(笔记整合)Java并发编程三
Immutability模式
解决并发问题,其实最简单的办法就是让共享变量只有读操作,而没有写操作。这个办法如此重要,以至于被上升到了一种解决并发问题的设计模式:不变性(Immutability)模式。所谓不变性,简单来讲,就是对象一旦被创建之后,状态就不再发生变化。换句话说,就是变量一旦被赋值,就不允许修改了(没有写操作);没有修改操作,也就是保持了不变性。
快速实现具备不可变性的类
实现一个具备不可变性的类,还是挺简单的。将一个类所有的属性都设置成 final 的,并且只允许存在只读方法,那么这个类基本上就具备不可变性了。更严格的做法是这个类本身也是 final 的,也就是不允许继承。因为子类可以覆盖父类的方法,有可能改变不可变性,所以推荐在实际工作中,使用这种更严格的做法。
利用享元模式避免创建重复对象
利用享元模式可以减少创建对象的数量,从而减少内存占用。Java 语言里面 Long、Integer、Short、Byte 等这些基本数据类型的包装类都用到了享元模式。享元模式本质上其实就是一个对象池,利用享元模式创建对象的逻辑也很简单:创建之前,首先去对象池里看看是不是存在;如果已经存在,就利用对象池里的对象;如果不存在,就会新创建一个对象,并且把这个新创建出来的对象放进对象池里。
使用 Immutability 模式的注意事项
- 对象的所有属性都是 final 的,并不能保证不可变性;
- 不可变对象也需要正确发布。
利用 Immutability 模式解决并发问题,也许觉得有点陌生,其实天天都在享受它的战果。Java 语言里面的 String 和 Long、Integer、Double 等基础类型的包装类都具备不可变性,这些对象的线程安全性都是靠不可变性来保证的。Immutability 模式是最简单的解决并发问题的方法,建议当试图解决一个并发问题时,可以首先尝试一下 Immutability 模式,看是否能够快速解决。
具备不变性的对象,只有一种状态,这个状态由对象内部所有的不变属性共同决定。其实还有一种更简单的不变性对象,那就是无状态。无状态对象内部没有属性,只有方法。除了无状态的对象,可能还听说过无状态的服务、无状态的协议等等。无状态有很多好处,最核心的一点就是性能。在多线程领域,无状态对象没有线程安全问题,无需同步处理,自然性能很好;在分布式领域,无状态意味着可以无限地水平扩展,所以分布式领域里面性能的瓶颈一定不是出在无状态的服务节点上。
Copy-on-Write模式
目前 Copy-on-Write 在 Java 并发编程领域知名度不是很高,很多人都在无意中把它忽视了,但其实 Copy-on-Write 才是最简单的并发解决方案。它是如此简单,以至于 Java 中的基本数据类型 String、Integer、Long 等都是基于 Copy-on-Write 方案实现的。
Copy-on-Write 是一项非常通用的技术方案,在很多领域都有着广泛的应用。不过,它也有缺点的,那就是消耗内存,每次修改都需要复制一个新的对象出来,好在随着自动垃圾回收(GC)算法的成熟以及硬件的发展,这种内存消耗已经渐渐可以接受了。所以在实际工作中,如果写操作非常少,那你就可以尝试用一下 Copy-on-Write,效果还是不错的。
线程本地存储模式
线程本地存储模式本质上是一种避免共享的方案,由于没有共享,所以自然也就没有并发问题。如果你需要在并发场景中使用一个线程不安全的工具类,最简单的方案就是避免共享。避免共享有两种方案,一种方案是将这个工具类作为局部变量使用,另外一种方案就是线程本地存储模式。这两种方案,局部变量方案的缺点是在高并发场景下会频繁创建对象,而线程本地存储方案,每个线程只需要创建一个工具类的实例,所以不存在频繁创建对象的问题。
线程本地存储模式是解决并发问题的常用方案,所以 Java SDK 也提供了相应的实现:ThreadLocal。通过分析应该能体会到 Java SDK 的实现已经是深思熟虑了,不过即便如此,仍不能尽善尽美,例如在线程池中使用 ThreadLocal 仍可能导致内存泄漏,所以使用 ThreadLocal 还是需要你打起精神,足够谨慎。
Guarded Suspension模式
Guarded Suspension 模式本质上是一种等待唤醒机制的实现,只不过 Guarded Suspension 模式将其规范化了。规范化的好处是无需重头思考如何实现,也无需担心实现程序的可理解性问题,同时也能避免一不小心写出个 Bug 来。但 Guarded Suspension 模式在解决实际问题的时候,往往还是需要扩展的,扩展的方式有很多,Dubbo 中 DefaultFuture 这个类也是采用的这种方式,可以对比着来看,相信对 DefaultFuture 的实现原理会理解得更透彻。当然,也可以创建新的类来实现对 Guarded Suspension 模式的扩展。
Guarded Suspension 模式也常被称作 Guarded Wait 模式、Spin Lock 模式(因为使用了 while 循环去等待),这些名字都很形象,不过它还有一个更形象的非官方名字:多线程版本的 if。单线程场景中,if 语句是不需要等待的,因为在只有一个线程的条件下,如果这个线程被阻塞,那就没有其他活动线程了,这意味着 if 判断条件的结果也不会发生变化了。但是多线程场景中,等待就变得有意义了,这种场景下,if 判断条件的结果是可能发生变化的。所以,用“多线程版本的 if”来理解这个模式会更简单。
