身份采集、活体检测、人脸比对...旷视是如何做FaceID的? | 公开课笔记
作者 | 彭建宏(旷视科技产品总监彭建宏)
整理 | Just
出品 | 人工智能头条(公众号ID:AI_Thinker)
“刷脸”曾一度是人们互相调侃时的用语,如今早已深深地融入我们的生活。从可以人脸解锁的手机,到人脸识别打卡机,甚至地铁“刷脸”进站……
人脸识别技术越来越多地应用在了各种身份验证场景,在这种看起来发生在电光火石之间的应用背后,又有哪些不易察觉的技术在做精准判别?算法又是通过何种方式来抵御各种欺诈式攻击?
我们近期邀请到旷视科技产品总监彭建宏,他负责 FaceID 在线身份验证云服务的产品设计。在本次公开课上,他讲述了深度学习在互联网身份验证服务中的应用以及人脸识别活体检测(动作、炫彩、视频、静默)技术应用场景及实现方式。
(视频地址:https://v.qq.com/x/page/k0678hscngd.html)
以下为彭建宏公开课演讲内容实录:
今天我们主要说的是 FaceID,它在我们产品矩阵里更像是一套解决方案,是身份验证的金融级解决方案。我们在生活中有很多场景是想验证,证明你是你。
基本所有的互联网金融公司都会在我们借贷的时候要去验证你是你,这就需要做一个你是你这样一个证明,所以如何提供一套可靠的方案去验证你是你这件事情就已经变得非常重要,大家可能很容易想到验证的方法有很多,包括之前大量使用的指纹识别,还有一些电影里边经常出现的虹膜识别,还有最近特别火的人脸识别。
下面我说一下技术特点。关于人脸识别,大家很容易想到第一个特点就是体验非常好,非常自然、便利,但它的缺点也很多,首先隐私性更差,我们要想获得别人的指纹和虹膜的代价非常大,但是要获得别人面部的照片这个代价就非常的小了。第二是由于光照、年龄、胡须、还有眼镜等等因素,人脸识别的稳定性会比较低。第三是指纹识别、虹膜识别都有主动性,人脸识别具有被动性,这也是之前 iPhoneX 刚出来的时候,很多人担心不经意被人错刷,或者去误刷支付或者检索等等——弱阴私性,弱稳定性还有被动性,就对人脸识别的商业化应用提出了更高的技术要求。
深度学习技术的迅猛发展,使得图像识别、分类跟检测的准确率大幅提高,但真正要做成一套金融级解决方案还不是那么简单的,这张图就展示了一个整体的 FaceID 提供的金融级整体的解决方案。
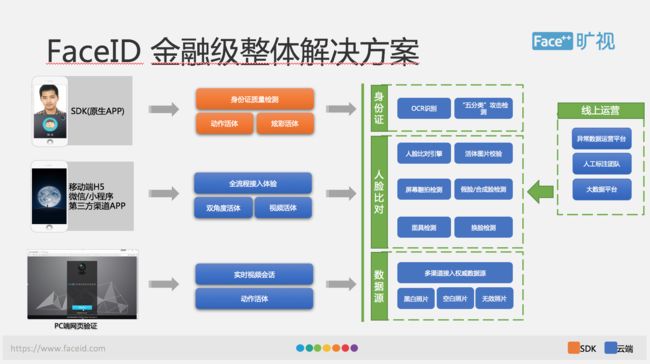
在这个架构图中,我们可以看到,FaceID 的用户提供了多种产品形态,包括移动端的 SDK,H5,微信/小程序、第三方渠道 APP 以及 PC 端。从功能上来说呢,我们的产品包括身份证的质量检测、身份证 OCR 识别、活体检测、攻击检测以及人脸比对,整个解决方案可以看出是建立在云跟端两个基础上,我们在端上提供了 UI 解决方案,就提供 UI 界面可以方便集成,如果觉得我们的 UI 做得不符合大家的要求,也可以去做一些定制化开发,整个核心功能里有活体检测,在端上跟云上分别有自己的实现。
同时针对不同的活体攻击方案,还会采用不同的活体策略。我们在现实中的活体检测中,线上运营会实时收集各种图片做标注,及时把算法进行更新,可以确保最新的攻击可以在第一时间内进行响应和返馈,这也是为我们整个深度学习算法不断注入新血液。
▌身份证采集

整个流程是这样的,用户会先进行身份证采集,系统其实会要求用户先去拍一张身份证的正面跟反面,这个过程是在端上进行完成的。拍摄以后,我们会在云上进行,OCR 识别是在云上完成的,我们不仅会去识别身份证上面的信息,还会去识别这个身份证的一些分类。由于不同的业务场景不同,这个分类信息会反馈给用户,用户来判断是否接受。在很多严肃的场景下,很多客户可能只能接受身份证原件,识别出来的文字我们也会根据用户的业务不同做相应不同的处理,因为有些客户就要我们识别出来的文字,用户是不能去修改身份证号和姓名的。

