神经网络详细解释(包含BP算法的推导)
文章目录
- 单层神经网络结构
- 有意思的现象
- 常见的激活函数:
- 隐含层的神经网络结构
- 反向传播
- 交叉熵
- BP算法推导
- 计算输出层的激活函数的梯度
- 计算输出层的pre-activation的梯度
- 计算隐藏层的post-activation的梯度
- 计算隐藏层的pre-activation的梯度
- 计算参数 w 和 b w和b w和b的梯度
- BP算法总结
- 循环神经网络(RNN)
- 梯度消失和梯度爆炸的问题
- LSTM和GRU
- LSTM在神经元内部的操作
- GRU
- 结束
神经网络是在人工智能界是比较流行的一种模型。发展到今日已经有很多变种,想cnn,rnn,LSTM,对抗神经网络,等等很多网络结构,网上也有很多比较详细的解释,最近系统的学习了一下神经网络,包括网络结构细节,激活函数,正向传播,反向传播的推导,梯度的计算,过拟合的解决方式等等,想要系统的学习神经网络的同学看过来吧。嘿嘿!
单层神经网络结构
先从最简单的开始理解神经网络,如图(1),这是一个最简单的神经网络结构
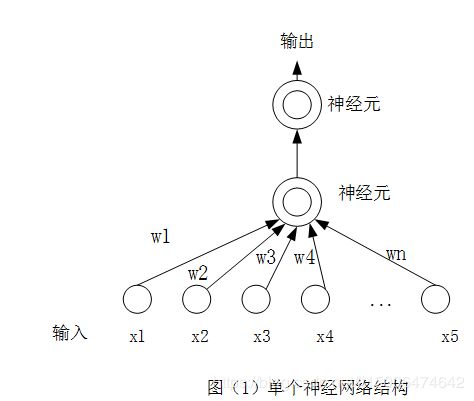
输入为:x1,x2,….xn。每个输入都对应一个权重w,那么将数据集x输入到神经元里面会有什么操作呢?如图(2)
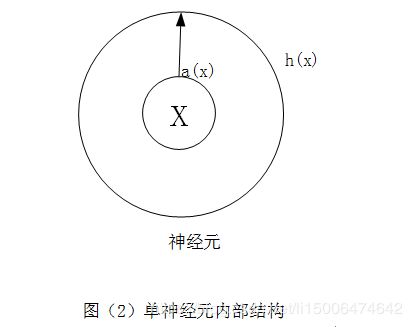
数据X输入到神经元后会经过两个操作:“a(x)”,和”h(x)” 后才能输出到下一个神经元中。我们也把a(x)称为pre-activation,h(x)称为post-activation,也就是第一步和第二步的意思。我们先看第一步a(x),a(x)是指对利用权重对数据进行一次线性转换,如公式(1)

简单来说就是将输入集
第二步h(x)是指的对a(x)进行一次非线性的转换,如公式(2)
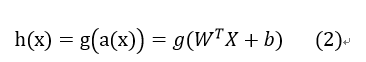
g(x)指的是激活函数,也就是对数据进行非线性转换的函数。如tanh,sigmold,relu等
那么问题来了,为什么要进行非线性的转换?
假设我们去掉h(x)这一步,每个神经元只经过a(x)也就是只有线性转换,那么我们的数据从第一个神经元到下一个神经元的过程就是 a 1 ( a ( x ) ) = w 1 T ( a ( x ) ) + b 1 a_{1}\left( a\left( x\right) \right) =w^{T}_{1}\left( a\left( x\right) \right) +b_{1} a1(a(x))=w1T(a(x))+b1再到下一个神经元为: a 2 ( a 1 ( a ( x ) ) ) = W 2 T a 1 ( a ( x ) ) + b 2 a_{2}\left(a_{1}\left( a\left( x\right) \right) \right )=W^{T}_{2}a_{1}\left( a\left( x\right) \right) +b_{2} a2(a1(a(x)))=W2Ta1(a(x))+b2
假定到此结束准备输出,我们展开公式:
a 2 ( a 1 ( a ( x ) ) ) = W 2 T a 1 ( a ( x ) ) + b 2 = W 2 T ( W 1 T a ( x ) + b 1 ) + b 2 = W 2 T ( W 1 T ( W T X + b ) + b 1 ) + b 2 = W 2 T W 1 T W T X + W 2 T W 1 T b + W 2 T b 1 + b 2 a_{2}\left(a_{1}\left( a\left( x\right) \right) \right )=W^{T}_{2}a_{1}\left( a\left( x\right) \right) +b_{2}=W^{T}_{2}\left( W^{T}_{1}a\left( x\right) +b_{1}\right) +b_{2}=W^{T}_{2}\left( W^{T}_{1}\left(W^{T}X+b\right) +b_{1}\right) +b_{2}=W^{T}_{2}W^{T}_{1}W^{T}X+W^{T}_{2}W^{T}_{1}b+W^{T}_{2}b_{1}+b_{2} a2(a1(a(x)))=W2Ta1(a(x))+b2=W2T(W1Ta(x)+b1)+b2=W2T(W1T(WTX+b)+b1)+b2=W2TW1TWTX+W2TW1Tb+W2Tb1+b2
由于W和b是常数,因此 W 2 T W 1 T W T X W^{T}_{2}W^{T}_{1}W^{T}X W2TW1TWTX可以写成 W c T X W^{T}_{c}X WcTX,还有 W 2 T W 1 T b + W 2 T b 1 + b 2 W^{T}_{2}W^{T}_{1}b+W^{T}_{2}b_{1}+b_{2} W2TW1Tb+W2Tb1+b2可以写成 b c b_{c} bc这样公式就可以写成:
a 2 ( a 1 ( a ( x ) ) ) = W c T X + b c a_{2}\left(a_{1}\left( a\left( x\right) \right) \right )=W^{T}_{c}X +b_{c} a2(a1(a(x)))=WcTX+bc
这样大家就会发现我们加这么多层神经元是没有意义的,最后还是变成一层的样子,所以我们在a(x)后加了非线性转换h(x)这样保证每层都是有意义的。因此激活函数比较的选择也是比较重要的
有意思的现象
如图(3)当单层神经网络,只有一个神经元并且激活函数是sigmold时,是此时 a ( x ) = W T X + b a(x) =W^{T}X+b a(x)=WTX+b,
g ( x ) = 1 1 + e − x g\left( x\right) =\dfrac {1}{1+e^{-x}} g(x)=1+e−x1
那么此时:
输 出 = h ( x ) = g ( w T x + b ) = 1 1 + e − ( w T x + b ) 输出=h\left( x\right)=g\left( w^{T}x+b\right)=\dfrac {1}{1+e^{-(w^{T}x+b)}} 输出=h(x)=g(wTx+b)=1+e−(wTx+b)1
而逻辑回归为:
p ( y ∣ x ) = 1 1 + e − ( w T x + b ) p(y|x)=\dfrac {1}{1+e^{-(w^{T}x+b)}} p(y∣x)=1+e−(wTx+b)1
所以说逻辑回归是神经网络的一个特例
常见的激活函数:
Linear activation(线性激活函数)
公式: g ( a ) = a g\left( a\right) =a g(a)=a
直接输出,没有任何意义,没有边界,输出多层相当于一层
Sigmold函数:
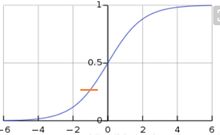
公式: g ( a ) = 1 1 + e − a g\left( a\right) =\dfrac {1}{1+e^{-a}} g(a)=1+e−a1
将输入映射到(0,1)之间 严格递增的函数
Tanh函数::

公式: y ( a ) = tanh ( a ) = e a − e − a e a + e − a y\left( a\right) =\tanh \left( a\right) =\dfrac {e^{a}-e^{-a}}{e^{a}+e^{-a}} y(a)=tanh(a)=ea+e−aea−e−a
将输入映射到(1,-1)之间 严格递增的函数
Relu:
公式: g ( a ) = R e L u ( a ) = max ( 0 , a ) g\left( a\right) =ReLu\left( a\right) =\max \left( 0,a\right) g(a)=ReLu(a)=max(0,a)
