JVM(二)
Java内存模型
1.Java 内存模型通过定义了一系列的 happens-before 操作,让应用程序开发者能够轻易地表达不同线程的操作之间的内存可见性。
2.在遵守 Java 内存模型的前提下,即时编译器以及底层体系架构能够调整内存访问操作,以达到性能优化的效果。如果开发者没有正确地利用 happens-before 规则,那么将可能导致数据竞争。
3.Java 内存模型是通过内存屏障来禁止重排序的。对于即时编译器来说,内存屏障将限制它所能做的重排序优化。对于处理器来说,内存屏障会导致缓存的刷新操作。
happens-before 关系
- 解锁操作 happens-before 之后(这里指时钟顺序先后)对同一把锁的加锁操作。
- volatile 字段的写操作 happens-before 之后(这里指时钟顺序先后)对同一字段的读操作。
- 线程的启动操作(即 Thread.starts()) happens-before 该线程的第一个操作。
- 线程的最后一个操作 happens-before 它的终止事件(即其他线程通过 Thread.isAlive() 或 Thread.join() 判断该线程是否中止)。
- 线程对其他线程的中断操作 happens-before 被中断线程所收到的中断事件(即被中断线程的 InterruptedException 异常,或者-第三个线程针对被中断线程的 Thread.interrupted 或者 Thread.isInterrupted 调用)。
- 构造器中的最后一个操作 happens-before 析构器的第一个操作。
- happens-before 关系还具备传递性。如果操作 X happens-before 操作 Y,而操作 Y happens-before 操作 Z,那么操作 X happens-before 操作 Z。
锁,volatile 字段,final 字段与安全发布
锁操作同样具备 happens-before 关系。具体来说,解锁操作 happens-before 之后对同一把锁的加锁操作。实际上,在解锁时,Java 虚拟机同样需要强制刷新缓存,使得当前线程所修改的内存对其他线程可见。
需要注意的是,锁操作的 happens-before 规则的关键字是同一把锁。也就意味着,如果编译器能够(通过逃逸分析)证明某把锁仅被同一线程持有,那么它可以移除相应的加锁解锁操作。
因此也就不再强制刷新缓存。举个例子,即时编译后的 synchronized (new Object()) {},可能等同于空操作,而不会强制刷新缓存。
volatile 字段可以看成一种轻量级的、不保证原子性的同步,其性能往往优于(至少不亚于)锁操作。然而,频繁地访问 volatile 字段也会因为不断地强制刷新缓存而严重影响程序的性能。
在 X86_64 平台上,只有 volatile 字段的写操作会强制刷新缓存。因此,理想情况下对 volatile 字段的使用应当多读少写,并且应当只有一个线程进行写操作。
volatile 字段的另一个特性是即时编译器无法将其分配到寄存器里。换句话说,volatile 字段的每次访问均需要直接从内存中读写。
final 实例字段则涉及新建对象的发布问题。当一个对象包含 final 实例字段时,我们希望其他线程只能看到已初始化的 final 实例字段。
因此,即时编译器会在 final 字段的写操作后插入一个写写屏障,以防某些优化将新建对象的发布(即将实例对象写入一个共享引用中)重排序至 final 字段的写操作之前。在 X86_64 平台上,写写屏障是空操作。
新建对象的安全发布(safe publication)问题不仅仅包括 final 实例字段的可见性,还包括其他实例字段的可见性。
当发布一个已初始化的对象时,我们希望所有已初始化的实例字段对其他线程可见。否则,其他线程可能见到一个仅部分初始化的新建对象,从而造成程序错误。
Java虚拟机是怎么实现synchronized的?
