《SparkSQL 1》--SparkSQL简介、RDD与DataFrame、搭建SparkSQL环境、创建DF、DataFrame常用操作、DataSet、SparkSQL的执行计划和执行流程
引言:
给定一个包含用户基本信息(如姓名、年龄等)的数据集,请统计相同姓名的用户的平均年龄?
SparkRDD实现:
val data = sc.textFile("/data/input.txt").split("\t")
data.map(x=>(x(0),(x(1).toInt,1)))
.reduceByKey((a,b)=>a._1+b._1,a._2+b._2)
.map(x._1,x._2._1/x._2._2).collect
SQL实现:
SELECT name,avg(age) FROM people GROUP BY name
Spark SQL:
1.Spark SQL是Spark的重要组成模块,也是目前大数据生产环境中使用最广泛的技术之一,
主要用于结构化数据处理。
SparkSQL提供相应的优化机制,并支持不同语言的开发API:
java、scala、Python,类SQL的方法调用(DSL)
根据Spark官方文档的定义:
Spark SQL是一个用于处理结构化数据的Spark组件--该定义强调的是"结构化数据",而非"SQL"
介绍SparkSQL,不得不提Hive和Shark,Hive是Shark的前身,Shark是SparkSQL的前身.
根据伯克利实验室提供的测试数据,Shark在基于内存计算的性能比Hive高出10位(将近千倍), 即使基于磁盘计算,它的性能也比Hive高出10倍, 而Spark SQL的性能比Shark又有较大的提升.
SparkSQL的API设计简洁高效,可以与Hive表直接进行交互,并且支持JDBC/ODBC连接,
Spark先后引入了DataFrame和DataSet两种数据结构,以便更加高效地处理各种数据
2.RDD与Spark SQL的比较说明:
---使用Spark SQL的优势:
a.面向结构化数据;
b.优化机制;
---RDD缺点:
a.没有优化机制,如对RDD执行Filter操作;
b.RDD类型转换后无法进行模式推断
3.【RDD与DataFrame结构对比】
RDD与DataFrame的区别: RDD[Person]虽然以Person为类型参数,但是Spark框架本身不了解Person类型的内部结构, 而DataFram却提供了详细的结构信息,使得SparkSQL可以清楚地知道该数据集中包含哪些列, 每列的名称和类型分别是什么,这和关系数据库中的物理表类似。
DataFrame/SchemaRDD:
DataFrame是一个分布式的数据集合,该数据集合以命名列的方式进行整合。
Dateframe=RDD(数据集)+Schema(元数据/模型)
SchemaRDD就是DataFrame的前身,在1.3.0版本后。
SchemaRDD还包含记录的结构信息(即数据字段) DataFrame存放的是ROW对象。每个Row 对象代表一行记录。
https://mvnrepository.com
4.创建Spark SQL环境
a.将SparkSQL依赖库添加至pom.xml文件中
b.SparkSession
Spark2.0引入了SparkSession,用于在Spark SQL开发过程中初始化上下文,为用户提供统一的入口。
用户可以通过SparkSession API直接创建DataFrame和DataSet。Spark2.0之前版本初始化上下文需要
创建SparkContext、SQLContext、HiveContext、SparkConf,从Spark2.0版本开始不再需要之前复杂
的操作,所有运行时参数设置,获取都可以通过conf方法实现.conf方法返回RuntimeConfig对象,
RuntimeConfig对象包含Spark、Hadoop等运行时的配置信息
Spark2.0之前版本SQLContext创建方式如下:
val sparkConf = new SparkConf().setAppName("word cont")
val sc = new SparkContext(sparkConf)
val sqlContext = new SQLContext(sc)
Spark2.0之后:
通过SparkSession.builder()创建构造器;
并调用.appName("sparkSQL").master("local")设置集群模式以及app名称
最后必须调用getOrCreate()方法创建SparkSession对象。
val spark = SparkSession.builder().appName("sparkSQL").master("local").getOrCreate()
DataFrame(DF):在Spark1.3之前版本中,用户使用Spark SQL时需要直接操作RDD API,学习成本相对较高,
代码结构相对复杂,为了提高任务执行性能,用户还需要掌握一些调优手段,Spark从1.3版本引入DataFrame,
DataFrame是一种带有Schema元信息的分布式数据集,类似于传统数据库中的二维表,定义有字段名称和类型,
用户可以像操作数据库表一样使用DataFrame,DataFrame的开发API简洁高效,代码结构清晰,并且Spark针对
DataFrame的操作进行了丰富的优化。DataFrame支持Java、Scala、Pythont等多种开发语言,不论是专业的开发
人员,还是数据分析人员都可以轻松地使用DataFrame处理结构化数据。
DF创建方式 【4种】
users.txt
anne 22 NY
joe 39 CO
alison 35 NY
mike 69 VA
marie 27 OR
jim 21 OR
bob 71 CA
mary 53 NY
dave 36 VA
