Spark(Python)学习(一)
大数据关键技术
(1)分布式存储
分布式文件系统:GFS(Google File System)\HDFS(Hadoop Distributed File System)
Big Table \Hbase
NoSQL
NewSQL
(2)分布式处理
MapReduce
Spark
Flink
参考资料:
HDFS 与 GFS 的设计差异
GFS、MapReduce和BigTable:Google的三种大数据处理系统
NoSQL 还是 SQL ?这一篇讲清楚
HBase基本概念与基本使用
SQL,NoSQL和NewSQL的区别
map/reduce
与 Hadoop 对比,如何看待 Spark 技术?
带你入门Spark(资源整理)
深入理解Apache Flink核心技术
大数据计算模式
典型的计算模式:
(1)批处理计算
批处理是海量数据一起涌入,之后成批次的进行计算。
代表产品:MapReduce、Spark
(2)流计算
流计算是数据源源不断的到达,流数据需要实时处理,给出实时响应。
代表产品:S4、Storm、Flume、Streams、Puma、DStream、Super、Mario、银河流数据处理平台
(3)图计算
应用于适用图结构进行建模的场景(例如地理信息系统,社交网络数据)。
代表软件:Google Pregel、GraphX、Giraph、PowerGraph、Hama、GoldenOrb
(4)查询分析计算
针对大规模数据的存储管理和查询分析,常见于企业场景。
代表产品:Google Dremel,Hive,Cassandra,Impala
代表性大数据技术
Hadoop
Hadoop并不是一个单一的产品,而是一整个生态系统

HDFS——支持海量数据的分布式存储。
YARN——提供资源调度和管理服务(CPU和内存资源)。
MapReduce ——数据的计算(和HDFS并称Hadoop的两大核心)。
Hive——用于存储数据进行分析,但是本身并不保存数据,数据被保存于HDFS中。本质上就是一个编程接口,Hive将SQL语句自动转换对HDFS的查询分析,得到结果。
Pig——和Hive组合使用, 用于数据的清洗、转换。
Mahout——MapReduce上的数据挖掘和机器学习的算法库,分类、聚类、回归等。
Ambari——自动安装部署配置,应用于大规模安装。
Zookeeper——提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
HBase——一主多从架构,可应用于实时性计算场景。
Flume——日志的采集分析。
Sqoop——完成Hadoop系统组件之间的互通,ETL(Extract-Transform-Load),抽取(extract)、转换(transform)、加载(load)。应用于需要从关系数据库中导入大量数据到HDFS中,和从HDFS导出大量数据到关系型数据库时数据处理的场景
- MapReduce
它的特点是屏蔽了底层分布式并行编程细节,即写MapReduce程序时和写单机程序差别不大。
可以自动进行任务的分发和结果回收。
核心策略:“分而治之”:
将大任务拆分成很多子任务,并把子任务分发到不同的机器上并行执行。(并非所有任务都可以“分而治之”)

- YARN
资源管理框架(Yet Another Resource Negotiator,另一种资源协调者),Hadoop2.0后出现,实现“一个集群多个框架”。
如果一个企业布置了MapReduce、Storn、Impala等多个框架,此时可能出现内存和CPU争抢的情况,为应对该情况出现了YARN。
目前很多基本框架都部署在了YARN上,接受YARN调度。
Spark
Spark也是一个非常完备的生态系统,包含很多组件

Spark Core——完成RDD应用开发,满足企业批处理的需求。
Spark SQL——分析关系数据,满足企业查询分析计算。
Spark Streaming——进行流计算,Spark2.0以上版本出现新的组件 Structured Streaming。
MLlib——机器学习算法库
GraphX——编写图计算应用程序
Hadoop VS Spark
hadoop的缺点主要就是MapReduce的缺点