当a小于0时强制转换为0,严格递增的函数 无上限
隐含层的神经网络结构
上面讲的是只有一层直接输出的单层神经网络,下面说一下带有隐含层的神经网络,如图(4)
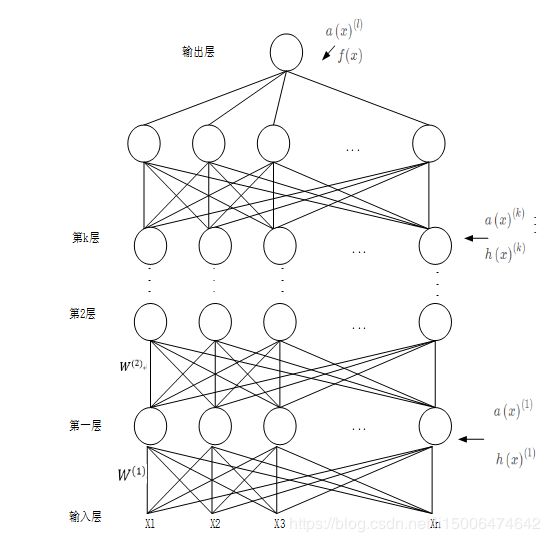
图(4)隐含层的网络结构
每一节点的细节都可以表示成图(5)

a ( x ) ( i ) a\left( x\right)^{(i)} a(x)(i)表示第 i i i层神经元的pre-activation
a ( x ) ( i ) = < a ( x 1 ) ( i ) , a ( x 2 ) ( i ) , a ( x 3 ) ( i ) . . . a ( x n ) ( i ) > a\left( x\right)^{(i)}=
h ( x ) ( i ) h\left( x\right)^{(i)} h(x)(i)表示第 j j j层神经元的post-activation
h ( x ) ( i ) = < h ( x 1 ) ( i ) , h ( x 2 ) ( i ) , h ( x 3 ) ( i ) . . . h ( x n ) ( i ) > h\left( x\right)^{(i)}=
W ( i ) W^{(i)} W(i)表示第 j j j层神经元的权重
W ( i ) = < w 1 ( i ) , w 2 ( i ) , w 3 ( i ) , w 4 ( i ) . . . , w n ( i ) , > W^{(i)}=
第一层可以表示成:
a ( x ) ( 1 ) = W ( 1 ) T X + b ( 1 ) a\left( x\right) ^{\left( 1\right) }=W^{\left( 1\right) ^{T}}X+b^{(1)} a(x)(1)=W(1)TX+b(1)
h ( x ) ( 1 ) = g ( a ( x ) ( 1 ) ) h\left( x\right)^{(1)}=g(a\left( x\right) ^{\left( 1\right) }) h(x)(1)=g(a(x)(1))
由第一层输入到第二层可以表示成:
a ( x ) ( 2 ) = W ( 1 ) T h ( x ) ( 2 ) + b ( 2 ) a\left( x\right) ^{\left( 2\right) }=W^{\left( 1\right) ^{T}}h\left( x\right)^{(2)}+b^{(2)} a(x)(2)=W(1)Th(x)(2)+b(2)
h ( x ) ( 2 ) = g ( a ( x ) ( 2 ) ) h\left( x\right)^{(2)}=g(a\left( x\right) ^{\left( 2\right) }) h(x)(2)=g(a(x)(2))
因此第k层可以表示成:
a ( x ) ( k ) = W k h ( x ) k − 1 + b ( k ) a\left( x\right) ^{\left( k\right) }=W^{k}h(x)^{k-1}+b^{(k)} a(x)(k)=Wkh(x)k−1+b(k)
h ( x ) ( k ) = g ( a ( x ) ( k ) ) h\left( x\right)^{(k)}=g(a\left( x\right) ^{\left( k\right) }) h(x)(k)=g(a(x)(k))
输出层的激活函数一般设置为softmax也就是 g ( x ) = σ ( x ) g\left( x\right)=\sigma (x) g(x)=σ(x)若在第l层输出
a ( x ) ( l ) = W l h ( x ) l − 1 + b ( l ) a\left( x\right) ^{\left( l\right) }=W^{l}h(x)^{l-1}+b^{(l)} a(x)(l)=Wlh(x)l−1+b(l)
h ( x ) ( l ) = g ( a ( x ) ( l ) ) = σ ( a ( x ) ( l ) ) h\left( x\right)^{(l)}=g(a\left( x\right) ^{\left( l\right) })=\sigma(a\left( x\right) ^{\left( l\right) }) h(x)(l)=g(a(x)(l))=σ(a(x)(l))
通常为了区分最后一层的激活函数与其他层不同,我们也常常设置 f ( x ) = h ( x ) ( l ) f(x)=h\left( x\right)^{(l)} f(x)=h(x)(l)
根据上面的步骤一直计算,直到最后一层输出 f ( x ) f(x) f(x)也就是完成了神经网络的正向传播
反向传播
假设数据标签为 y y y下一步我们要计算 y y y与 f ( x ) f(x) f(x)之间的差距,差距越小说明我们的模型越优秀,所以反向传播的目的就是不断减小 y y y与 f ( x ) f(x) f(x)之间的差距。所以神经网络的目标函数为公式:
a r g m i n : 1 T ∑ ∗ φ ( f ( x ( t ) ; θ ) , y ( t ) ) + λ Ω ( θ ) argmin:\dfrac {1}{T}\sum _{\ast }\varphi( f\left( x^{(t)};{\theta }\right) ,y^{(t)})+\lambda \Omega\left( \theta \right) argmin:T1∑∗φ(f(x(t);θ),y(t))+λΩ(θ)
θ \theta θ表示神经网络的所以参数:
θ = { ( W ( i ) , b ( i ) ) i = 1 l + 1 } \theta =\left\{ (W^{(i)},b^{(i)}) ^{l+1}_{i=1}\right\} θ={(W(i),b(i))i=1l+1}
f ( x ( t ) ; θ ) f\left( x^{(t)};{\theta }\right) f(x(t);θ)表示t时刻参数为 θ \theta θ时模型的输出
y ( t ) y^{(t)} y(t)表示t时刻的数据集标签
λ Ω ( θ ) \lambda \Omega\left( \theta \right) λΩ(θ)表示限制参数的正则
φ ( x , y ) \varphi( x,y) φ(x,y)表示损失函数,也就是技术 x 和 y x和y x和y的差异,常见的有交叉熵函数
目标函数可以转换成:
a r g m a x : − 1 T ∑ ∗ φ ( f ( x ( t ) ; θ ) , y ( t ) ) − λ Ω ( θ ) argmax:-\dfrac {1}{T}\sum _{\ast }\varphi( f\left( x^{(t)};{\theta }\right) ,y^{(t)})-\lambda \Omega\left( \theta \right) argmax:−T1∑∗φ(f(x(t);θ),y(t))−λΩ(θ)
像这样求目标函数的最大化时,我们最常用的就是随机梯度下降法(SGD):
第一步:初始化 θ = { W ( 1 ) , b ( 1 ) , . . . , W ( l + 1 ) , b ( l + 1 ) } \theta=\left\{ W^{(1)},b^{(1)},..., W^{(l+1)},b^{(l+1)}\right\} θ={W(1),b(1),...,W(l+1),b(l+1)}
第二步:循环每个batch: for batch in ( x t , y t ) (x^{t},y^{t}) (xt,yt):
循环体内部执行:
1、 Δ = − ∇ φ ( f ( x ( t ) ; θ ) , y ( t ) ) − λ ∇ Ω ( θ ) \Delta =-\nabla\varphi( f\left( x^{(t)};{\theta }\right) ,y^{(t)})-\lambda \nabla\Omega\left( \theta \right) Δ=−∇φ(f(x(t);θ),y(t))−λ∇Ω(θ)
2、 θ = θ + η Δ \theta=\theta+\eta\Delta θ=θ+ηΔ
η \eta η:表示步长
这两步也叫做bp算法
也就是说bp算法的核心目的就是求loss(损失函数)对于 θ \theta θ的导数,也就是求解: ∂ l o s s ∂ w ( k ) \dfrac {\partial loss}{\partial w^{\left( k\right) }} ∂w(k)∂loss和 ∂ l o s s ∂ b ( k ) \dfrac {\partial loss}{\partial b^{\left( k\right) }} ∂b(k)∂loss但是求这两个往往不能直接计算,因此必须依赖它传递的流程,从后往前依次求导,最后才能求出参数 θ \theta θ的导数
所以按照参数传递的顺序,可以分成5个部分:
1、f(x)作为最后一层的输出: ∂ l o s s ∂ f ( x ) \dfrac {\partial loss}{\partial f{\left( x\right) }} ∂f(x)∂loss
2、 a ( x ) ( l ) a\left( x\right) ^{\left( l\right) } a(x)(l)最后一层的pre-activation: ∂ l o s s ∂ a ( x ) ( l ) \dfrac {\partial loss}{\partial a\left( x\right) ^{\left( l\right) }} ∂a(x)(l)∂loss
3、 h ( x ) ( k ) h\left( x\right) ^{\left( k\right) } h(x)(k):激活后: ∂ l o s s ∂ h ( x ) ( k ) \dfrac {\partial loss}{\partial h\left( x\right) ^{\left( k\right) }} ∂h(x)(k)∂loss
4、 a ( x ) ( k ) a\left( x\right) ^{\left( k\right) } a(x)(k):激活前: ∂ l o s s ∂ a ( x ) ( k ) \dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right) }} ∂a(x)(k)∂loss
5、 W ( k ) 和 b ( k ) W^{(k)}和b^{(k)} W(k)和b(k)参数: ∂ l o s s ∂ w ( k ) \dfrac {\partial loss}{\partial w^{\left( k\right) }} ∂w(k)∂loss和 ∂ l o s s ∂ b ( k ) \dfrac {\partial loss}{\partial b^{\left( k\right) }} ∂b(k)∂loss
交叉熵
在计算梯度之前先来理解一下损失函数,常用的就是交叉熵
举个例子:
多分类问题:让神经网络判断输入的文本属于哪一类(共四类)
假设模型的输出为:属于第一类的概率为 f ( x ) 1 = 0.5 f(x)_1=0.5 f(x)1=0.5,属于第二类的概率为 f ( x ) 2 = 0.3 , f(x)_2=0.3, f(x)2=0.3,属于第三类的概率为 f ( x ) 3 = 0.1 f(x)_3=0.1 f(x)3=0.1,属于第四类的概率为 f ( x ) 4 = 0.1 f(x)_4=0.1 f(x)4=0.1,写成向量的形式就是 [ ( 0.5 ) ( 0.3 ) ( 0.1 ) ( 0.1 ) ] \begin{bmatrix}( 0.5)\\ \left( 0.3\right)\\ \left( 0.1\right)\\ \left( 0.1\right) \end{bmatrix} ⎣⎢⎢⎡(0.5)(0.3)(0.1)(0.1)⎦⎥⎥⎤,假如标签 y = 2 y=2 y=2对应成one-hot编码: [ 0 1 0 0 ] \begin{bmatrix}0\\1\\ 0\\ 0\end{bmatrix} ⎣⎢⎢⎡0100⎦⎥⎥⎤,则由交叉熵计算出的loss等于:
l o s s = ( 0 × log 0.5 + 1 × log 0.3 + 0 × log 0.1 + 0 × log 0.1 ) = − log 0.3 loss=( 0\times \log 0.5+1\times \log 0.3+0\times \log0.1+0\times \log0.1)=-\log0.3 loss=(0×log0.5+1×log0.3+0×log0.1+0×log0.1)=−log0.3
因此交叉熵的损失函数为:
φ ( f ( x ) ( i ) , y ( i ) ) = − ∑ c I ( y = c ) ⋅ log f ( x ) c = − log f ( x ) y \varphi( f(x)^{(i)},y^{(i)})=-\sum _{c}I( y=c)\cdot\log f(x)_c=-\log f(x)_y φ(f(x)(i),y(i))=−∑cI(y=c)⋅logf(x)c=−logf(x)y
I ( y = c ) = { 1 y = c 0 y ≠ c I_{( y= c)} =\begin{cases}1 \qquad y=c\\ 0\qquad y\neq c\end{cases} I(y=c)={1y=c0y=c
BP算法推导
计算输出层的激活函数的梯度
1、根据BP算法的核心思想首先计算输出层第c个神经元也就是 f ( x ) c f{\left( x\right)_c } f(x)c的梯度的梯度: ∂ l o s s ∂ f ( x ) c \dfrac {\partial loss}{\partial f{\left( x\right)_c }} ∂f(x)c∂loss
∂ l o s s ∂ f ( x ) c = ∂ − log f ( x ) y ∂ f ( x ) c = − 1 f ( x ) y ⋅ ∂ f ( x ) y ∂ f ( x ) c = − 1 f ( x ) y ⋅ I ( y = c ) \dfrac {\partial loss}{\partial f{\left( x\right)_c }}=\dfrac {\partial -\log f(x)_y}{\partial f{\left( x\right)_c }}=-\dfrac {1}{f\left( x\right) _{y}}\cdot\dfrac {\partial {f\left( x\right) _{y}}}{\partial f{\left( x\right) _c}}=-\dfrac {1}{f\left( x\right) _{y}}\cdot I( y=c) ∂f(x)c∂loss=∂f(x)c∂−logf(x)y=−f(x)y1⋅∂f(x)c∂f(x)y=−f(x)y1⋅I(y=c)
2、既然计算出输出层第c个神经元的梯度,下面计算整个输出层的梯度
∂ l o s s ∂ f ( x ) = − 1 f ( x ) y ⋅ [ I ( y = 1 ) I ( y = 2 ) I ( y = 3 ) . . . I ( y = k ) ] = − e ( y ) f ( x ) y \dfrac {\partial loss}{\partial f{\left( x\right) }}=-\dfrac {1}{f\left( x\right) _{y}}\cdot\begin{bmatrix}I(y=1)\\I(y=2)\\ I(y=3)\\ ...\\ I(y=k)\end{bmatrix}=-\dfrac {e(y)}{f\left( x\right) _{y}} ∂f(x)∂loss=−f(x)y1⋅⎣⎢⎢⎢⎢⎡I(y=1)I(y=2)I(y=3)...I(y=k)⎦⎥⎥⎥⎥⎤=−f(x)ye(y)