dude 50 CA
通过SparkSession的read()方法加载不同的数据源:json、CVS、jdbc、textfile、parquert等
1.read.textFile()
val spark = SparkSession.builder().appName("sparkSQL").master("local").getOrCreate()
val df = spark.read.textFile("file:///d:/测试数据/users.txt").toDF()
df.show() +-------------+
| value|
+-------------+
| anne 22 NY |
| joe 39 CO |
|alison 35 NY |
| mike 69 VA |
| marie 27 OR|
| jim 21 OR|
| bob 71 CA|
| mary 53 NY|
| dave 36 VA|
| dude 50 CA|
+-------------+
2.读取HDFS指定路径下的JSON文件创建DataFrame:
val jsonDF = spark.read.json("hdfs://datasource/data.json")
3.加载hdfs指定路径下的CSV文件格式化为CSV格式,并创建DataFrame:
val csvDF = spark.read.format("csv").load("hdfs://datasource.csv")
4.读取HDFS指定路径下的Parquet文件,并创建DataFrame:
val parqueDF =spark.read.parquet("hdfs://datasource/data.parquet") DF创建方式总结:
-----------------------------------------------------------------------------------------
1.通过SparkSession的createDataFrame(...)方法创建DF对象
a.将Seq序列转换为DF
b.将RDD[Product]多元素转换为DF
2.通过SparkSession的read读取外部文件调用toDF()
3.通过导入隐式转换,可直接将Scala中的序列转换为DF
val spark = SparkSession.builder().appName("sparkSQL").master("local").getOrCreate()
import spark.implicits._
val list = List(("zhangsan",12,"changchun"),("lilei",25,"haerbin"))
val df_implicits = list.toDF()
df_implicits.show()
DataFrame常用操作
1)toDF函数
作为DataSet的一种特殊形式,DataFrame的toDF函数定义在DataSet类中,函数的作用是将RDD转换为DataFrame
函数定义如下:
def toDF():DataFrame = new Dataset[Row](sparkSession,queryExecution,RowEncoder(schema))
2)as函数
返回一个指定别名的新DataSet def as[U : Encoder]: Dataset[U] = Dataset[U](sparkSession, logicalPlan)
3)printSchema函数
打印DataFrame的Schema信息 def printSchema(): Unit = println(schema.treeString)
4)show函数
默认以表格形式展现DataFrame数据集的前20行数据,字符串类型数据长度超过20个字符将会被截断,
如果需要控制显示的数据条数和字符串截取显示情况,可以使用带有不同的参数的show方法.
5)createTempView函数和createOrReplaceTempView函数
创建临时视图,创建并覆盖视图(如果视图名称已经存在将会被新的视图替换替换覆盖) def createTempView(viewName: String): Unit = withPlan { createTempViewCommand(viewName, replace = false, global = false) }
def createOrReplaceTempView(viewName: String): Unit = withPlan { createTempViewCommand(viewName, replace = true, global = false) }
6)createGlobalTempView函数
创建全局临时视图,该视图的生命周期与Spark应用程序生命周期相关,随着Spark应用程序终止自动删除。 def createGlobalTempView(viewName: String): Unit = withPlan { createTempViewCommand(viewName, replace = false, global = true) }
DataSet(DS)
DataSet是一个特定域的强类型的不可变数据集,每个DataSet都有一个非类型化视图DataFrame
(DataFrame是DataSet[Row]的一种表示形式),DataFrame可以通过调用 as(Encoder)函数转换成DataSet,
而DataSet则可以调用toDf()函数转换成DataFrame,两者之间可以互相灵活转换.
操作DataSet可以像操作RDD一样使用各种转换(Transformation)算子并行操作,转换操作采用"惰性"执行方式
当调用Action算子时才会触发真正的计算执行.