- 表达能力有限: MapReduce将不论多复杂的应用都高度抽象成两个函数,Map函数(映射)和Reduce函数(规约)。这虽然简化了应用开发,但是却限制了该框架的表达能力。
- 磁盘IO开销大: 当进行迭代计算和查询操作时,需要大量的读写磁盘。
- 延迟高: 除大量读写造成延迟外,还有衔接开销(当有一个Map任务没做完时,所有的Reduce都需要等待)。因此难以胜任多阶段、复杂的计算任务。
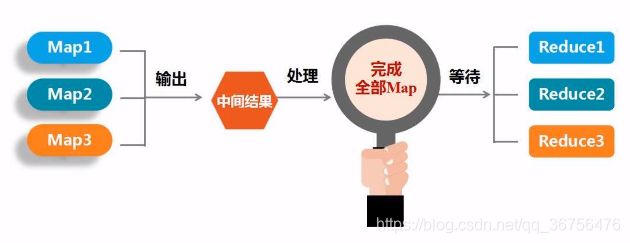
Spark的改进 - 操作更加丰富: Spark本质也是MapReduce,但是操作不局限于Map和Reduce,操作类型更多,表达能力更强。
- 运行效率提升: 使用内存计算,将结果放入内存中,高效提高迭代运算和查询操作(并非完全在内存上运行,而是在可以的情况下尽量不使用磁盘)。
- DAG任务调度执行机制: (DAG——有向无环图),该机制可对很多操作进行流水线处理,加快执行速度。

Spark会取代Hadoop吗?
Spark和Hadoop并不是对等的关系。Spark对应的是MapReduce,是一个单纯的计算框架,并不具备存储能力。所以Spark取代的是Hadoop中的计算框架MapReduce。

Flink和Beam
-
Flink
Flink是和Spark同一类型的计算框架,也是一个完整的生态系统。
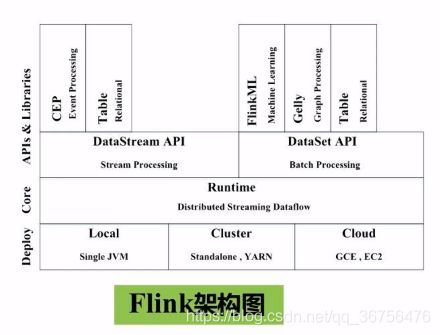
对比Spark和Flink
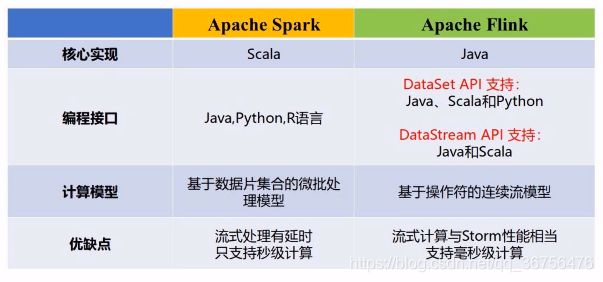
Scala语言较Java效率更高;
Spark基于的批处理模型较Flink的流处理模型,实时性更好;
但是在流计算方面Flink稍好于Spark。
由于Spark的社区好和企业支持早,Spark比Flink更加流行于市场中。 -
Beam
Beam由Google推出,为解决使用Hadoop、Spark、Flink等应用时需要学习不同的编程方法的问题,Beam提供了统一的编程接口,即是一个统一API。
但是并没有在市场上掀起太大的波澜。
Spark的设计与运行原理
概述
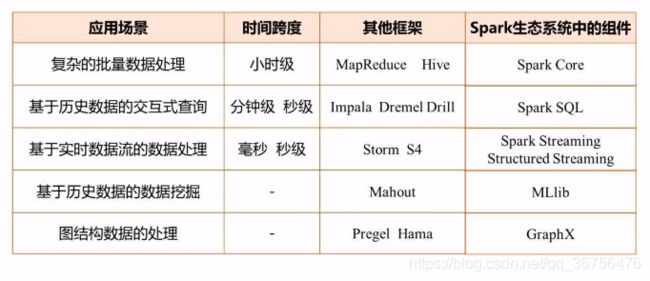
典型应用场景

在Spark前,企业需要使用不同的技术来满足这三个不同的应用场景。带来了“无法无缝共享,使用成本较高,资源利用不充分”这三个问题。
Spark有相应的组件满足不同的应用场景需求,并使用YARN进行统一的资源调度,满足企业的一站式需求。
Spark是BDAS(Berkeley Data Analytics Stack)的重要组成部分。BDAS是一个参考的基础框架,用于指导企业来构建企业的大数据分析系统。