用这里只是用 e ( y ) e(y) e(y)来表示 [ I ( y = 1 ) I ( y = 2 ) I ( y = 3 ) . . . I ( y = k ) ] \begin{bmatrix}I(y=1)\\I(y=2)\\ I(y=3)\\ ...\\ I(y=k)\end{bmatrix} ⎣⎢⎢⎢⎢⎡I(y=1)I(y=2)I(y=3)...I(y=k)⎦⎥⎥⎥⎥⎤
计算输出层的pre-activation的梯度
主要是用来计算 a ( x ) ( l ) a\left( x\right) ^{\left( l\right) } a(x)(l)最后一层的-activation: ∂ l o s s ∂ a ( x ) ( l ) \dfrac {\partial loss}{\partial a\left( x\right) ^{\left( l\right) }} ∂a(x)(l)∂loss
首先来计算第c神经元的向量 a ( x ) c ( l ) a\left( x\right) _c^{\left( l\right) } a(x)c(l):
∂ l o s s ∂ a ( x ) c ( l ) = ∂ − log f ( x ) y ∂ a ( x ) c ( l ) = − 1 f ( x ) y ⋅ ∂ f ( x ) y ∂ a ( x ) c ( l ) = − 1 f ( x ) y ⋅ ∂ ∂ a ( x ) c ( l ) ⋅ e ( a ( x ) y ( l ) ) ∑ c ⋅ e ( a ( x ) c ⋅ ( l ) ) \dfrac {\partial loss}{\partial a\left( x\right)_c ^{\left( l\right) }}=\dfrac {\partial -\log f(x)_y}{\partial a\left( x\right)_c ^{\left( l\right) }}=-\dfrac {1}{f\left( x\right) _{y}}\cdot\dfrac {\partial {f\left( x\right) _{y}}}{\partial a\left( x\right)_c ^{\left( l\right) }}=-\dfrac {1}{f\left( x\right) _{y}}\cdot\dfrac {\partial {}}{\partial a\left( x\right)_c ^{\left( l\right) }}\cdot\dfrac {e^{\left( a\left( x\right) _{y}^{\left(l\right) }\right)} }{\sum _{c^·}{e^{\left( a\left( x\right) _{c^·}^{\left(l\right) }\right)} }} ∂a(x)c(l)∂loss=∂a(x)c(l)∂−logf(x)y=−f(x)y1⋅∂a(x)c(l)∂f(x)y=−f(x)y1⋅∂a(x)c(l)∂⋅∑c⋅e(a(x)c⋅(l))e(a(x)y(l))
= − 1 f ( x ) y =-\dfrac {1}{f\left( x\right) _{y}} =−f(x)y1 ⋅ ( ∂ e ( a ( x ) y ( l ) ) ∂ a ( x ) c ( l ) ∑ c ⋅ e ( a ( x ) c ⋅ ( l ) ) − e ( a ( x ) y ( l ) ) ⋅ ∂ ∑ c ⋅ e ( a ( x ) c ⋅ ( l ) ) ∂ a ( x ) c ( l ) ( ∑ c ⋅ e ( a ( x ) c ⋅ ( l ) ) ) 2 ) \cdot(\dfrac {\dfrac {\partial {e^{\left( a\left( x\right) _{y}^{\left(l\right) }\right)}}}{\partial a\left( x\right)_c ^{\left( l\right) }}}{\sum _{c^·}{e^{\left( a\left( x\right) _{c^·}^{\left(l\right) }\right)} }}-\dfrac {e^{\left( a\left( x\right) _{y}^{\left(l\right) }\right)}\cdot\dfrac {\partial { \sum _{c^·}{e^{\left( a\left( x\right) _{c^·}^{\left(l\right) }\right)} } }}{\partial a\left( x\right)_c ^{\left( l\right) }}}{(\sum _{c^·}{e^{\left( a\left( x\right) _{c^·}^{\left(l\right) }\right)} })^2}) ⋅(∑c⋅e(a(x)c⋅(l))∂a(x)c(l)∂e(a(x)y(l))−(∑c⋅e(a(x)c⋅(l)))2e(a(x)y(l))⋅∂a(x)c(l)∂∑c⋅e(a(x)c⋅(l)))
= − 1 f ( x ) y ⋅ =-\dfrac {1}{f\left( x\right) _{y}}\cdot =−f(x)y1⋅ ( e ( a ( x ) y ( l ) ) ⋅ I ( y = c ) ∑ c ⋅ e ( a ( x ) c ⋅ ( l ) ) − e ( a ( x ) y ( l ) ) ⋅ e ( a ( x ) c ( l ) ) ∑ c ⋅ e ( a ( x ) c ⋅ ( l ) ) ⋅ ∑ c ⋅ e ( a ( x ) c ⋅ ( l ) ) ) ( \dfrac {{{e^{\left( a\left( x\right) _{y}^{\left(l\right) }\right)\cdot I_{(y=c)}}}}}{\sum _{c^·}{e^{\left( a\left( x\right) _{c^·}^{\left(l\right) }\right)} }} - \dfrac {{{e^{\left( a\left( x\right) _{y}^{\left(l\right) }\right)}}}\cdot{e^{\left( a\left( x\right) _{c}^{\left(l\right) }\right)}}}{\sum _{c^·}{e^{\left( a\left( x\right) _{c^·}^{\left(l\right) }\right)} }\cdot{\sum _{c^·}{e^{\left( a\left( x\right) _{c^·}^{\left(l\right) }\right)}}}} ) (∑c⋅e(a(x)c⋅(l))e(a(x)y(l))⋅I(y=c)−∑c⋅e(a(x)c⋅(l))⋅∑c⋅e(a(x)c⋅(l))e(a(x)y(l))⋅e(a(x)c(l)))
= − 1 f ( x ) y =-\dfrac {1}{f\left( x\right) _{y}} =−f(x)y1 ⋅ \cdot ⋅ ( s o f t m a x ( ( a ( x ) y ( l ) ) ) ⋅ I ( y = c ) − s o f t m a x ( ( a ( x ) y ( l ) ) ) ⋅ s o f t m a x ( ( a ( x ) c ( l ) ) ) ) (softmax({\left( a\left( x\right) _{y}^{\left(l\right) }\right)})\cdot I_{(y=c)}-softmax({\left( a\left( x\right) _{y}^{\left(l\right) }\right)})\cdot softmax({\left( a\left( x\right) _{c}^{\left(l\right) }\right)})) (softmax((a(x)y(l)))⋅I(y=c)−softmax((a(x)y(l)))⋅softmax((a(x)c(l))))
