HDFS存储的机制之HDFS读写流程
转载于作者:tracy_668 链接:https://www.jianshu.com/p/12047b780595
写流程
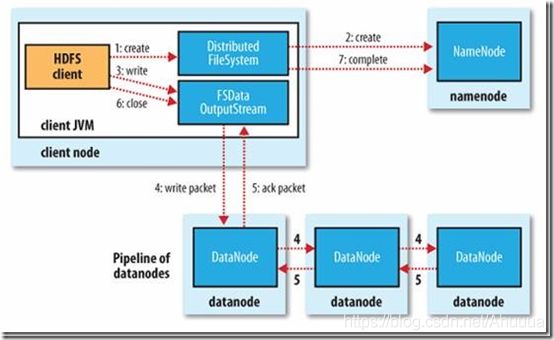
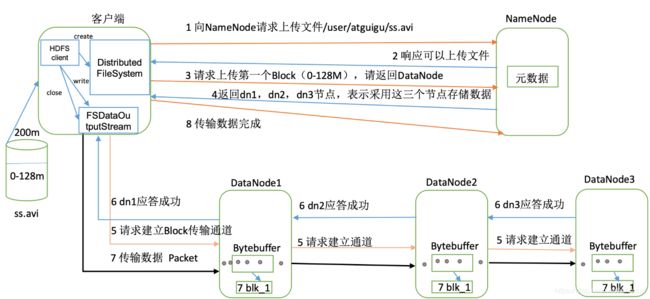
(7步)
1.
HDFS提供的客户端Client,向远程的Namenode发起RPC请求。
2.
Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作。
成功则会文件创建一个记录,否则会让客户端抛出异常。
3.
(a)当客户端Client开始写入文件的时候,客户端会将文件切分成多个packets,并在内部以数据队列“data queue"形式管理这些packets。
(b)然后客户端Client向Namenode申请blocks,并获取用来存储replications的合适的datanode列表。
namenode记录数据位置信息(元数据),告诉client存哪。
列表的大小根据Namenode中的replication值而定。
4.
开始以pipeline的形式将所有packet按副本数replications写入。
客户端Client把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline的下一个datanode,直到最后一个datanode(这几个datanode是packets的副本存放节点),这种写数据的方式呈流水线形式。
5.
(a)最后一个datanode(最后一个packet副本)成功存储之后会返回一个ack packet(确认队列),通过pipeline传递给客户端Client。
(b)在客户端的开发库内部维护着“ack queue”,客户端Client成功收到datanode返回的ack packet后会从“ack queue”移除相应的 packet。
(一个pipeline是针对一个block的,如图2中第5步建立传输通道所示)
6.
如果传输过程中, 有某个datanode出现了故障, 那么当前的pipeline会被关闭(应该是针对该故障datanode会关闭), 出现故障的datanode会从当前的pipeline中移除。
剩余的block会继续以pipeline的形式传输,同时Namenode会分配一个新的datanode, 保持replications设定的数量。
7.
客户端完成数据的写入后,会对数据流调用close(),关闭数据流。
namenode将元数据同步到内存中。
只要写入了dfs.replication.min的复本数( 默认为1),写操作就会成功, 并且这个块可以在集群中异步复制, 直到达到其目标复本数(replication的默认值为3),因为namenode已经知道文件由哪些块组成, 所以它在返回成功前只需要等待数据块进行最小量的复制。
读流程
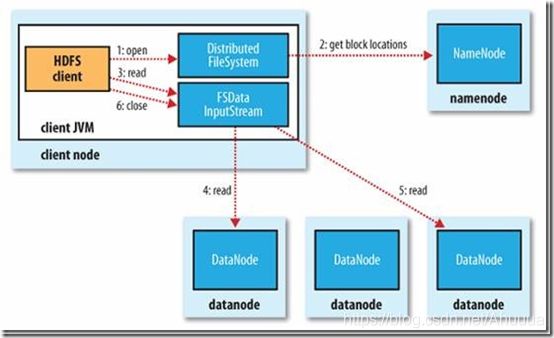
(5步)
1.
客户端(client)首先调用FileSystem的open()函数打开它想要打开的文件。
(对于HDFS来说就是通过DistributedFileSystem实例通过RPC调用请求元数据节点,得到组成文件的前几个数据块信息)
对于每一个数据块,元数据节点返回保存数据块的datanode地址(是分批次获取的,每次是几个数据块)这些datanode会按照与客户端的接近度(距离)来排序。
(如果客户端节点自己就是存放了目标数据块的datanode,就优先从本节点读取)
2.
DistributedFileSystem返回FSDataInputStream(支持文件seek的输入流)给客户端,客户端就能从流中读取数据了,FSDataInputStream中封装了一个管理了datanode与namenode IO的DFSInputStream。
3.
客户端调用read()方法开始读取数据,存储了文件前几个块的地址的DFSInputStream,就会链接存储了第一个块的第一个(最近的)datanode,然后DFSInputStream就通过重复调用read()方法,数据就从datanode流向了客户端。
当该datanode中最后一个快的读取完成了,DFSInputStream会关闭与datanode的连接,然后为下一块寻找最佳节点。
(这个过程对客户端是透明的,在客户端那边就像是读取了一个连续不断的流)
4.
块是顺序读取的,通过DFSInputStream在datanode上打开新的连接去作为客户端读取流,同样它也会请求namenode来获取下一批所需要的块所在的datanode地址。
当客户端完成了读取就在FSDataInpuStream上调用close()方法结束整个流程。
5.
在读取过程中,如果FSDataInputStream在和一个datanode进行交流时出现了一个错误,它就去试一试下一个最接近的块,同时也会记住刚才发生错误的datanode,之后便不会再在这个datanode上进行没必要的尝试。
DFSInputStream 也会在 datanode 上传输出的数据上核查检查数(checknums)。
如果损坏的块被发现了,DFSInputStream 就试图从另一个拥有备份的 datanode 中去读取备份块中的数据。
在这个设计中一个重要的方面是客户端直接从datanode上检索数据,并通过namenode指导来得到每一个块的最佳datanode。这种设计HDFS拓展大量的并发客户端,因为数据传输只是与集群上的所有datanode展开,namenode仅仅只需要服务于获取块位置的请求。而块位置信息是存放在内存中,所以效率很高,如果不这样设计,随着客户端数据量的增加,数据服务就会很快成为一个瓶颈 。