Mesos和Hadoop YARN选其一;
由于Tachyon是基于内存的分布式文件系统,所以速度较HDFS快;
通常说的Spark并非Spark生态系统,而是Spark Core(用于满足批处理的组件)。
基本概念和架构设计
基本概念
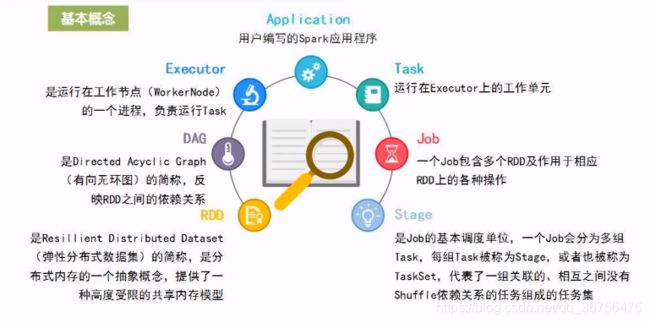
- RDD:
弹性分布式数据集,分布式内存的抽象概念,提供了一种高度受限的共享内存模型。是Spark最核心的数据抽象。
弹性指两点:
1.当数据较少时,可放在一台机器上存储;当数据较多时,则分布式存储在多台机器的内存上。
2.分区数目可变化,可以在计算的过程中动态的变化分区数量。 - Exector:
运行在工作节点的一个进程,负责运行Task。整个Spark运行起来时,集群里有一个主节点,还有很多从节点(工作节点),从节点用于执行具体的相关任务,每个从节点上都会运行一个Executor的进程,一个Executor进程会派生出许多线程,每个线程再去执行具体的相关任务。
运行架构

-
这是“一主多从”架构
在分布式系统中,常用的两种典型架构:
1.对等架构(p2p架构)
2.主从架构(一主多从) -
Cluster Manager 用于集群资源的调度管理,可以使用Spark自带的集群资源管理器,也可以用Hadoop中的YARN,或Mesos。

-
工作流程:
应用运行在主节点,应用生成若干个作业,每个作业执行时被切分成相关的阶段,每个阶段是任务的集合。
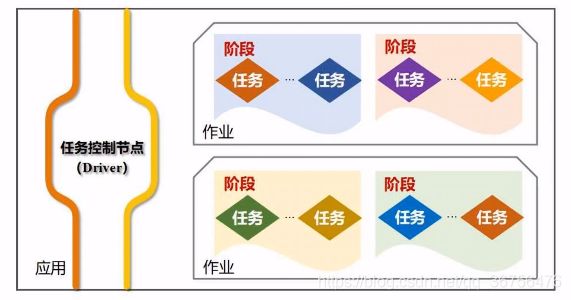

运行基本流程
首先需要对Application,创建基本的运行环境,找到Drive节点(主节点,担任指挥所角色)生成一个SparkContext对象(担任指挥官角色)担任指挥的工作,负责整个任务的调度、监控、执行、失败、恢复、结果汇总。
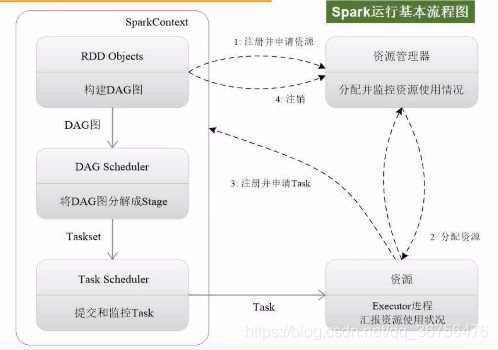
SparkContent需要申请资源,进行任务的分配和监控

Cluster Manager接到申请后,为Executor分配资源。启动之后可以派生出许多线程来执行任务。
任务的来源:SparkContent会根据提交的代码生成DAG图,再将DAG图交给DAG Scheduler进行解析,解析成很多阶段,每个阶段都包含很多任务。

任务的分发的工作由Task Scheduler完成,任务的分配保持基本原则“计算向数据靠拢”,尽量减少数据的移动开销,优先把计算分发到数据所在节点。
执行完任务后,就将结果反馈给Task Scheduler,再反馈给DAG Scheduler,最终写入数据,释放资源。

RDD运行原理
机器学习、图计算和交互式挖掘都包含大量的迭代计算,这些迭代计算的公共特点就是,不同的计算之间会涉及中间结果的存入问题,MapReduce在此操作上有大量的磁盘IO开销以及序列化和反序列化开销。(序列化指,例如内存中的Java对象转化成适合存储和传输的格式(如二进制或字符串格式);反序列化就是将可保存和传输格式的数据还原成对象)
RDD提供了抽象的数据结构,使得不用担心底层的分布式特性,而只需要把具体的应用逻辑去表达为一系列转换处理,不同的RDD转换形成一个依赖关系,DAG图。

