HDFS的工作原理
元数据管理机制
1、文件读取过程
1.客户端通过调用 DistributedFileSystem 的create方法,创建一个新的文件。
2.DistributedFileSystem通过RPC(远程过程调用)调用NameNode,去创建一个没有blocks关联的新文件。创建前,NameNode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,NameNode就会记录下新文件,否则就会抛出IO异常。
3.前两步结束后会返回FSDataOutputStream的对象,和读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream,DFSOutputStream 可以协调 NameNode和DataNode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列 data queue。
4.DataStreamer会去处理接受dataqueue,它先问询NameNode这个新的block最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的DataNode,把它们排成一个pipeline。DataStreamer把packet按队列输出到管道的第一个 DataNode 中,第一个 DataNode又把 packet 输出到第二个 DataNode 中,以此类推。
5.DFSOutputStream 还有一个队列叫ack ueue,也是由packet组成,等待DataNode的收到响应,当pipeline中的所有DataNode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
6.客户端完成写数据后,调用close方法关闭写入流。
7.DataStreamer 把剩余的包都刷到 pipeline 里,然后等待 ack 信息,收到最后一个 ack 后,通知 DataNode 把文件标示为已完成。
2、文件写入过程
1、首先调用FileSystem对象的open方法,其实获取的是一个DistributedFileSystem的实例。
2、DistributedFileSystem通过RPC(远程过程调用)获得文件的第一批block的locations,同一block按照重复数会返回多个locations,这些locations按照Hadoop拓扑结构排序,距离客户端近的排在前面。
3、前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream就会找出离客户端最近的datanode并连接datanode。
4、数据从datanode源源不断的流向客户端。
5、如果第一个block块的数据读完了,就会关闭指向第一个block块的datanode连接,接着读取下一个block块。这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流。
6、如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的block块都读完,这时就会关闭掉所有的流。
名词解释
1、NameNode
hdfs-site.xml的dfs.name.dir属性
是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/(根)目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
文件包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息
edits:操作日志文件
fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中。
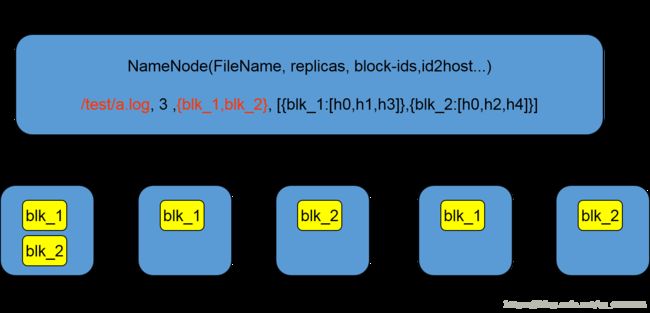
2、Bolck
文件块(block):最基本的存储单位。
对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。
HDFS默认Block大小是128MB,以一个256MB文件为例,共有256/128=2个Block。
dfs.block.size不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间Replication。
3、DataNode
hdfs-site.xml的dfs.replication属性
提供真实文件数据的存储服务。
一个DataNode上有多个bolck——多复本。默认是三个。
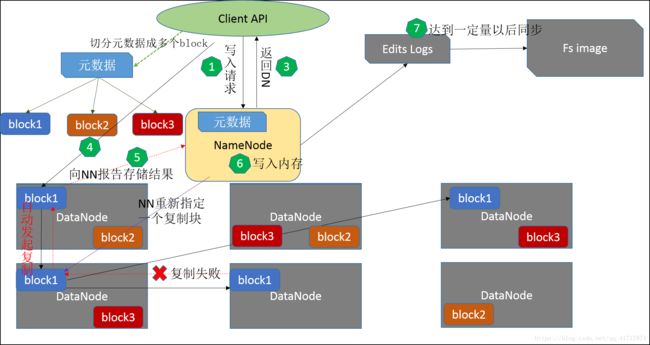
4、客户端上传元数据
1、客户端发起写入请求
2、NN返回可用的DN
3、客户端把元数据拆分成多个块
4、上传第一个块到某个DN1
5、DN1向DN2发起复制请求,DN2向DN3发起复制请求,如果失败,则由NN重新指定一个block向新的DN4发起复制请求
5、上传元数据信息安全机制
1、客户端发起写入请求
2、把操作写入到edits logs
3、客户端上传文件文件,并把结果反馈给NN,NN在内存中写入本次上传信息
4、当edits logs写满,则同步(flush)到 fs image文件系统中
5、读取的时候日志以特殊的方式跟fs image合并(所以不能在NN做合并)
6、元数据存储与读取细节
SN的checkpoint机制
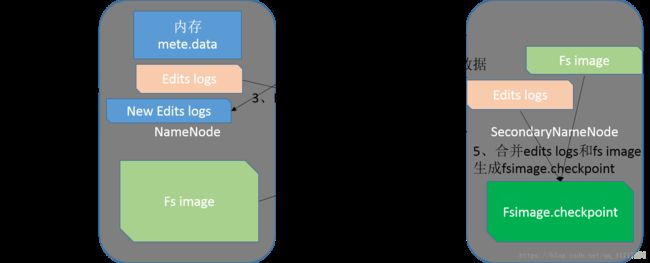
fs.checkpoint.period 指定两次checkpoint的最大时间间隔, 默认3600秒。
fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否到达最大时间间隔。默认大小是64M。
Namenode始终在内存中保存metedata,用于处理“读请求”,到有“写请求”到来时,namenode会首先写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回,Hadoop会维护一个fsimage文件,也就是namenode中metedata的镜像,但是fsimage不会随时与namenode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容。Secondary namenode就是用来合并fsimage和edits文件来更新NameNode的metedata的。
更多资深讲师相关课程资料、学习笔记请入群后向管理员免费获取,更有专业知识答疑解惑。入群即送价值499元在线课程一份。
QQ群号:560819979
敲门砖(验证信息):雨打蕉
发布于 17:30