BloomFilter在DataDomain中的应用
DataDomain中的重复数据检查
DataDomain(DD)采用数据块级的去重技术,文件或数据流被切割为较小的segment, 然后使用160-bit的SHA1算法求取每个segment的哈希值,这些哈希值被称为segmentfingerprint, 用来标志一个segment。具有相同fingerprint的两个segment即为duplicatesegment。当有数据写入的时候,DD会首先把数据切成很多小的segment,然后计算出fingerprint,再与系统上现有的fingerprint进行比较,来判断这个数据块是否是重复数据。
为了保证DD的写性能,我们希望花在重复数据判断的时间尽可能的少。
最直接的方式是在内存中维护所有的fingerprint。fingerprint的比较直接在内存中完成,性能最优。但是采用这种方式会带来巨大的内存开销。假设现有一台DD上有8TB去重后的数据,以平均一个segment大小8KB来计算,那么系统上一共存在10亿个这样的fingerprint。每个fingerprint20byte, 我们需要20GB的内存只是来存储所有的fingerprint!显然这种方式是不能接受的。
既然内存不够维护所有的fingerprint,那么通常的做法就是缓存一部分fingerprint在内存,当有新的fingerprint需要比较的时候,先检查缓存,如果缓存没有再检查磁盘上的。DD也是这样做的,其使用一种叫做LocalityPreserved Caching(LPC)的缓存技术来加速重复数据判断,该技术利用了备份数据的一个特性:对同一个文件进行多次备份,其segment出现的序列是相同的。假设有一个1MB的文件被切成了100多个小的数据块,在每次对这个文件进行备份的时候,这些segment总是以相同的顺序出现的。即使某次文件的内容中有了一些修改,会有新的segment产生,但是剩下的segment也会以同样的顺序出现。利用这个特性,当DD发现一个写入的segment和DD上的segmentx重复的时候,会尽量把与x来自同一个文件的后续fingerprint放到缓存中,以提高后面的缓存命中率。
但是只有缓存还不够,缓存的作用只有当写入重复数据时,减少diskI/O。当写入新的segment时,在缓存中找不到相应的fingerprint,还是要去disk上找, 带来性能瓶颈。那么DD是怎么解决这个问题的呢?
Bloom Filter 介绍
在揭晓答案之前,要先介绍下 本文的重点:BloomFilter。 Bloom Filter的中文翻译叫做布隆过滤器,是1970年由布隆提出的。其特点总结为如下:
1. 空间效率高的概率型数据结构,用来检查一个元素是否在一个集合中
2. 对于一个元素检测是否存在的调用,Bloom Filter会告诉调用者两个结果之一:可能存在或者一定不存在
它实际上是一个很长的二进制向量和一系列随机映射函数。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
初始状态下,BloomFilter是一个m位的位数组,且数组被0所填充。同时,我们需要定义k个不同的hash函数,每一个hash函数都随机的将每一个输入元素映射到位数组中的一个位上。那么对于一个确定的输入,我们会得到k个索引。
插入元素:经过k个hash函数的映射,我们会得到k个索引,我们把位数组中这k个位置全部置1(不管其中的位之前是0还是1)
查询元素:输入元素经过k个hash函数的映射会得到k个索引,如果位数组中这k个索引不全是1,那么就说明这个元素一定不在集合之中;但如果这k个索引处的位都是1,被查询的元素就一定在集合之中吗?答案是不一定,也就是说出现了FalsePositive的情况(但BloomFilter不会出现FalseNegative的情况)
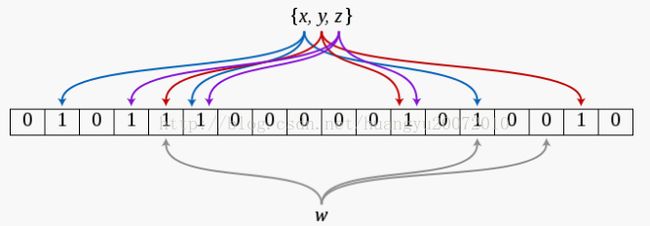
在上图中,当插入x、y、z这三个元素之后,再来查询w,会发现w不在集合之中,而如果w经过三个hash函数计算得出的结果所得索引处的位全是1,那么BloomFilter就会告诉你,w可能在集合之中,实际上这里是误报,w并不在集合之中。
Bloom Filter的误报率到底有多大?