对象头中的标记字段(mark word)。它的最后两位便被用来表示该对象的锁状态。其中,00 代表轻量级锁,01 代表无锁(或偏向锁),10 代表重量级锁,11 则跟垃圾回收算法的标记有关。
Java 虚拟机中 synchronized 关键字的实现,按照代价由高至低可分为重量级锁、轻量级锁和偏向锁三种:
1.重量级锁会阻塞、唤醒请求加锁的线程。它针对的是多个线程同时竞争同一把锁的情况。Java 虚拟机采取了自适应自旋,来避免线程在面对非常小的 synchronized 代码块时,仍会被阻塞、唤醒的情况。
2.轻量级锁采用 CAS 操作,将锁对象的标记字段替换为一个指针,指向当前线程栈上的一块空间,存储着锁对象原本的标记字段。它针对的是多个线程在不同时间段申请同一把锁的情况。
多个线程在不同的时间段请求同一把锁,也就是说没有锁竞争。针对这种情形,Java 虚拟机采用了轻量级锁,来避免重量级锁的阻塞以及唤醒。
3.偏向锁只会在第一次请求时采用 CAS 操作,在锁对象的标记字段中记录下当前线程的地址。在之后的运行过程中,持有该偏向锁的线程的加锁操作将直接返回。它针对的是锁仅会被同一线程持有的情况。
即时编译
1.从 Java 8 开始,Java 虚拟机默认采用分层编译的方式。它将执行分为五个层次,分为为 0 层解释执行,1 层执行没有 profiling 的 C1 代码,2 层执行部分 profiling 的 C1 代码,3 层执行全部 profiling 的 C1 代码,和 4 层执行 C2 代码。
通常情况下,C2 代码的执行效率要比 C1 代码的高出 30% 以上。然而,对于 C1 代码的三种状态,按执行效率从高至低则是 1 层 > 2 层 > 3 层。
2.通常情况下,方法会首先被解释执行,然后被 3 层的 C1 编译,最后被 4 层的 C2 编译。

3.即时编译是由方法调用计数器和循环回边计数器触发的。在使用分层编译的情况下,触发编译的阈值是根据当前待编译的方法数目动态调整的。
4.OSR 是一种能够在非方法入口处进行解释执行和编译后代码之间切换的技术。OSR 编译可以用来解决单次调用方法包含热循环的性能优化问题。
5.通常情况下,解释执行过程中仅收集方法的调用次数以及循环回边的执行次数。
6.当方法被 3 层 C1 所编译时,生成的 C1 代码将收集条件跳转指令的分支 profile,以及类型相关指令的类型 profile。在部分极端情况下,Java 虚拟机也会在解释执行过程中收集这些 profile。
分层编译中的 0 层、2 层和 3 层都会进行 profiling,收集能够反映程序执行状态的数据。其中,最为基础的便是方法的调用次数以及循环回边的执行次数。它们被用于触发即时编译。
此外,0 层和 3 层还会收集用于 4 层 C2 编译的数据,比如说分支跳转字节码的分支 profile(branch profile),包括跳转次数和不跳转次数,以及非私有实例方法调用指令、强制类型转换 checkcast 指令、类型测试 instanceof 指令,和引用类型的数组存储 aastore 指令的类型 profile(receiver type profile)。
7.基于分支 profile 的优化以及基于类型 profile 的优化都将对程序今后的执行作出假设。这些假设将精简所要编译的代码的控制流以及数据流。在假设失败的情况下,Java 虚拟机将采取去优化,退回至解释执行并重新收集相关的 profile。
Java字节码(基础篇)
1.Java 方法的栈桢分为操作数栈和局部变量区。通常来说,程序需要将变量从局部变量区加载至操作数栈中,进行一番运算之后再存储回局部变量区中。
2.Java 字节码可以划分为很多种类型,如加载常量指令,操作数栈专用指令,局部变量区访问指令,Java 相关指令,方法调用指令,数组相关指令,控制流指令,以及计算相关指令。
常数加载指令表

Java 相关指令,包括各类具备高层语义的字节码,即 new(后跟目标类,生成该类的未初始化的对象),instanceof(后跟目标类,判断栈顶元素是否为目标类 / 接口的实例。是则压入 1,否则压入 0),checkcast(后跟目标类,判断栈顶元素是否为目标类 / 接口的实例。如果不是便抛出异常),athrow(将栈顶异常抛出),以及 monitorenter(为栈顶对象加锁)和 monitorexit(为栈顶对象解锁)。
