mutation操作,包含两种模式,blank uid reference 和explicit uid reference
(1)空白节点的格式:_:unique name (RDF的形式)
“uid”:"_:diggy" (JSON形式)
(注意,在dgraph的bulk loader中任何拼写错误都会被当成空白节点)
(2)explicit uid
对一个已经存在的结点进行修改,可以采用explicit 节点,语法如下:
<0x4e030f>
(RDF形式)
"uid":"0x4e030f",
"somePredicate":"some new data"
(JSON形式)
*查找已知节点的uid的方式:
{ MyUser(func: eq(name, "Jack Torrance")) { uid } }
*只能引用已经存在的uid,如果写入一个未存在的uid,那么将会返回一个错误,对于一个新的节点,使用空白节点,然后分配给他新的uid
5、Graph图查询
Dgraph 具体查询语法
1、*每一次查询都有自己的一个名称,然后查询结果由着这个查询名称标记
2、func:...跟的这个查询条件匹配节点,
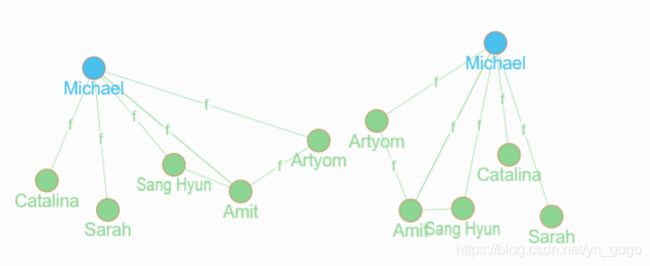
find_michael(func: eq(name@., "Michael")) 理解,这里面查询的名称是find_michael,然后查询条件是eq,即匹配名称为“michhael的人,结果是返回与其想匹配的结点和边。
3、uid是节点的唯一标识,不是边的,如果知道uid,可以直接写出func:uid( *也可以在里面设置返回 { 4、数据类型和Schema (在观察时,可视化界面有事不太好用,所有信息是显示在JSON中的) *在graph中有两种结点,一种叫做结点,一种叫做文字(值)(自己理解:类似于,结点A的id是xxx,在这里xxx就是文字结点) ,这种值的结点不能有边 Dgraph的数据类型 (对于结点,还有个uid类型) 5、查询可以通过指定要查询和返回的语言来进行标记文本搜寻 *此时需要遵循一定的规则: (1)至多有一个结果需要返回 (2) *left most of these 什么意思?????在不存在的情况下, preference list 是什么????(已经解决) 上面两个是加点和不加点的区别 { 个人理解:这里是寻找名字语言为这个 "अमित"的人,如果能查到,name后有相应的语言列表,如果其名称在这个语言列表中,那么将返回第一种语言;如果首选的语言不存在结果,则不会返回name这一项,除非语言列表以.结尾 问题:如果这样理解对的话,为什么还有其他的没有显示????没有明白加点和不加点的区别! 问题+理解:在理解Casade级联时,朋友的名称信息会有多种语言,在输出name时,发现,直接写name,只有单一名称会输出,但是多语言的名称不会显示;如果用name@.则会显示名称。 6、查询语言描述图 ·查询的结果是图,查询结果的结果对应查询的结构,构建结构时可以用一层层的{}来嵌套构建 7、函数和过滤器 (1)依赖于点的出边,一些节点可以根据函数进行过滤 (2)过滤不仅可以应用在最顶层的结点,也可以用于其他节点 (3)不过根目录下的过滤和内部块过滤的语法有一定的差异 (4)相关的过滤函数: The equalities and inequalities can be applied to edges of types: 例子: { 8、逻辑连接符 AND ,OR, NOT *这个可以在过滤时连接多个函数 friend @filter(ge(age, 27) AND le(age, 48)) { 9、排序 *可以将最后的结果进行排序,语句为“orderase”、“orderdesc”(在可视化界面上可能没有什么区别,但是在json结果集中是排序的) { 10、分页(Pagination) *查询结果可能会有很多页,如果想选择top-k的答案,那么可能要进行分页展示或者对一个大的结果集合进行限制 *在这里会结合排序做相应的选择 first,offset,after,注意,默认情况下,是按照uid进行的排序,具体如下: 11、计数 *在条件里面直接写就可以 { 12、高效使用Dgraph *对于一个大的图来说,从所有的结点搜寻不高效,所以要找到搜寻的根节点。; *对于根节点,抵用func:使用这个函数来寻找一系列的结点 *在上面的情况下,需要为值建立一个搜索的index,因为,如果没有index,将去遍历所有的数据库来找到匹配的值。 *对于根节点func:他仅仅接受一个单一的函数,不会接受AND\OR连接符号,如果还需要过滤,使用@filter(...)进行数据处理 13、Has函数 has(edge_name):返回具备这些名称的出边的结点 14、更改边的别名 *在输出图中可以更改边的别名 { 如上面的语句,将原图中的name变成了persons_name,在查询结果中输出的是persons_name 15、Casade 删除不具备所有匹配边的结点 问题:不明白具体的删除原理,不匹配指的是什么,那个匹配条件下,如果满足匹配条件,那原来的边算不算在里面???? 解决:查询了载入数据,发现只有几个person存在friend关系,很多关系是单向的。Casade的理解应该是,在查询中,不管{}里面显示的哪些关系,第一层的关系都会输出,也就说,在这里会显示Micheal的所有朋友,然后再将朋友的各个显示关系给加上;但是如果加上了Casade,会将其作为一个删选条件,不满足后面条件的朋友都会被删除掉。 16、规则化 *仅仅返回已经修改别名的边的列表,然后展平结果以删除嵌套 { 注意,重命名时,原名字和现在的名字可以重复 17、查询可以包含注释,注释用# 18、Facets:边属性 *支持facets:边上的键值对,作为三元组的一个扩展;例如,两个朋友间的一个朋友边可能有一个亲密朋友的boolean属性 *那么这个属性其实可以用作边的权重。 *细节文档:https://docs.dgraph.io/query-language/#facets-edge-attributes *JSON的改变:https://docs.dgraph.io/mutations/#facets 19、对一个单一的结点添加多重属性 有时,需要两个指向同一节点的不同的谓词边,这个可以用来描述节点的关系
michaels_friends(func: eq(name, "Michael")) {
name
age
friend {
age,
name@.
