学习爬虫相关的urllib,urllib3库(two day)
urllib是Python中请求url连接的官方标准库,在Python2中主要为urllib和urllib2,在Python3中整合成了urllib。
而urllib3则是增加了连接池等功能,两者互相都有补充的部分。
1.urllib库
urllib 是一个用来处理网络请求的python标准库,它包含4个模块。
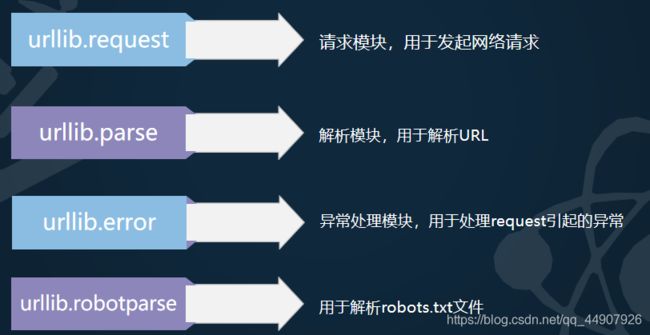
(1)urllib.request模块:
request模块主要负责构造和发起网络请求,并在其中添加Headers,Proxy等。
利用它可以模拟浏览器的请求发起过程。
1.发起网络请求。
2.添加Headers。
3.操作cookie。
4.使用代理。
使用代理解释:

1.urlopen方法
(小知识点:
测试网站:http://httpbin.org/get
我们向此网站发送请求的话,会拿到我们发送的请求的信息。)
源码:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
1.功能:urlopen是一个发送简单网络请求的方法,然后返回结果。
2.参数:
url:必选;可以是一个字符串或一个 Request 对象。
data:None–GET请求;有数据(字节类型/文件对象/可迭代对象)–POST请求(POST请求的话,data数据会放进form表单进行提交);
timeout:有默认设置;以秒为单位,例:设置timeout=0.1 超时时间为0.1秒(如果超出这个时间就报错!)
3.返回值:urlib库中的类或者方法,在发送网络请求后,都会返回一个urllib.response的对象。它包含了请求回来的数据结果。它包含了一些属性和方法,供我们处理返回的结果。
from urllib import request
test_url_get = "http://httpbin.org/get" #测试网站
response=request.urlopen(test_url_get,timeout=10,data=None) #有data即为post请求;无data(None)即为get请求
print("状态码:",response.getcode()) #获得状态码
print("响应头信息:",response.info()) #显示响应头信息
print("获取内容:",response.read()) #取出内容
# 需要注意:(如果你这样搞,服务端一眼就看出来你图谋不轨,不是正经的客户端了!)
# 如果是浏览器直接访问测试网站:"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
#如果是爬虫获取: "User-Agent": "Python-urllib/3.8"
# 一个小重点: read只能read一次,再read就获取不到信息咯
print("第二次:",response.read()) #输出:第二次: b''
# 获取百度首页
baidu_url = "http://www.baidu.com"
response_baidu = request.urlopen(baidu_url)
print("百度首页的内容:",response_baidu.read().decode())
2.Request方法
利用urlopen可以发起最基本的请求,但这几个简单的参数不足以构建一个完整的请求,可以利用更强大的Request方法来构建更加完整的请求。
1.功能:Request是一个构造完整网络请求的对象,然后返回请求对象。
2.参数:
url:必选;是一个字符串
data:字节类型
headers:请求头信息
method:默认GET,可填写 POST,PUT,DELETE等
3.返回值:一个请求对象
(1)实践——请求头添加:
通过urllib发送的请求会有一个默认的Headers: “User-Agent”:“Python-urllib/3.6”,指明请求是由urllib发送的。所以遇到一些验证User-Agent的网站时,需要我们自定义Headers把自己伪装起来。
from urllib import request
img_url = "https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=261409204,1345114629&fm=26&gp=0.jpg"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"}
req = request.Request(url=img_url,headers=headers) #构建Request对象 作用:向服务端发送请求时,User-Agent改变成了我们定义的这个,简单伪装!
# response = request.urlopen(url=img_url) #普通方法
response = request.urlopen(req) #添加了Hearders的高级一点的方法
data = response.read()
with open("cat.jpg","wb") as f:
f.write(data)
# 我们可以来查看一下我们是否真正改变了请求头信息
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"}
test_url = "http://httpbin.org/get"
req = request.Request(url=test_url,headers=headers)
res_test = request.urlopen(req)
print(res_test.read()) #在直接使用urlopen时:"User-Agent": "Python-urllib/3.8"
#但是我们现在使用了Request伪装,现在就是我们所设置的