方法调用指令,包括 invokestatic,invokespecial,invokevirtual,invokeinterface 以及 invokedynamic。
数组相关指令,包括新建基本类型数组的 newarray,新建引用类型数组的 anewarray,生成多维数组的 multianewarray,以及求数组长度的 arraylength。另外,它还包括数组的加载指令以及存储指令。这些指令是区分类型的。例如,int 数组的加载指令为 iaload,存储指令为 iastore。

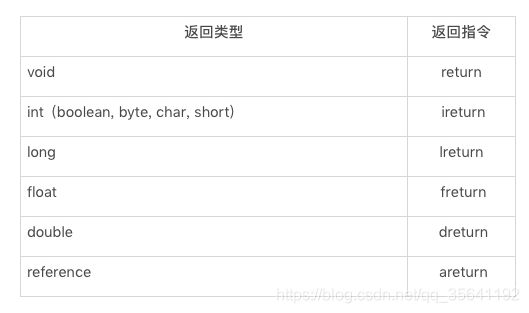
控制流指令,包括无条件跳转 goto,条件跳转指令,tableswitch 和 lookupswtich(前者针对密集的 cases,后者针对稀疏的 cases),返回指令,以及被废弃的 jsr,ret 指令。其中返回指令是区分类型的。例如,返回 int 值的指令为 ireturn。
方法内联
1.方法内联是指,在编译过程中,当遇到方法调用时,将目标方法的方法体纳入编译范围之中,并取代原方法调用的优化手段。
2.即时编译器既可以在解析过程中替换方法调用字节码,也可以在 IR 图中替换方法调用 IR 节点。这两者都需要将目标方法的参数以及返回值映射到当前方法来。
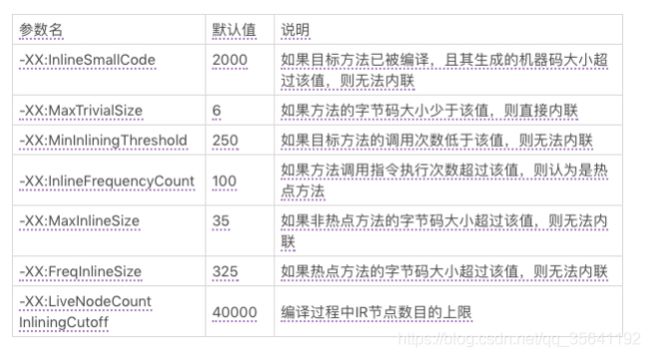
3.方法内联有许多规则。除了一些强制内联以及强制不内联的规则外,即时编译器会根据方法调用的层数、方法调用指令所在的程序路径的热度、目标方法的调用次数及大小,以及当前 IR 图的大小来决定方法调用能否被内联。
4.完全去虚化通过类型推导或者类层次分析,将虚方法调用转换为直接调用。它的关键在于证明虚方法调用的目标方法是唯一的。
5.条件去虚化通过向代码中增添类型比较,将虚方法调用转换为一个个的类型测试以及对应该类型的直接调用。它将借助 Java 虚拟机所收集的类型 Profile。
HotSpot虚拟机的intrinsic
1.HotSpot 虚拟机将对标注了@HotSpotIntrinsicCandidate注解的方法的调用,替换为直接使用基于特定 CPU 指令的高效实现。这些方法便称之为 intrinsic。
2.具体来说,intrinsic 的实现有两种。一是不大常见的桩程序,可以在解释执行或者即时编译生成的代码中使用。二是特殊的 IR 节点。即时编译器将在方法内联过程中,将对 intrinsic 的调用替换为这些特殊的 IR 节点,并最终生成指定的 CPU 指令。
3.HotSpot 虚拟机定义了三百多个 intrinsic。其中比较特殊的有Unsafe类的方法,基本上使用 java.util.concurrent 包便会间接使用到Unsafe类的 intrinsic。除此之外,String类和Arrays类中的 intrinsic 也比较特殊。即时编译器将为之生成非常高效的 SIMD 指令。
- StringBuilder和StringBuffer类的方法。HotSpot 虚拟机将优化利用这些方法构造字符串的方式,以尽量减少需要复制内存的情况。
- String类、StringLatin1类、StringUTF16类和Arrays类的方法。HotSpot 虚拟机将使用 SIMD 指令(single instruction multiple data,即用一条指令处理多个数据)对这些方法进行优化。
举个例子,Arrays.equals(byte[], byte[])方法原本是逐个字节比较,在使用了 SIMD 指令之后,可以放入 16 字节的 XMM 寄存器中(甚至是 64 字节的 ZMM 寄存器中)批量比较。 - 基本类型的包装类、Object类、Math类、System类中各个功能性方法,反射 API、MethodHandle类中与调用机制相关的方法,压缩、加密相关方法。
逃逸分析
1.在 Java 虚拟机的即时编译语境下,逃逸分析将判断新建的对象是否会逃逸。即时编译器判断对象逃逸的依据有两个:一是看对象是否被存入堆中,二是看对象是否作为方法调用的调用者或者参数。
2.即时编译器会根据逃逸分析的结果进行优化,如锁消除以及标量替换。后者指的是将原本连续分配的对象拆散为一个个单独的字段,分布在栈上或者寄存器中。
3.部分逃逸分析是一种附带了控制流信息的逃逸分析。它将判断新建对象真正逃逸的分支,并且支持将新建操作推延至逃逸分支。