我们在 OCR 里面还加入了很多逻辑判断,例如大家知道在身份证号里面是可以看出来用户生日还有性别信息,如果我们发现身份证上的生日跟身份证号判断出来的信息不一样,我们就会在 API 的结果里面给用户返回逻辑错误,这是用户可以根据业务逻辑可以自行进行处理的。
这个展示就是我们身份证采集以及身份证 OCR 的一些场景。先通过手机的摄像头去采集,在我们的云端去完成 OCR 识别以及物体分类,可以去判断是不是真实的身份证。有一个需要讨论的问题是,为什么我们把 OCR 放在了云端,而不是放在手机的 SDK 端呢?这个主要是安全方面的考虑,如果信息被黑客攻破,这在端上是相当危险的事。
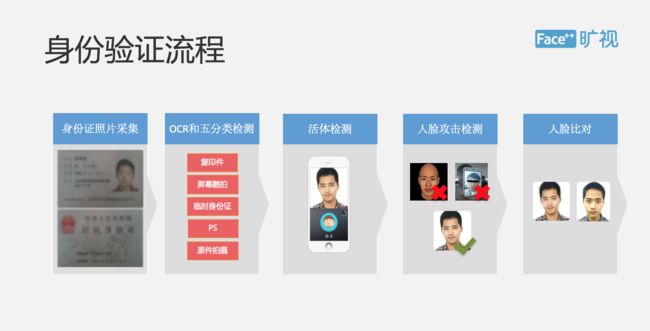
▌活体攻击检测方案

下面我们来去讨论一下最重要的活体攻击。在我们的产品里面提供了多种活体攻击的检测方案,包括随机、动态的活体,包括视频活体、炫彩活体等等。活体检测是我们整个 Face ID 最重要的一环,也是我们最重要的核心优势。这个 PPT 展示的是我们的动作活体,用户可以根据我们的 UI 提示进行点头、摇头这样的随机动作,所以我们每次随机动作都是 Serves 端去发出的,这样也保证我们整个动作的安全性。这里面有些技术细节,包括人脸质量检测,人脸关键点的感测跟跟踪,脸部的 3D 姿态的检测。这是我们整个技术的一些核心竞争力。然后我们会帮助用户定义一套 UI 界面,如果用户觉得我们 UI 界面不好也可以直接去修改。

我们提供一种叫炫彩活体的检测方法,这个是 Face++ 独特独创的一种根据反射光三维成像的原理进行活体检测,从原理上杜绝了各种用 3D 软件合成的视频、屏幕翻拍等等的攻击。从产品形态上来说本身又是一个视频,现在可能看不到,就是屏幕会发出一种特定图案进行活体判断。
现在活体有一个比较大的问题是当在强光下它的质量检测方法,效果不太好,我们在最后会配合一个简单的点图动作,这样就提高了整个攻击的门槛,然后针对移动 H5 的场景我们主要推出了一个视频活体的检测方法,用户会根据 UI 提供的一个数字去读这样一个四位数字,同时我们会去判断,不仅会去做云方面的识别,还会做传统方面的识别,以及两者之间的语音跟声音同步检测。
这样通过这三种方案去判断就是活体检测,除了刚才我们介绍的一些比较典型的方法之外,我们也在去尝试一些新的包括双角度活体跟静默活体。双角度活体是用户拍一张正脸的自拍照与侧面自拍照,通过这种 3D 建模重建的方式来判断是不是真人,我们的双角度活体,静默活体,为用户提供一种非常好的用户体验,相当于用户拍一个两秒钟的视频。

我们会将这个视频传到云端,这样我们不仅会去做单帧的活体检测,还会去做多帧之间的这种关联性活体检测,这样通过两种动静结合的方法去判断受测人是不是真人。
除了活体检测之外,我们还提供了一套叫做 FMP 的攻击检测,可以有效去识别翻拍,面具攻击,这是在我们的云端完成的。这是我们基于大量的人脸数据训练出一套叫 FMP 的深度神经网络,并且根据线上的数据进行实时返回和调整,不断去识别准确率,这也是我们整个活体检测里一个最重要的技术难点。
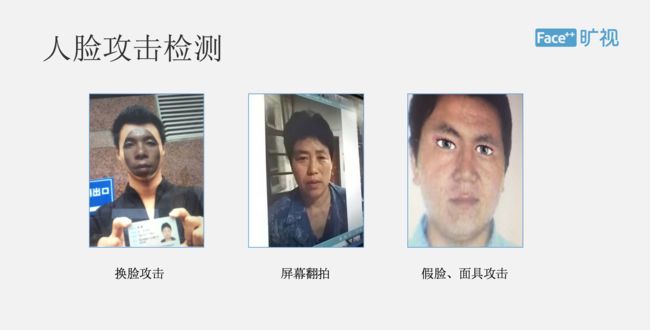
▌人脸比对
活体检验之后,我们就可以进行人脸比对的环节。我先简单跟大家介绍一下人脸识别的一个基本原理:首先我们会从一幅图片里面去做人脸检测并做出标识,相当于在一张图片里面找到这张人脸,并且表示出整个人脸上的一些基本关键点,如眼睛、眉毛等等。
下面要做的是将一些人脸关键点进行对齐,作用是为之后的人脸识别算法提供数据预处理,可以提高整个算法准确度。然后,我们会把整个人脸的那部分抠出来,这样就可以避免周围物体对它的影响,抠完之后的人脸会经过深度学习网络,最终生成一个叫做表示的东西,可以把表示理解为这张图片生成的一张向量,认为是在机器认知里面这张图片就是通过这样的向量来进行表示的。但这个怎么样去衡量这个标识能够真实的刻画出这张真实的人脸?