针对DAG图可以依据优化原理,对数据进行优化,实现数据的管道化处理,即数据一个操作结束后不需要落磁盘,可以直接传给另一个操作作为输入。
RDD是分布式对象的集合,本质上是一个只读的分区记录集合。
一个RDD可以保存大量数据,分布式的保存,分成若干分区保存在多台机器上,每个分区就是一个数据片段,分布在不同节点上。从而使得计算可以分布式进行,效率提高。
RDD提供了一种高度受限的共享内存模型(只读),只有在转换的过程中,通过生成新的RDD来完成一个数据修改的目的。
RDD类型操作
(1)动作类型操作(Action)
(2)转换类型操作(Transformation)
这两种操作都是粗粒度的转换操作,粗粒度指操作时必须一次性全部将RDD中的数据进行转换,不支持单条数据进行修改。

针对细粒度操作,例如网页爬虫,就不适合Spark编程。
高度受限的共享内存模型会不会影响表达能力?
RDD提供了非常多的操作,可以将操作进行组合使用。达到了凡是其他基本框架可以实现的操作,RDD都可以实现,还可以实现很多其他框架不能实现的操作。完全可以满足企业应用场景中各种各样的需求。
通过Spark提供RDD的API,程序员可以调用API来实现对RDD的各种操作,来满足应用程序的开发需求。
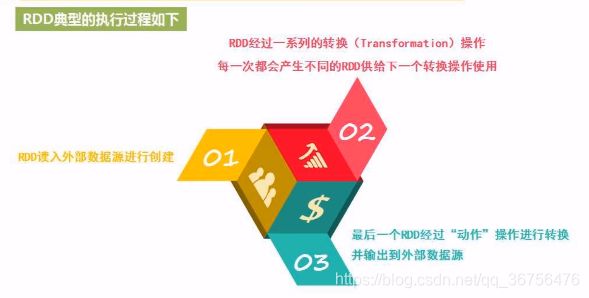
RDD典型的执行过程如下

惰性调用机制
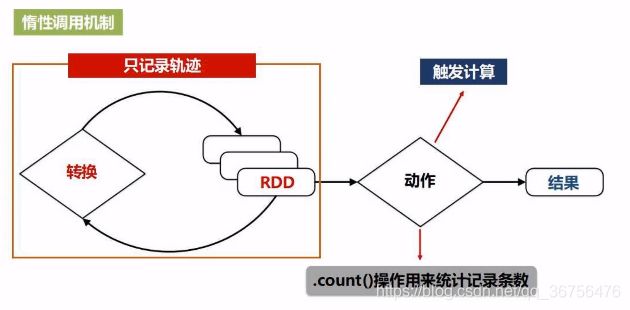
由于惰性调用机制,转换类型操作是不会计算得到结果。即之前对RDD执行的转换操作,并不真正执行转换,只是记录了转换的意图。只有遇到了第一个动作操作类型时,才会触发计算,执行从头到尾操作(从磁盘读取数据–>转化–>…–>动作–>输出),惰性调用机制是Spark的一个突出特点。
流水线优化
管道化处理,一个操作执行后,可以不将数据写入磁盘,直接作为下一操作的输入。避免了不必要的读写磁盘开销。因此不需要保存中间结果,避免不必要的序列化和反序列化。
Spark中的每一个操作的逻辑都非常简单,但是操作串联形成庞大的操作集合,可以完成非常复杂的功能。
Spark为什么可以实现高效计算
(1)高效的容错性
现有的容错机制主要是数据复制和记录日志,但是在分布式系统中,这两种方式开销都很大。
Spark具有天然的容错性,RDD操作是DAG图形式的,DAG图形成了Lineage血缘关系,即A是B的父亲,C是D的父亲,B和D是E的父亲,E是F的父亲。这样的血缘关系图可以用于恢复数据,例如F丢失,可以再从E生成,甚至全部都丢掉了,只需从磁盘中取数据再操作一遍即可。只要有了血缘关系图,Spark就有了天然的容错性。

(2)中间结果持久化内存
之前提到的数据在内存的多个RDD之间进行传递的操作,避免了不必要的读写磁盘开销。避免不必要的序列化和反序列化开销。
RDD之间的依赖关系
问:
(1)一个作业为什么要分多个阶段?
(2)以什么为依据拆分阶段?
窄依赖——不划分阶段
宽依赖——划分成多个阶段
- 宽依赖
是否包含**Shuffle操作(洗牌)**是区分宽依赖和窄依赖的依据。
下图的map和reduce操作就是Shuffle