Balking模式
Balking 模式和 Guarded Suspension 模式从实现上看似乎没有多大的关系,Balking 模式只需要用互斥锁就能解决,而 Guarded Suspension 模式则要用到管程这种高级的并发原语;但是从应用的角度来看,它们解决的都是“线程安全的 if”语义,不同之处在于,Guarded Suspension 模式会等待 if 条件为真,而 Balking 模式不会等待。
Balking 模式的经典实现是使用互斥锁,可以使用 Java 语言内置 synchronized,也可以使用 SDK 提供 Lock;如果你对互斥锁的性能不满意,可以尝试采用 volatile 方案,不过使用 volatile 方案需要更加谨慎。
当然也可以尝试使用双重检查方案来优化性能,双重检查中的第一次检查,完全是出于对性能的考量:避免执行加锁操作,因为加锁操作很耗时。而加锁之后的二次检查,则是出于对安全性负责。
Thread-Per-Message模式
Thread-Per-Message 模式在 Java 领域并不是那么知名,根本原因在于 Java 语言里的线程是一个重量级的对象,为每一个任务创建一个线程成本太高,尤其是在高并发领域,基本就不具备可行性。不过这个背景条件目前正在发生巨变,Java 语言未来一定会提供轻量级线程,这样基于轻量级线程实现 Thread-Per-Message 模式就是一个非常靠谱的选择。当然,对于一些并发度没那么高的异步场景,例如定时任务,采用 Thread-Per-Message 模式是完全没有问题的。
Worker Thread模式
解决并发编程里的分工问题,最好的办法是和现实世界做对比。对比现实世界构建编程领域的模型,能够让模型更容易理解。Thread-Per-Message 模式类似于现实世界里的委托他人办理, Worker Thread 模式则类似于车间里工人的工作模式。如果在设计阶段,发现对业务模型建模之后,模型非常类似于车间的工作模式,那基本上就能确定可以在实现阶段采用 Worker Thread 模式来实现。
Worker Thread 模式和 Thread-Per-Message 模式的区别有哪些呢?从现实世界的角度看,委托代办人做事,往往是和代办人直接沟通的;对应到编程领域,其实现也是主线程直接创建了一个子线程,主子线程之间是可以直接通信的。而车间工人的工作方式则是完全围绕任务展开的,一个具体的任务被哪个工人执行,预先是无法知道的;对应到编程领域,则是主线程提交任务到线程池,但主线程并不关心任务被哪个线程执行。
Worker Thread 模式能避免线程频繁创建、销毁的问题,而且能够限制线程的最大数量。Java 语言里可以直接使用线程池来实现 Worker Thread 模式,线程池是一个非常基础和优秀的工具类,甚至有些大厂的编码规范都不允许用 new Thread() 来创建线程的,必须使用线程池。
不过使用线程池还是需要格外谨慎的,如何正确创建线程池、如何避免线程死锁问题,还需要注意 ThreadLocal 内存泄露问题。同时对于提交到线程池的任务,还要做好异常处理,避免异常的任务从眼前溜走,从业务的角度看,有时没有发现异常的任务后果往往都很严重。
两阶段终止模式
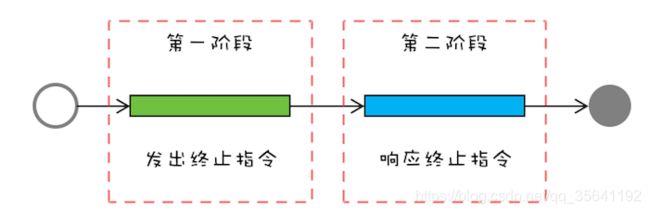
两阶段终止模式是一种应用很广泛的并发设计模式,在 Java 语言中使用两阶段终止模式来优雅地终止线程,需要注意两个关键点:一个是仅检查终止标志位是不够的,因为线程的状态可能处于休眠态;另一个是仅检查线程的中断状态也是不够的,因为依赖的第三方类库很可能没有正确处理中断异常。
当使用 Java 的线程池来管理线程的时候,需要依赖线程池提供的 shutdown() 和 shutdownNow() 方法来终止线程池。不过在使用时需要注意它们的应用场景,尤其是在使用 shutdownNow() 的时候,一定要谨慎。
生产者-消费者模式
生产者 - 消费者模式的核心是一个任务队列,生产者线程生产任务,并将任务添加到任务队列中,而消费者线程从任务队列中获取任务并执行。
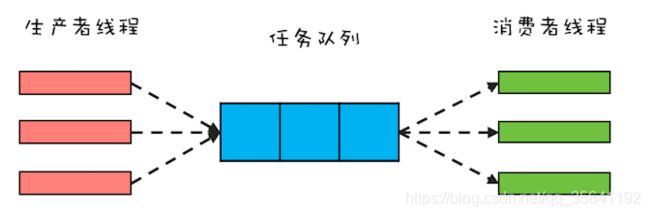
Java 语言提供的线程池本身就是一种生产者 - 消费者模式的实现,但是线程池中的线程每次只能从任务队列中消费一个任务来执行,对于大部分并发场景这种策略都没有问题。但是有些场景还是需要自己来实现,例如需要批量执行以及分阶段提交的场景。
生产者 - 消费者模式在分布式计算中的应用也非常广泛。在分布式场景下,可以借助分布式消息队列(MQ)来实现生产者 - 消费者模式。MQ 一般都会支持两种消息模型,一种是点对点模型,一种是发布订阅模型。这两种模型的区别在于,点对点模型里一个消息只会被一个消费者消费,和 Java 的线程池非常类似(Java 线程池的任务也只会被一个线程执行);而发布订阅模型里一个消息会被多个消费者消费,本质上是一种消息的广播,在多线程编程领域,可以结合观察者模式实现广播功能。