= − 1 f ( x ) y ( f ( x ) y ⋅ I ( y = c ) − f ( x ) y ⋅ f ( x ) c ) =-\dfrac {1}{f\left( x\right) _{y}}(f\left( x\right) _{y}\cdot I_{(y=c)}-f\left( x\right) _{y}\cdot f\left( x\right) _{c}) =−f(x)y1(f(x)y⋅I(y=c)−f(x)y⋅f(x)c) = − ( I ( y = c ) − f ( x ) c ) = f ( x ) c − I ( y = c ) =-(I_{(y=c)}- f\left( x\right) _{c})=f\left( x\right) _{c}-I_{(y=c)} =−(I(y=c)−f(x)c)=f(x)c−I(y=c)
最后计算出: ∂ l o s s ∂ a ( x ) c ( l ) = f ( x ) c − I ( y = c ) \dfrac {\partial loss}{\partial a\left( x\right)_c ^{\left( l\right) }}=f\left( x\right) _{c}-I_{(y=c)} ∂a(x)c(l)∂loss=f(x)c−I(y=c)
这只是计算输出层第c个神经元的pre-activation,那么计算输出层的pre-activation就是 (参考第一步): ∂ l o s s ∂ a ( x ) ( l ) = f ( x ) − e ( y ) \dfrac {\partial loss}{\partial a\left( x\right) ^{\left( l\right) }}=f\left( x\right)-e(y) ∂a(x)(l)∂loss=f(x)−e(y)
计算隐藏层的post-activation的梯度
计算每层 的post-activation,也就是计算 h ( x ) ( k ) h\left( x\right) ^{\left( k\right) } h(x)(k): ∂ l o s s ∂ h ( x ) ( k ) \dfrac {\partial loss}{\partial h\left( x\right) ^{\left( k\right) }} ∂h(x)(k)∂loss
还是先计算第c个神经元的post-activation: ∂ l o s s ∂ h ( x ) c ( k ) \dfrac {\partial loss}{\partial h\left( x\right) ^{\left( k\right) }_c} ∂h(x)c(k)∂loss
直接求 ∂ l o s s ∂ h ( x ) c ( k ) \dfrac {\partial loss}{\partial h\left( x\right) ^{\left( k\right) }_c} ∂h(x)c(k)∂loss比较难求,我们来做一个转换也叫梯度的链式求解法则:

所以我们采用链式求解法则进行计算:
∂ l o s s ∂ h ( x ) c ( k ) = \dfrac {\partial loss}{\partial h\left( x\right) ^{\left( k\right) }_c}= ∂h(x)c(k)∂loss= ∑ i ∂ l o s s ∂ a ( x ) i ( k + 1 ) ⋅ ∂ a ( x ) i ( k + 1 ) ∂ h ( x ) c ( k ) \sum_i \dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k+1\right) }_i}\cdot \dfrac {\partial a\left( x\right) ^{\left( k+1\right) }_i}{\partial h\left( x\right) ^{\left( k\right) }_c} ∑i∂a(x)i(k+1)∂loss⋅∂h(x)c(k)∂a(x)i(k+1) = = = ∑ i ∂ − log f ( x ) y ∂ a ( x ) i ( k + 1 ) ⋅ ∂ ∑ j W i j ( k + 1 ) ⋅ h ( x ) j ( k ) ∂ h ( x ) c ( k ) \sum_i \dfrac {\partial -\log f(x)_y}{\partial a\left( x\right) ^{\left( k+1\right) }_i} \cdot \dfrac {\partial \sum _{j}W^{\left( k+1\right) }_{ij}\cdot h\left( x\right)_j^{(k)}}{\partial h\left( x\right) ^{\left( k\right) }_c} ∑i∂a(x)i(k+1)∂−logf(x)y⋅∂h(x)c(k)∂∑jWij(k+1)⋅h(x)j(k)
= ∑ i ∂ − log f ( x ) y ∂ a ( x ) i ( k + 1 ) ⋅ W i j ( k + 1 ) = ( W . j ( k + 1 ) ) T ⋅ ∂ − log f ( x ) y ∂ a ( x ) ( k + 1 ) \sum_i \dfrac {\partial -\log f(x)_y}{\partial a\left( x\right) ^{\left( k+1\right) }_i} \cdot W^{\left( k+1\right) }_{ij}=(W^{\left( k+1\right) }_{.j})^T\cdot \dfrac {\partial -\log f(x)_y}{\partial a\left( x\right) ^{\left( k+1\right) }} ∑i∂a(x)i(k+1)∂−logf(x)y⋅Wij(k+1)=(W.j(k+1))T⋅∂a(x)(k+1)∂−logf(x)y
对于k层的所有神经元的梯度计算:
∂ l o s s ∂ h ( x ) ( k ) = ( W ( k + 1 ) ) T ⋅ ∂ − log f ( x ) y ∂ a ( x ) ( k + 1 ) \dfrac {\partial loss}{\partial h\left( x\right) ^{\left( k\right) }}=(W^{\left( k+1\right) })^T\cdot \dfrac {\partial -\log f(x)_y}{\partial a\left( x\right) ^{\left( k+1\right) }} ∂h(x)(k)∂loss=(W(k+1))T⋅∂a(x)(k+1)∂−logf(x)y
计算隐藏层的pre-activation的梯度
同理,我们先计算第k层第c个神经元的pre-activation: ∂ l o s s ∂ a ( x ) c ( k ) \dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right)}_c} ∂a(x)c(k)∂loss