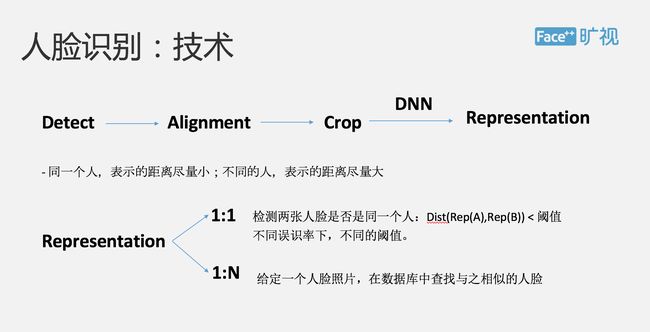
我们现在有个原则:如果同一个人,我们希望表示之间的距离要尽量的近,如果是不同的人,我们希望表示的距离尽量的远,这就是我们去评价一个深度学习出来的一个表示好坏。然后基于这样的表示,在人脸识别里边有两个比较大的应用,我们分别叫做 1:1 与 1:N 的识别。
前者主要是比较两张人脸识别是不是同一个人,它的原理是我们去计算两张人脸表示的距离,如果这个距离小于一个域值,我们就会认为这个是同一个人,如果是大于某一域值,我们就认为它不是同一个人,在不同的误识率下,我们会提供不同的域值。第二个 1:N 的应用,主要应用场景是安防,也就是说我们提供一张人脸照片,在数据库里面去查找已知,最相似的这样一个人脸是 1:7 的应用,FaceID 主要应用的技术场景是 1:1。
当我们通过 OCR 去识别出来用户姓名、身份证号,并通过活体检测之后,我们会从公安部的权威数据库里面去获得一张权威照片,会跟用户视频采集到的一张高质量照片进行比对,会返回给用户是不是一致,当然我们不会去直接告诉用户是不是一致,而是会通过这种近似度的方式告知。
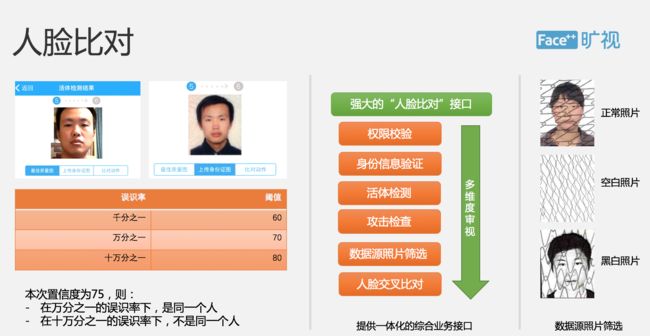
大家可以看一下左侧的这张表,然后这边的返回值里面提供了千分之一、万分之一、十万分之一不同的近似度,这些表示的是误识率,在不同的误识率下会有一个域值,假设我们认为在千分之一误识率下,如果分数大于 60 分,我们就会认为是同一个人,所以这两张照片,我发现他们的这个近似度是 75,我们会说在万分之一的误识率下是同一个人,但是在十万分之一这种误识率下可能他们不是同一个人。
这里有一个细节是我们的照片数据源可能会提供不同的整个时间造成不同的障碍,正常的话,我们会有一个不同的这种纹理图案,但是有时我们会获得一张空白照片,或者获得一张黑白照片,这也需要我们去做一些后台方面的处理。
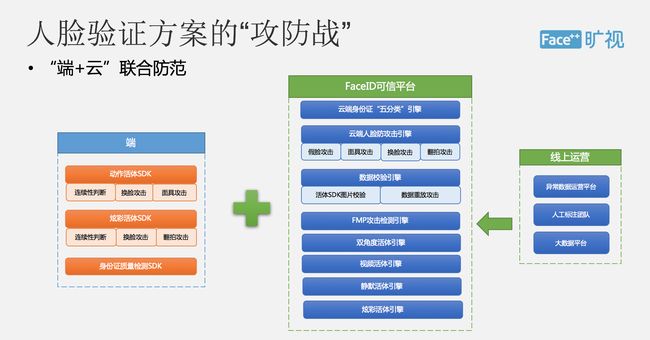
所以总结一下就是 Face ID 会为大家提供一整套的这种身份验证解决方案,整个方案涵盖了质量检测、身份证识别、活体检测、攻击检测和人脸比对等一系列的功能,其中在活体检测方面,我们采用了云加端的这种联合防范方式,通过不同的活体检测方案,包括动作活体、视频活体、静默活体等一系列的检测方法,可以有效的预防假脸攻击。