创建DataSet:
import org.apache.spark.sql.SparkSession
object SparkSQL {
//1)通过case class创建:
case class Person(name:String,age:Int,address:String)
//2)DataFrame调用as[Encoder]函数创建
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("sparkSQL").master("local").getOrCreate()
import spark.implicits._
val dataArr = Seq(1, 2, 3).toDS
//val dataArr = List(2, 3, 4).toDS()
//显示数据集的信息
dataArr.show
//对属性进行简单操作
dataArr.map(_ + 1).show()
}
}运行结果:
+-----+
|value|
+-----+
| 2|
| 3|
| 4|
+-----+
创建DataSet,加载Json文件
people.json 在 spark 自带文件夹内
集群下:cd $SPARK_HOME/
examples/src/main/resources/people.json
case模式匹配在spark2.11之前版本最多支持22个参数
import org.apache.spark.sql.SparkSession
object sparkSqlTest {
case class Person(name: String, age: Long)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("sparkSQL").master("local").appName("abc").getOrCreate()
import spark.implicits._
val path = "file:///D:/测试数据/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
}
}
textFile-->RDD-->DataFrame-->查看DF的Schema
1.案例说明:
val spark = SparkSession.builder().appName("sparkSQL").master("local").getOrCreate()
val sc = spark.sparkContext
val rdd = sc.textFile("file:///d:/测试数据/users.txt")
.map(x=>x.split(" "))
.map(x=>(x(0),x(1),x(2)))
val df_rdd = spark.createDataFrame(rdd)
df_rdd.show()
df_rdd.select("_1","_2").where("_1 like '%o%'").show()
df_rdd.printSchema() Dateframe=RDD(数据集)+Schema(元数据/模型)
root
|-- _1: string (nullable = true)
|-- _2: string (nullable = true)
|-- _3: string (nullable = true)
df_rdd.show()
+------+---+---+
| _1| _2| _3|
+------+---+---+
| anne| 22| NY|
| joe| 39| CO|
|alison| 35| NY|
| mike| 69| VA|
| marie| 27| OR|
| jim| 21| OR|
| bob| 71| CA|
| mary| 53| NY|
| dave| 36| VA|
| dude| 50| CA|
+------+---+---+
df_rdd.select("_1","_2").where("_1 like '%o%'").show()
+------+---+
| _1| _2|
+------+---+
| joe| 39|
|alison| 35|
| bob| 71|
+------+---+
----通过case用例类可以对DF进行Schema匹配
case class Person(name:String,age:Int,address:String)
val rdd = sc.textFile("file:///d:/测试数据/users.txt")
.map(x=>x.split(" "))
.map(x=>new Person(x(0),x(1).toInt,x(2)))
val df_rdd = spark.createDataFrame(rdd)
df_rdd.printSchema()
df_rdd.show() root:
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- address: string (nullable = true)
df_rdd.show():
+------+---+-------+
| name|age|address|
+------+---+-------+
| anne| 22| NY|
| joe| 39| CO|
|alison| 35| NY|
| mike| 69| VA|
| marie| 27| OR|
| jim| 21| OR|
| bob| 71| CA|
| mary| 53| NY|
| dave| 36| VA|
| dude| 50| CA|
+------+---+-------+
总结:Spark 提供了两种方式将RDD转换成DataFrames:
·通过定义Case Class,使用反射推断Schema(Case Class方式)。
·通过可编程接口,定义Schema,并应用到RDD上(createDataFrame方式)。
前者使用简单、代码简洁,适用于已知Schema的源数据上;
后者使用较为复杂,但可以在程序运行过程中实行,适用于未知Schema的RDD上。
实现简单的select操作:
df_rdd.select("name","age").where("name like '%o%'").show() +------+---+
| name|age|
+------+---+
| joe| 39|
|alison| 35|
| bob| 71|
+------+---+
查询的 操作方式:
1.显示:
df_rdd.show()2.查询:
df_rdd.select("name").show()3.条件查询:
import spark.implicits._
df_rdd.select($"name",$"age").where("name like '%o%'").show() //注:引入spark.implicits._ +------+---+
| name|age|
+------+---+
| joe| 39|
|alison| 35|
| bob| 71|
+------+---+
4.条件查询:
import spark.implicits._
df_rdd.select($"name",$"age"+1).where("name like '%o%'").show() +------+---------+
| name|(age + 1)|
+------+---------+
| joe| 40|
|alison| 36|
| bob| 72|
+------+---------+
5.过滤操作
//a.通过过滤表达式:
df_rdd.filter("age > 36").show()
//b.通过func式编程进行处理,DF中每个元素均为ROW
df_rdd.filter(x=>{if(x.getAs[Int]("age") > 36) true else false }).show()6.分组操作
df_rdd.groupBy("address").count().show +-------+-----+
|address|count|
+-------+-----+
| OR| 2|
| VA| 2|
| CA| 2|
| NY| 3|
| CO| 1|
+-------+-----+
DF映射表的形式
1.临时表:针对SparkSession
使用DF.createTempView("person")对数据集注册临时表
通过spark.sql(.....)