∂ l o s s ∂ a ( x ) c ( k ) \dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right)}_c} ∂a(x)c(k)∂loss= ∂ l o s s ∂ h ( x ) c ( k ) ⋅ ∂ h ( x ) c ( k ) ∂ a ( x ) c ( k ) = ∂ l o s s ∂ h ( x ) c ( k ) ⋅ g ′ ( a ( x ) c ( k ) ) \dfrac {\partial loss}{\partial h\left( x\right) ^{\left( k\right) }_c}\cdot\dfrac {\partial h\left( x\right) ^{\left( k\right) }_c}{\partial a\left( x\right) ^{\left( k\right)}_c}=\dfrac {\partial loss}{\partial h\left( x\right) ^{\left( k\right) }_c}\cdot g^{'}(a(x)^{(k)}_c) ∂h(x)c(k)∂loss⋅∂a(x)c(k)∂h(x)c(k)=∂h(x)c(k)∂loss⋅g′(a(x)c(k))
对于k层所有神经元post-activation计算:
∂ l o s s ∂ a ( x ) ( k ) = ∂ l o s s ∂ h ( x ) c ( k ) ⊙ g ′ ( a ( x ) ( k ) ) \dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right)}}=\dfrac {\partial loss}{\partial h\left( x\right) ^{\left( k\right) }_c}\odot g^{'}(a(x)^{(k)}) ∂a(x)(k)∂loss=∂h(x)c(k)∂loss⊙g′(a(x)(k))
计算参数 w 和 b w和b w和b的梯度
先计算k层第i个神经元对应的第j个权重 w i j ( k ) w_{ij}^{(k)} wij(k): ∂ l o s s ∂ w i j ( k ) \qquad\dfrac {\partial loss}{\partial w_{ij} ^{\left( k\right)}} ∂wij(k)∂loss
∂ l o s s ∂ w i j ( k ) = ∂ l o s s ∂ a ( x ) i ( k ) ⋅ ∂ a ( x ) i ( k ) ∂ w i j ( k ) = ∂ l o s s ∂ a ( x ) i ( k ) ⋅ ∂ ∑ j W i j ( k ) ⋅ h ( x ) j ( k − 1 ) + b i j ( k ) ∂ w i j ( k ) = ∂ l o s s ∂ a ( x ) i ( k ) ⋅ h ( x ) j ( k − 1 ) \dfrac {\partial loss}{\partial w_{ij} ^{\left( k\right)}}=\dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right) }_i}\cdot\dfrac {\partial a\left( x\right) ^{\left( k\right) }_i}{\partial w_{ij} ^{\left( k\right)}}=\dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right) }_i}\cdot\dfrac {\partial \sum _{j}W^{\left( k\right) }_{ij}\cdot h\left( x\right)_j^{(k-1)}+b_{ij}^{(k)}}{\partial w_{ij} ^{\left( k\right)}}=\dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right) }_i}\cdot h\left( x\right)_j^{(k-1)} ∂wij(k)∂loss=∂a(x)i(k)∂loss⋅∂wij(k)∂a(x)i(k)=∂a(x)i(k)∂loss⋅∂wij(k)∂∑jWij(k)⋅h(x)j(k−1)+bij(k)=∂a(x)i(k)∂loss⋅h(x)j(k−1)
对于k层所有的权重 w ( k ) w^{(k)} w(k):
∂ l o s s ∂ w ( k ) = ∂ l o s s ∂ a ( x ) ( k ) ⋅ ( h ( x ) ( k − 1 ) ) T \dfrac {\partial loss}{\partial w^{\left( k\right)}}=\dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right) }}\cdot (h\left( x\right)^{(k-1)})^T ∂w(k)∂loss=∂a(x)(k)∂loss⋅(h(x)(k−1))T
再计算k层第i个神经元对应的第j个偏置 b i j ( k ) b_{ij}^{(k)} bij(k): ∂ l o s s ∂ b i j ( k ) \qquad\dfrac {\partial loss}{\partial b_{ij} ^{\left( k\right)}} ∂bij(k)∂loss
∂ l o s s ∂ b i j ( k ) = ∂ l o s s ∂ a ( x ) i ( k ) ⋅ ∂ a ( x ) i ( k ) ∂ b i j ( k ) = ∂ l o s s ∂ a ( x ) i ( k ) ⋅ ∂ ∑ j W i j ( k ) ⋅ h ( x ) j ( k − 1 ) + b i j ( k ) ∂ b i j ( k ) = ∂ l o s s ∂ a ( x ) i ( k ) \dfrac {\partial loss}{\partial b_{ij} ^{\left( k\right)}}=\dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right) }_i}\cdot\dfrac {\partial a\left( x\right) ^{\left( k\right) }_i}{\partial b_{ij} ^{\left( k\right)}}=\dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right) }_i}\cdot\dfrac {\partial \sum _{j}W^{\left( k\right) }_{ij}\cdot h\left( x\right)_j^{(k-1)}+b_{ij}^{(k)}}{\partial b_{ij} ^{\left( k\right)}}=\dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right) }_i} ∂bij(k)∂loss=∂a(x)i(k)∂loss⋅∂bij(k)∂a(x)i(k)=∂a(x)i(k)∂loss⋅∂bij(k)∂∑jWij(k)⋅h(x)j(k−1)+bij(k)=∂a(x)i(k)∂loss
对于k层所有的权重 b ( k ) b^{(k)} b(k):
∂ l o s s ∂ b ( k ) = ∂ l o s s ∂ a ( x ) ( k ) \dfrac {\partial loss}{\partial b^{\left( k\right)}}=\dfrac {\partial loss}{\partial a\left( x\right) ^{\left( k\right) }} ∂b(k)∂loss=∂a(x)(k)∂loss
BP算法总结
根据上面有一点点小复杂的计算我们可以知道:
输出层的梯度:
∇ f ( x ) = − e ( y ) f ( x ) y \nabla f(x)=-\dfrac {e(y)}{f\left( x\right) _{y}} ∇f(x)=−f(x)ye(y)
∇ a ( x ) ( l ) = f ( x ) − e ( y ) \nabla a(x)^{(l)}=f\left( x\right)-e(y) ∇a(x)(l)=f(x)−e(y)
隐藏层的梯度:
∇ h ( x ) ( k ) = ( W ( k + 1 ) ) T ⋅ ∇ a ( x ) ( k + 1 ) \nabla h (x)^{(k)}=(W^{\left( k+1\right) })^T\cdot\nabla a(x)^{(k+1)} ∇h(x)(k)=(W(k+1))T⋅∇a(x)(k+1)
∇ a ( x ) ( k ) = ∇ h ( x ) ( k ) ⊙ g ′ ( a ( x ) ( k ) ) \nabla a(x)^{(k)}=\nabla h (x)^{(k)}\odot g^{'}(a(x)^{(k)}) ∇a(x)(k)=∇h(x)(k)⊙g′(a(x)(k))
参数的梯度:
∇ w ( k ) = ∇ a ( x ) ( k ) ⋅ ( h ( x ) ( k − 1 ) ) T \nabla w^{(k)}=\nabla a(x)^{(k)}\cdot (h\left( x\right)^{(k-1)})^T ∇w(k)=∇a(x)(k)⋅(h(x)(k−1))T
∇ b ( k ) = ∇ a ( x ) ( k ) \nabla b^{(k)}=\nabla a(x)^{(k)} ∇b(k)=∇a(x)(k)
总结
所以神经网络计算大约有3步:
1、前向计算
2、反向传播计算梯度
3、更新参数
到此一个基本神经网络的就了解的差不多了下面,再聊一下RNN吧
循环神经网络(RNN)
在我们的生活中是有很多的时序性的数据,比如:语音,天气,股票,文本都是随时间的 变化而变化的,为了处理这样的数据,设计了一种循环神经网络也叫递归神经网络RNN如图(6)

如图(6)所示t=1时刻时我们输入数据 x 1 x_1 x1,和神经网络一样先进行线性的转化pre-activation在进行非线性的转化post-activation :
当 t = 1 t=1 t=1时:
h 1 = f ( w x 1 ⋅ x 1 + w h 1 ⋅ h 0 + b t 1 ) h_1=f(w_{x1}\cdot x_1+w_{h1}\cdot h_0 +b_{t1}) h1=f(wx1⋅x1+wh1⋅h0+bt1)
f ( x ) f(x) f(x)表示激活函数, h 0 h_0 h0一般设置为0 , b t 1 b_{t1} bt1表示偏置
y 1 = g ( w y 1 ⋅ h 1 + b i 1 ) y_1=g(w_{y1}\cdot h_1 +b_{i1}) y1=g(wy1⋅h1+bi1)
g ( x ) g(x) g(x)表示激活函数, b i 1 b_{i1} bi1表示输出层的偏置
当 t = 2 t=2 t=2时:
h 2 = f ( w x 2 ⋅ x 2 + w h 2 ⋅ h 1 + b t 2 ) h_2=f(w_{x2}\cdot x_2+w_{h2}\cdot h_1 +b_{t2}) h2=f(wx2⋅x2+wh2⋅h1+bt2)
f ( x ) f(x) f(x)表示激活函数 , b t 2 b_{t2} bt2表示偏置
y 2 = g ( w y 2 ⋅ h 2 + b i 2 ) y_2=g(w_{y2}\cdot h_2 +b_{i2}) y2=g(wy2⋅h2+bi2)
当 t = n t=n t=n时:
h n = f ( w x n ⋅ x n + w h n ⋅ h ( n − 1 ) + b t n ) h_n=f(w_{xn}\cdot x_n+w_{hn}\cdot h_{(n-1)} +b_{tn}) hn=f(wxn⋅xn+whn⋅h(n−1)+btn)
y n = g ( w y n ⋅ h n + b i n ) y_n=g(w_{yn}\cdot h_n +b_{in}) yn=g(wyn⋅hn+bin)
从公式中我们可以看出当时间到了 n n n时 h n h_n hn不仅包含了当前数据信息,还包含了前面数据的信息,那对应输出的 y n y_n yn也是包含整个文本信息的输出,假设n为最后一层,我们常常用 y n y_n yn来表示句子信息和段落信息用来处理我们的下游任务。
而且每一层都会有损失函数的计算,所有损失函数是: l o s s = ∑ i n l o s s i loss=\sum_i^nloss_i loss=∑inlossi
可以看出rnn是随着时间的增加,层数也在不断的增加,因此,rnn是在时间维度上的Deep Model
梯度消失和梯度爆炸的问题
为什么会出现梯度消失和梯度爆炸的问题呢?我们用数学公式来进行说明:
在rnn中假设我们计算 t = 4 t=4 t=4时刻的对 h 1 h_1 h1的梯度,也就 l o s s 4 loss_4 loss4时的梯度: ∂ l 4 ∂ h 1 \dfrac {\partial l_4}{\partial h _1} ∂h1∂l4
一般情况下我们无法直接计算 ∂ l 4 ∂ h 1 \dfrac {\partial l_4}{\partial h _1} ∂h1∂l4,因此使用链式求导法则来进行计算 :
∂ l 4 ∂ h 1 = ∂ l 4 ∂ h 2 ⋅ ∂ h 2 ∂ h 1 = ∂ l 4 ∂ h 3 ⋅ ∂ h 3 ∂ h 2 ⋅ ∂ h 2 ∂ h 1 = ∂ l 4 ∂ h 4 ⋅ ∂ h 4 ∂ h 3 ⋅ ∂ h 3 ∂ h 2 ⋅ ∂ h 2 ∂ h 1 \dfrac {\partial l_4}{\partial h _1}=\dfrac {\partial l_4}{\partial h _2}\cdot\dfrac {\partial h_2}{\partial h _1}=\dfrac {\partial l_4}{\partial h _3}\cdot\dfrac {\partial h_3}{\partial h _2}\cdot\dfrac {\partial h_2}{\partial h _1}=\dfrac {\partial l_4}{\partial h _4}\cdot\dfrac {\partial h_4}{\partial h _3}\cdot\dfrac {\partial h_3}{\partial h _2}\cdot\dfrac {\partial h_2}{\partial h _1} ∂h1∂l4=∂h2∂l4⋅∂h1∂h2=∂h3∂l4⋅∂h2∂h3⋅∂h1∂h2=∂h4∂l4⋅∂h3∂h4⋅∂h2∂h3⋅∂h1∂h2
将计算过程扩展一下为:
∂ l i ∂ h j = ∂ l i ∂ h i ⋅ ∏ j ≤ t ≤ i ∂ h t ∂ h t − 1 \dfrac {\partial l_i}{\partial h _j}=\dfrac {\partial l_i}{\partial h _i}\cdot\prod _{j\leq t\leq i}\dfrac {\partial h_t}{\partial h _{t-1}} ∂hj∂li=∂hi∂li⋅∏j≤t≤i∂ht−1∂ht
若激活函数用sigmold则:
h t = σ ( w x t ⋅ x t + w h t ⋅ h ( t − 1 ) + b t t ) h_t=\sigma(w_{xt}\cdot x_t+w_{ht}\cdot h_{(t-1)} +b_{tt}) ht=σ(wxt⋅xt+wht⋅h(t−1)+btt)