(2)urllib.parse模块:
parse模块是一个工具模块,提供了需要对url处理的方法,用于解析url。
1.parse.quote() 和 parse.unquote()
功能:url中只能包含ascii字符,在实际操作过程中,get请求通过url传递的参数中会有大量的特殊字符,例如汉字,那么就需要进行url编码。
利用parse.unquote()可以反编码回来。
from urllib import parse,request
# 实际使用
name = "美女"
code = parse.quote(name)
test_url = "http://httpbin.org/get?name={}".format(code) #url里只支持ascii码
res=request.urlopen(test_url)
print(res.read())
# 单个示范
print(parse.quote("美女")) #转为ascii
print(parse.unquote("%E7%BE%8E%E5%A5%B3")) #转为utf-8格式
print("*"*50)

2.parse.urlencode() 和 parse.parse_qs()
在发送请求的时候,往往会需要传递很多的参数,如果用字符串方法去拼接会比较麻烦,parse.urlencode()方法就是用来拼接url参数的。(将字典格式转换成url请求参数)
也可以通过parse.parse_qs()方法将它转回字典
# 单个示范
params = parse.urlencode({"name":"美女","name2":"帅哥","name3":"姐姐"}) #字典格式转换为url请求参数
print(params)
print("转换回来:",parse.parse_qs(params)) #url请求参数转换为字典格式
# 实际使用
test_url2 = "http://httpbin.org/get?{}".format(params)
res2 = request.urlopen(test_url2)
print(res2.read())

(3)urllib.error模块:
error模块主要负责处理异常,如果请求出现错误,我们可以用error模块进行处理
主要包含URLError和HTTPError
1.URLError:是error异常模块的基类,由request模块产生的异常都可以用这个类来处理
2.HTTPError:是URLError的子类,主要包含三个属性:
(1)Code:请求的状态码
(2)reason:错误的原因
(3)headers:响应的报头
from urllib import error,request
try:
res=request.urlopen("https://jianshu.com")
print(res.read())
except error.HTTPError as e:
print(e.code)
print(e.reason)
print(e.headers)

(4)urllib.robotparse模块
robotparse模块主要负责处理爬虫协议文件,robots.txt.的解析。(君子协定)
比如:百度的robots协议:
http://www.baidu.com/robots.txt即可查看。
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器,比如Windows系统自带的Notepad,就可以创建和编辑它 。robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。
2.urllib3库
urllib3 是一个基于python3的功能强大,友好的http客户端。越来越多的python应用开始采用urllib3.它提供了很多python标准库里没有的重要功能(线程安全,连接池)。
(1)request方法
源码:
request(self, method, url, fields=None, headers=None,**urlopen_kw)
1.功能:发送完整的网络请求
2.参数:
method:请求方法 GET ,POST…
url:字符串格式
fields:字典类型 GET请求时转化为url参数;POST请求时会转化成form表单数据
headers:字典类型
3.返回值:response对象
import urllib3
import json
http=urllib3.PoolManager() #实例化一个连接池对象 保持socket开启
test_url = "http://httpbin.org/get"
# 添加头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"}
#参数fileds使用:如果是get就将fields这个字典转换为url参数;如果是post就将fields这个字典转换为form表单数据。
data_dict={"name1":"allen","name2":"rose"}
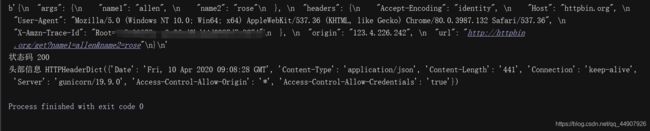
res = http.request("GET",test_url,headers=headers,fields=data_dict) #功能:发送完整的网络请求
print(res.data) #获取内容
print("状态码",res.status) #状态码
print("头部信息",res.headers) #响应头信息
 如果是POST请求,会将fields对应的字典转换为form表单数据:
如果是POST请求,会将fields对应的字典转换为form表单数据:

小拓展:使用json模块的loads方法获取特定信息
在上述代码加入:
data = res.data.decode() #将字节数据转换为utf-8格式
print(json.loads(data)["args"]["name1"]) #json.loads()将json数据转换为字典,这样可以进行特定信息的获取
#输出为:allen
实践:爬虫一般开发流程!