代码说明:
df_rdd.createTempView("person")
spark.sql("select * from person where name like '%0%'").show() +------+---+-------+
| name|age|address|
+------+---+-------+
| joe| 39| CO|
|alison| 35| NY|
| bob| 71| CA|
+------+---+-------+
df_rdd.createTempView("person")
spark.sql("select * from person where name like '%o%'").show()
df_rdd.createTempView("person")
spark.sql("select * from person where name like '%o%'").show()
###TempTableAlreadyExistsException: Temporary table 'person' already exists;
如果视图名已经存在将会被新的视图替换覆盖
df_rdd.createOrReplaceTempView("person")
创建临时视图
df_rdd.createTempView("person")
spark.sql("select * from person where name like '%o%'").show()在新建的sparkSession中查看临时视图报错,不在作用域范围内
spark.newSession().sql("select * from person where name like '%o%'").show()
2.全局表:针对SparkApplication
使用DF.createGlobalTempView("person")对数据集注册临时表
创建全局视图
df_rdd.createGlobalTempView("person")两种方式都可以查看全局视图【global_temp.表名】
spark.sql("select * from global_temp.person where name like '%o%'").show()
spark.newSession().sql("select * from global_temp.person where name like '%o%'").show() +------+---+-------+
| name|age|address|
+------+---+-------+
| joe| 39| CO|
|alison| 35| NY|
| bob| 71| CA|
+------+---+-------+
使用反射推断模式:
案例:加载文件-->RDD--> DataFrame-->注册为表 表可以在后续SQL语句中使用
import org.apache.spark.sql.SparkSession
object sparkSqlTest {
case class Person(name: String, age: Long)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("sparkSQL").master("local").getOrCreate()
import spark.implicits._
val peopleDF = spark.sparkContext
.textFile("file:///D:/测试数据/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
// Register the DataFrame as a temporary view
peopleDF.createOrReplaceTempView("people")
// SQL statements can be run by using the sql methods provided by Spark
val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")
//按照字段索引号,打印结果
teenagersDF.map(teenager => "Name: " + teenager(0)).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
//按字段名称,打印结果
teenagersDF.map(teenager => "Name: " + teenager.getAs[String]("name")).show()
}
}物理执行计划生成任务运行在executor上,通过stage划分查看分配多少个任务,webUI:4040查看
Spark SQL的执行计划 【explain】
0. 代码:
val query_df = spark.sql("select name,count(*) from people group by name")1.查看物理执行计划
query_df.explain() 2.explain(true)查看整个SQL的执行计划,主要分为4个阶段:
a.解析过程 
说明:Project:映射,返回结果
b.逻辑计划
== Analyzed Logical Plan ==
name: string, count(1): bigint
Aggregate [name#3], [name#3, count(1) AS count(1)#17L]
+- SubqueryAlias people, `people`
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, TestDataFrame$Person, true]).name, true) AS name#3, assertnotnull(input[0, TestDataFrame$Person, true]).age AS age#4L]
+- ExternalRDD [obj#2]
c.优化阶段
== Optimized Logical Plan ==
Aggregate [name#3], [name#3, count(1) AS count(1)#17L]