在线上我们每天都会遇到各种各样的攻击方式,整个人脸验证的方案是一套长期攻防战,我们现在通过线上运营的方式不断去收集攻击的异常数据,进行人工标注、训练、分析,然后可以不断提升整个模型的防范能力,在这方面我们已经形成了一套闭环系统,发现任何的攻击我们都可以在很短的时间内去更新线上的一些模型,做到充分防范。
▌工业化AI算法生产
下面我简单介绍一下整个工业化 AI 算法的一个产生过程,其实整个流程可以看成是数据驱动,包括数据采集、清洗、标注,包括数据增广、数据的域训练模型、时间管理,还有 SDK 封装等等。
介绍一些核心关键点,第一个是数据采集,我们是通过一个叫做 Data++ 的 Team 去负责数据采集跟标注,我们会通过线下采集,或者是通过重包标注和网络爬虫几种方式去获取整个的 AI 训练原材料。
有了数据之后,我们一个叫 Brain++的平台可以把它看成是整个 AI 芯片的一个炼丹炉,它会提供整个计算存储网络等 IaaS 层的一些管理,这样我们整个算法工程师训练的时候相当于在单机上面去跑,但在不同分布式的底层调度是在多台机器上面,已经通过 Brain++ 的平台把我们屏蔽掉了,所以如果我们可以去写类似于的语句,需要 20 个 CPU、 4 个 GPU、8G 的内存去跑这样一个训练脚本,底下是通过分布式方法去训练的,但我们提供单向运行脚本就可以了。
然后除了数据,IaaS 层的这种资源,我们研发了一套类似于 TensorFlow 的并行计算框架和引擎 Megbrain,跟 TensorFlow 相比,很多地方都做了不同优化。
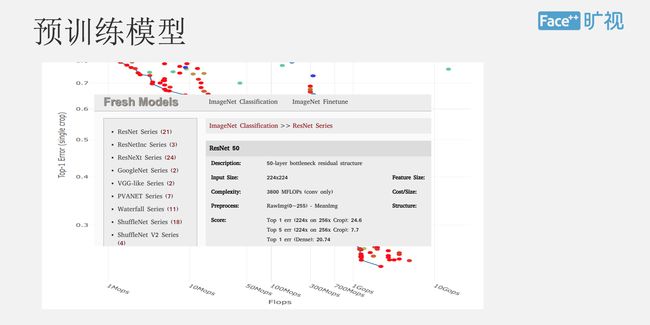
下面说一下我们的域训练模型,我们的团队去训练出成千上万这种域训练的模型,这张图展示的部分域训练模型,后面这张图的每个点都是一次实验,如果是好的实验,我们就会放在一个网站上供其他算法工程师使用,我们希望通过一套时间管理的平台去帮他们去整理整个时间思路,以及整个实验的循环关系。
有了前面的这些 Face Model, IaaS 层资源,还有数据、时间管理,剩下的就要发挥各个算法工程师的想象力了,大家每天都会去读各种 Paper,去想各种复杂精要的这种网络设计的方案,从而创造出性能非常好的网络模型。所以工业化的 AI 生产现在已经是团体作战了,我们会有各种的体系支持,大家去这些已有资源上面去创作,生成一套完整的 AI 体系。
(文章题图来自于pixabay)
AI公开课预告
时间:6月7日 20:00-21:00
扫描海报二维码,免费报名
添加小助手微信csdnai,加入课程交流群