下面在数学上进行一番推敲。假设HASH函数输出的索引值落在m位的数组上的每一位上都是等可能的。那么,对于一个给定的HASH函数,在进行某一个运算的时候,一个特定的位没有被设置为1的概率是![]()
那么,对于所有的k个HASH函数,都没有把这个位设置为1的概率是
如果我们已经插入了n个元素,那么对于一个给定的位,这个位仍然是0的概率是
那么,如果插入n个元素之后,这个位是1的概率是
如果对一个特定的元素存在误报,那么这个元素的经过HASH函数所得到的k个索引全部都是1,概率也就是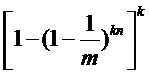
根据常数e的定义,可以近似的表示为:
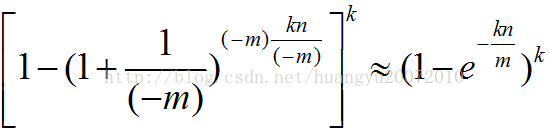
利用上面这个公式,我们可以得到当m/n为一个常数时,Hash函数个数k与误报率的对应关系。下图就是一个当m/n=8时的例子。可以看到此时,最佳的误差率仅在2%左右。
Bloom Filter在DD中的应用
好了,现在我们对BloomFilter已经有了了解,想必大家也一定想到了,可以使用BloomFilter来表示DD上已有fingerprint的集合,从而可以快速判断出待写入的segment哪些一定是新的segment,哪些可能是重复的segment。把新的segment过滤掉,DD只需要继续检查那些可能重复的segment,从而达到减少diskI/O的目的。
DD将这个BloomFilter称为SummaryVector。和典型的BloomFilter一样,SummaryVector也由一个很长的位向量组成,这个位向量被初始化为全0。当有新的fingerprint需要加入的时候,会将该fingerprint传入不同的HASH函数,计算出几个HASH值,再映射到位向量上将对应的位设为1.
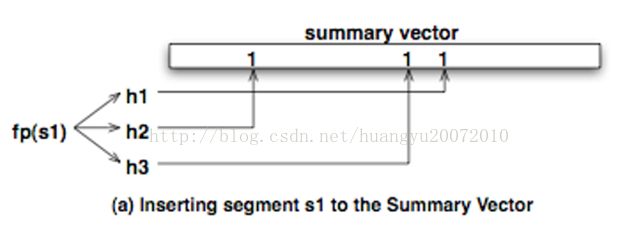
当需要查询该fingerprint是否在DD上时,同样将通过fingerprint计算出的HASH值,映射到位向量上,如果对应的位置有一个不为1,则可以判断出该fingerprint一定不在DD上。

使用SummaryVector在存在一定误判的基础上大大降低了判断重复数据时对内存的要求,以m/n=8为例,对于8TB的非重复数据,SummaryVector只需要1GB的容量就可以把绝大多数(2%的误差率)的新segment过滤掉!
下面这张图描述了DD进行重复数据判断时的流程,我们可以看到DD分别通过cache和SummaryVector来过滤掉不必要的segmentindex lookup的操作。cache会首先过滤掉很大一部分重复的segment,接下来SummaryVector又会把绝大多数新的segment过滤掉,从而实际需要到disk上进行segmentindex lookup的请求很少,保证了重复数据判断的高性能。

总结
本文介绍了BloomFilter以及其在DataDomain中的应用。而除了去重数据备份系统,其还被用于很多需要海量数据查询的场景,在很多互联网应用中都有BloomFilter的身影,比如下面这些:
1. Google BigTable, Apache HBase Apache Cassandra, 和 Postgresql使用Bloom Filter减少对不存在的行列的磁盘查询,提高数据库查询操作性能。
2. Google Chrome 使用Bloom Filter来判断恶意URLs。任何URL都会先经过浏览器本地的BloomFilter作检查,只有当Bloom Filter返回positive的时候,才会将URL发到Google服务器上作完整的检查。
3. Bitcoin 使用Bloom Filter加速钱包的同步
总之,当我们需要快速判断一个元素是否在一个集合中,而内存又是一个问题的时候,都可以尝试Bloom Filter。