+- Project [name#3]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, TestDataFrame$Person, true]).name, true) AS name#3, assertnotnull(input[0, TestDataFrame$Person, true]).age AS age#4L]
+- ExternalRDD [obj#2]
d.物理执行计划
== Physical Plan ==
*HashAggregate(keys=[name#3], functions=[count(1)], output=[name#3, count(1)#17L])
+- Exchange hashpartitioning(name#3, 200)
+- *HashAggregate(keys=[name#3], functions=[partial_count(1)], output=[name#3, count#19L])
+- *Project [name#3]
+- *SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, TestDataFrame$Person, true]).name, true) AS name#3, assertnotnull(input[0, TestDataFrame$Person, true]).age AS age#4L]
+- Scan ExternalRDDScan[obj#2]
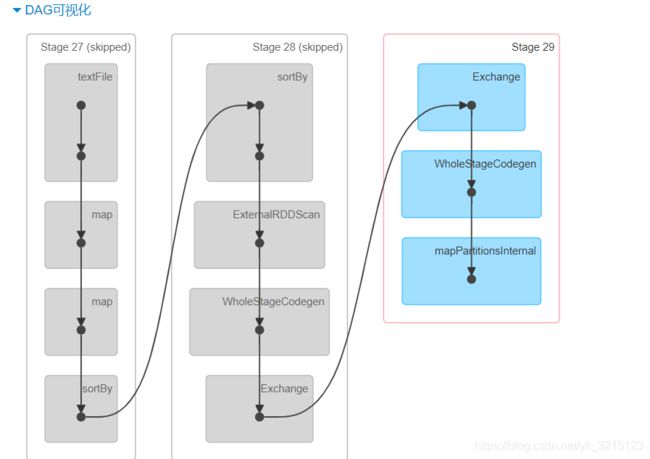
SparkSQL执行流程
1.SQL执行过程
在传统关系型数据库中
最基本的SQL查询语句如SELECT fieldA,fieldB,fieldC FROM tableA WHERE fieldA>10,
由Projection(fieldA、fieldB、fieldC)、Data Source(tableA)和Filter(fieldA>10)三部分组成,
分别对应SQL查询过程中的Result、Data Source和Operation,
也就是说SQL语句按Result→Data Source→Operation的次序来描述的
但在实际执行SQL语句的过程中是按照Operation→Data Source→Result的顺序来执行,
与SQL 语法顺序刚好相反,其具体执行过程如下。
(1)词法和语法解析(Parse):对读入的SQL语句进行词法和语法解析(Parse),
分辨出SQL 语句中哪些词是关键词(如SELECT、FROM和WHERE)、哪些是表达式、哪些是Projection、
哪些是Data Source等,判断SQL语句是否规范,并形成逻辑计划。
(2)绑定(Bind):将SQL语句和数据库的数据字典(列、表和视图等)进行绑定(Bind),
如果相关的Projection和Data Source等都存在的话,则表示这个SQL语句是可以执行的。
(3)优化(Optimize):一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,
数据库会在这些计划中选择一个最优计划。
(4)执行(Execute):执行前面的步骤获取的最优执行计划,返回从数据库中查询的数据集。
Spark SQL
----------------------------------
1.RDD[Person]-----(case:反射机制)------>DataFrameF[ROW]---->DataSet[Person]
RDD DF DS
Person ["name","age","address"] {Person:("name","age","address")}
Person ["name","age","address"] {Person:("name","age","address")}
Person ["name","age","address"] {Person:("name","age","address")}
Person ["name","age","address"] {Person:("name","age","address")}
Person ["name","age","address"] {Person:("name","age","address")}
2.RDD-->DataFrame-->DataSet
a.RDD-->DataFrame: sparksession.createDataFrame
toDF
b.RDD-->DataSet: sparksession.createDataSet
c.DF,DS-->RDD: DF.rdd-->RDD[ROW]; DS.rdd-->RDD[Person]
d.DataFrame-->DataSet: sparksession.createDataSet(df.rdd)
.as[T]
e.DataSet-->Datafrmae: DS.toDF()
案例:RDD-->DataFrame (toDF)
import org.apache.spark.sql.SparkSession
object S1 {
def main(args: Array[String]): Unit = {
val sparksession = SparkSession.builder().appName("sparkSQL").master("local").getOrCreate()
//创建 rdd
val colors = List("white","green","yellow","red")
val rdd = sparksession.sparkContext.parallelize(colors)
val rdd1 = rdd.map(x=>(x,x.length))
rdd1.foreach(println)
// rdd -> DF
import sparksession.implicits._
val df =rdd.map(x=>(x,x.length)).toDF("color","length")
df.show()
}
}