窄依赖 表现为一个父RDD的分区对应一个子RDD的分区;或者多个父RDD的分区对应一个子RDD的分区。

宽依赖表现为一个父RDD的一个分区对应一个子RDD的多个分区。

为什么将宽依赖和窄依赖作为划分阶段的依据?
原因是窄依赖可以进行流水线优化,而宽依赖不能进行流水线优化。
为什么宽依赖不能进行流水线优化?
这里就涉及了Spark的优化原理fork/join机制,即并行执行任务的框架,是分布式系统做优化时的典型机制。
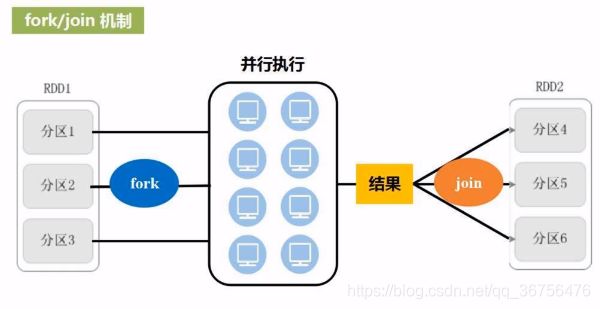
每一次RDD操作都是一次fork and join,多个RDD转换串联起来就是fork and join + fork and join + … + fork and join的组合。
那么如何优化这一系列的fork and join, 举例说明:
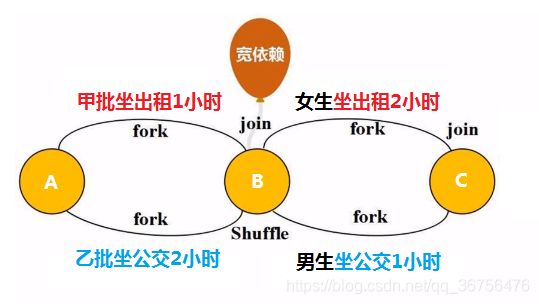
一群人要从A地经过B地到C地,这群人分为甲乙两批,甲批坐出租,乙批坐公交,由于B地到C限行,出租车速度降低。
甲乙两批人在B地会合,甲批人等待了1小时;在C地回合,乙批人等待了1小时,所以全部从A地到达C地用了4小时。

这其中涉及了两次fork and join,那么经过优化,去掉了无意义的等待,在B地join其实就相当于数据写磁盘,实际上没有必要让两批人在B地会合,只需要3个小时就可以从A地到C地。
这种不用在B地等待会合的就是窄依赖,表现了数据不落磁盘直接在内存中操作的优化过程。

但是宽依赖必须要在B地等待会合,即Shuffle操作必须写磁盘,举例说明:
甲乙两批人在B地会合后,换为所有人里全部女生坐出租车,全部男生坐公交车,这样甲乙两批人就不得不在B地会合。
这样就没有办法实现管道化的流水线操作,在B地发生洗牌,必须join写入磁盘。所以宽依赖一定要切分阶段。
如何切分阶段?
将DAG有向无环图作为算法输入,使用递归对DAG图进行解析,遇到窄依赖就不断加入阶段,形成管道化流水线处理;遇到宽依赖由于发生洗牌等待,就要断开生成新的阶段。

A–>B:
阶段一:宽依赖,即需要等分区1、2、3都完成到达分区4、5、6的操作,在B处汇合才可以进行下一步。
C–>D,D–>F:
阶段二:
窄依赖,即分区7到9再到13的操作,和分区8到10再到14的操作不需要在D处互相等待,可以直接完成。
B,F–>G:
阶段三:
宽依赖,shuffle操作。
总结RDD的整个运行过程
提交代码到Spark框架
–》生成DAG图
–》将DAG图提交给DAGScheduler
–》DAGScheduler将DAG图分解为很多阶段,每个阶段包含若干任务
–》每个任务分配给TaskScheduler
–》TaskScheduler 把任务分发给WorkerNode上的Excutor进程
–》由Excutor进程派发出线程去执行具体任务

Spark的部署和应用方式
Spark支持单机部署和集群部署。
集群部署有三种典型方式:
(1)Standalone:
使用Spark自带的集群资源管理器来管理整个CPU内存资源调度,效率不高。
(2)Mesos:
使用Mesos作为集群资源管理器,其性能最高。Mesos和Spark都诞生于加州大学伯克利分校的AMPLab,匹配度高,但是业界使用最多的并不是Mesos。
(3)YARN:
YARN是很多计算框架的通用调度框架,在业界使用度最高。