}
}
}
(大体的理解:{里面显示的是与查询的结点相关的属性信息,后面的friend是与之相连的关系,那么继续类比,friend跟的{是相关结点的信息内容}})
., in which case the value without a specified language is returned, or if there is no value without language, a value in “some” language is returned.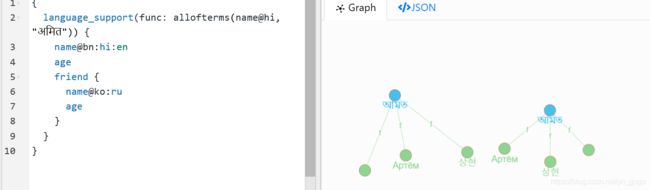
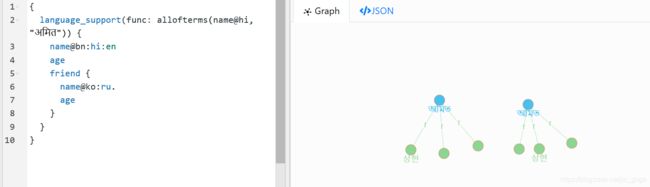
language_support(func: allofterms(name@hi, "अमित")) {
name@bn:hi:en
age
friend {
name@ko:ru
age
}
}
}
allOfTerms(edge_name, "term1 ... termN"): 匹配的结点的所有的出边要包含这些tem值anyOfTerms(edge_name, "term1 ... termN"): 匹配的结点所含有的出边至少要对应一个term值{
michaels_friends_filter(func: allofterms(name, "Michael")) {
name
age
friend @filter(ge(age, 27)) {
name@.
age
}
}
}int, float, string and date
eq(edge_name, value): equal toge(edge_name, value): greater than or equal tole(edge_name, value): less than or equal togt(edge_name, value): greater thanlt(edge_name, value): less than
michaels_friends_filter(func: allofterms(name, "Michael")) {
name
age
friend @filter(ge(age, 27)) {
name@.
age
}
}
}
name@.
age
}
michael_friends_sorted(func: allofterms(name, "Michael")) {
name
age
friend (orderasc: age) {
name@.
age
}
}
}
问题:这里取代了func还是说,这里不是过滤,仅仅就是对结果的一个处理???
first: N Return only the first N resultsoffset: N Skip the first N resultsafter: uid Return the results after uid(after的含义是,返回在这个uid之后的所有符合条件的结果值)
michael_number_friends(func: allofterms(name, "Michael")) {
name
age
count(friend) //还是对边关系的一个计算和整理
}
}
michael_number_friends(func: allofterms(name, "Michael")) {
persons_name : name
age
number_of_friends : count(friend)
}
}
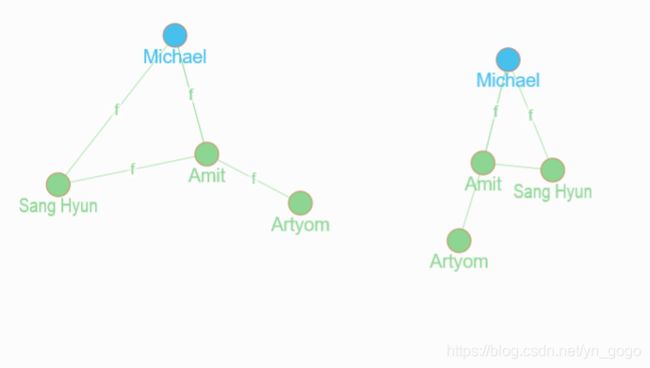
michael_number_friends(func: allofterms(name, "Michael")) @normalize {
name : name
age
number_of_friends : count(friend)
}
}