∂ h t ∂ h t − 1 = d i a g ( σ 、 ( w x t ⋅ x t + w h t ⋅ h ( t − 1 ) + b t t ) ) ⋅ w h t \dfrac {\partial h_t}{\partial h _{t-1}}=diag(\sigma^、(w_{xt}\cdot x_t+w_{ht}\cdot h_{(t-1)} +b_{tt}))\cdot w_{ht} ∂ht−1∂ht=diag(σ、(wxt⋅xt+wht⋅h(t−1)+btt))⋅wht
d i a g diag diag:指的是对矩阵的处理,因为 h t h_t ht和 h t − 1 h_{t-1} ht−1是向量的形式,因此求导的结果是矩阵。因此:
∂ l i ∂ h j = ∂ l i ∂ h i ⋅ ∏ j ≤ t ≤ i d i a g ( σ 、 ( w x t ⋅ x t + w h t ⋅ h ( t − 1 ) + b t t ) ) ⋅ w h t \dfrac {\partial l_i}{\partial h _j}=\dfrac {\partial l_i}{\partial h _i}\cdot\prod _{j\leq t\leq i}diag(\sigma^、(w_{xt}\cdot x_t+w_{ht}\cdot h_{(t-1)} +b_{tt}))\cdot w_{ht} ∂hj∂li=∂hi∂li⋅∏j≤t≤idiag(σ、(wxt⋅xt+wht⋅h(t−1)+btt))⋅wht
根据公式我们可以看出,当 j > i j>i j>i很多时,计算 ∂ l i ∂ h j \dfrac {\partial l_i}{\partial h _j} ∂hj∂li我们需要乘以很多很多的项,如果这些项都小于0的话,那在计算梯度时会越乘越小,有可能导致梯度很小导致梯度消失,如果这些项都大于0的话就会越乘越大,就有可能导致梯度爆炸。
LSTM和GRU
由上面我们知道,rnn有可能造成梯度消失的问题(爆炸的问题比较好解决就不细说了)这样就会带来特征提取的不够长,因此我们又发明了LSTM和GRU
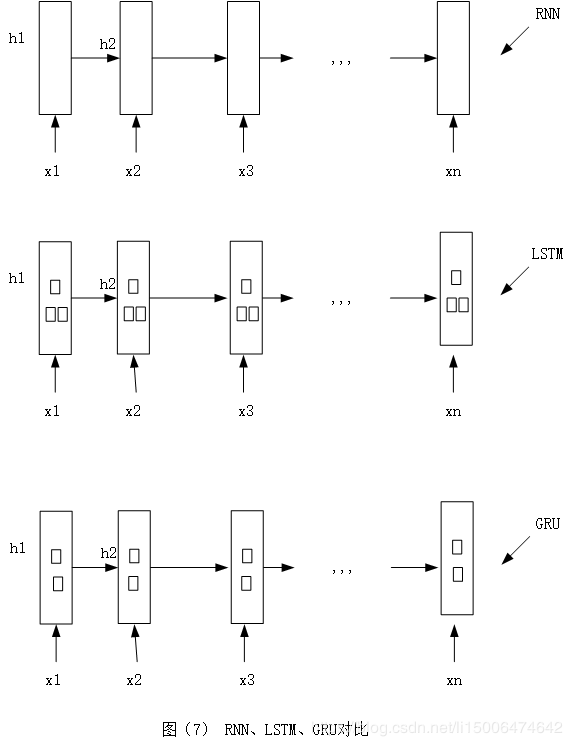
从图(7)我们可以看出RNN和LSTM还有GRU外形其实是差不多,只是LSTM和GRU比RNN多了几个门,也就是多了几个操作,我们先看一下
LSTM在神经元内部的操作
:
f ( t ) = σ ( u f ⋅ x t + w f ⋅ h t − 1 + b f ) f^{(t)}=\sigma(u_{f}\cdot x_t+w_{f}\cdot h_{t-1} +b_{f}) f(t)=σ(uf⋅xt+wf⋅ht−1+bf) \qquad (1) \qquad ( u f , w f , b f ) (u_{f},w_{f},b_{f}) (uf,wf,bf)
i ( t ) = σ ( u i ⋅ x t + w i ⋅ h t − 1 + b i ) i^{(t)}=\sigma(u_{i}\cdot x_t+w_{i}\cdot h_{t-1} +b_{i}) i(t)=σ(ui⋅xt+wi⋅ht−1+bi) \qquad (2) \qquad ( u i , w i , b i ) (u_{i},w_{i},b_{i}) (ui,wi,bi)
o ( t ) = σ ( u o ⋅ x t + w o ⋅ h t − 1 + b o ) o^{(t)}=\sigma(u_{o}\cdot x_t+w_{o}\cdot h_{t-1} +b_{o}) o(t)=σ(uo⋅xt+wo⋅ht−1+bo) \qquad (3) \qquad ( u o , w o , b o ) (u_{o},w_{o},b_{o}) (uo,wo,bo)
c ( t ) ‾ = t a n h ( u c ⋅ x t + w c ⋅ h t − 1 + b c ) \overline {c^{(t)}}=tanh(u_{c}\cdot x_t+w_{c}\cdot h_{t-1} +b_{c}) c(t)=tanh(uc⋅xt+wc⋅ht−1+bc) \qquad (4) \qquad ( u c , w c , b c ) (u_{c},w_{c},b_{c}) (uc,wc,bc)
c ( t ) = f ( t ) ⊙ c ( t − 1 ) + i ( t ) ⊙ c ( t ) ‾ c^{(t)}=f^{(t)}\odot c^{(t-1)}+i^{(t)}\odot\overline {c^{(t)}} c(t)=f(t)⊙c(t−1)+i(t)⊙c(t) \qquad (5)
h ( t ) = o ( t ) ⊙ t a n h ( c ( t ) ) h^{(t)}=o^{(t)}\odot tanh(c^{(t)}) h(t)=o(t)⊙tanh(c(t)) \qquad (6)
从式(5)中可以看出 f ( t ) f^{(t)} f(t)是用来决定上一层获取的信息量 f ( t ) f^{(t)} f(t)=1就是指全部获取 f ( t ) f^{(t)} f(t)=0就是指遗忘上一层所有信息。 c ( t ) ‾ \overline {c^{(t)}} c(t)表示获取额外信息量, i ( t ) i^{(t)} i(t)表示决定获取 c ( t ) ‾ \overline {c^{(t)}} c(t)的大小
可以看出 h ( t ) h^{(t)} h(t)计算时有选择性的记忆上次信息和获取当前信息。
GRU
u ( t ) = σ ( u u ⋅ x t + w u ⋅ h t − 1 + b u ) u^{(t)}=\sigma(u_{u}\cdot x_t+w_{u}\cdot h_{t-1} +b_{u}) u(t)=σ(uu⋅xt+wu⋅ht−1+bu) \qquad (1) \qquad ( u u , w u , b u ) (u_{u},w_{u},b_{u}) (uu,wu,bu)
r ( t ) = σ ( u r ⋅ x t + w r ⋅ h t − 1 + b r ) r^{(t)}=\sigma(u_{r}\cdot x_t+w_{r}\cdot h_{t-1} +b_{r}) r(t)=σ(ur⋅xt+wr⋅ht−1+br) \qquad (2) \qquad ( u r , w r , b r ) (u_{r},w_{r},b_{r}) (ur,wr,br)
h ( t ) ‾ = t a n h ( w h ⋅ ( u h ⋅ x t + r ( t ) ⋅ h t − 1 + b h ) ) \overline {h^{(t)}}=tanh(w_{h}\cdot(u_{h}\cdot x_t+r^{(t)}\cdot h_{t-1} +b_{h})) h(t)=tanh(wh⋅(uh⋅xt+r(t)⋅ht−1+bh)) \qquad (3) \qquad ( u h , w h , b h ) (u_{h},w_{h},b_{h}) (uh,wh,bh)
h ( t ) = ( 1 − u ( t ) ) ⋅ h ( t − 1 ) + u ( t ) ⋅ h ( t ) ‾ h^{(t)}=(1-u^{(t)})\cdot h^{(t-1)}+u^{(t)}\cdot\overline {h^{(t)}} h(t)=(1−u(t))⋅h(t−1)+u(t)⋅h(t) \qquad (4)
从(4)中我们可以看到 h ( t − 1 ) h^{(t-1)} h(t−1)表示旧的信息, h ( t ) ‾ \overline {h^{(t)}} h(t)表示新的信息,而 u ( t ) u^{(t)} u(t)是做的加权平均的操作,也就是有百分之多少记忆旧的信息,有百分之多少获取新的信息。参数和运算要比LSTM少很多,速度也相对快一些
结束
好了神经网络的知识就介绍到这里,博主肝了两天,码字不易,还请各位转载标明出处,当然有什么不懂的或者是我错误的地方,及时留言哦,欢迎大家交流!!