keras实战-入门之手写数字识别DNN
keras实战-入门之手写数字识别DNN
- 手写数字识别
手写数字识别
属于hello world级别的练习,就不多说了
import numpy as np
np.random.seed(11)
from keras.datasets import mnist
from keras.utils import np_utils
Using TensorFlow backend.
from keras.models import Sequential
from keras.layers import Dense
#加载数据集
(x_train_image,y_train_label),(x_test_image,y_test_label)=mnist.load_data()
print('train data=',len(x_train_image))
print('test data=',len(x_test_image))
train data= 60000
test data= 10000
print('y_train_label',x_train_image.shape)
print('y_train_label',y_train_label.shape)
y_train_label (60000, 28, 28)
y_train_label (60000,)
#看看字体图片
import matplotlib.pyplot as plt
def show_image(image):
fig=plt.figure(figsize=(4,4))
plt.imshow(image,cmap='binary')
plt.show()
show_image(x_train_image[0])

y_train_label[0]
5
#处理数据,把他展平了
x_train=x_train_image.reshape(60000,-1).astype('float32')
x_test=x_test_image.reshape(10000,-1).astype('float32')
print(x_train.shape)
print(x_test.shape)
(60000, 784)
(10000, 784)
#归一化数据
x_train_normalize=x_train/255
x_test_normalize=x_test/255
#one hot编码
y_train_oneHot=np_utils.to_categorical(y_train_label)
y_test_oneHot=np_utils.to_categorical(y_test_label)
y_train_oneHot[:3]
array([[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.]])
#用了最简单的一层,当然也可以有其他优化
model=Sequential()
model.add(Dense(units=256,input_dim=784,kernel_initializer='normal',activation='relu'))
model.add(Dense(units=10,kernel_initializer='normal',activation='softmax'))
WARNING:tensorflow:From F:\Anaconda3\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
#看看结构
print(model.summary())
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 256) 200960
_________________________________________________________________
dense_2 (Dense) (None, 10) 2570
=================================================================
Total params: 203,530
Trainable params: 203,530
Non-trainable params: 0
_________________________________________________________________
None
#编译模型,交叉熵,优化器SGD,要看准确率
model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
train_history=model.fit(x_train_normalize,y_train_oneHot,validation_split=0.2,epochs=10,batch_size=256,verbose=2)
WARNING:tensorflow:From F:\Anaconda3\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 3s - loss: 1.9122 - acc: 0.5346 - val_loss: 1.4928 - val_acc: 0.7507
Epoch 2/10
- 1s - loss: 1.1975 - acc: 0.7794 - val_loss: 0.9231 - val_acc: 0.8319
Epoch 3/10
- 1s - loss: 0.8179 - acc: 0.8295 - val_loss: 0.6780 - val_acc: 0.8607
Epoch 4/10
- 1s - loss: 0.6491 - acc: 0.8529 - val_loss: 0.5606 - val_acc: 0.8740
Epoch 5/10
- 1s - loss: 0.5596 - acc: 0.8658 - val_loss: 0.4939 - val_acc: 0.8831
Epoch 6/10
- 1s - loss: 0.5045 - acc: 0.8728 - val_loss: 0.4505 - val_acc: 0.8888
Epoch 7/10
- 1s - loss: 0.4668 - acc: 0.8796 - val_loss: 0.4207 - val_acc: 0.8937
Epoch 8/10
- 1s - loss: 0.4395 - acc: 0.8845 - val_loss: 0.3986 - val_acc: 0.8976
Epoch 9/10
- 1s - loss: 0.4184 - acc: 0.8885 - val_loss: 0.3815 - val_acc: 0.8993
Epoch 10/10
- 1s - loss: 0.4016 - acc: 0.8919 - val_loss: 0.3680 - val_acc: 0.9029
loss, accuracy = model.evaluate(x_test_normalize, y_test_oneHot)
print('test loss: ', loss)
print('test accuracy: ', accuracy)
10000/10000 [==============================] - 1s 63us/step
test loss: 0.3700620859503746
test accuracy: 0.9006
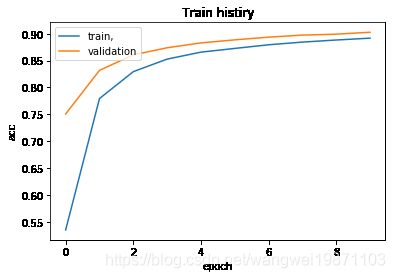
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train histiry')
plt.ylabel(train)
plt.xlabel('epoch')
plt.legend(['train,','validation'],loc='upper left')
plt.show()
#查看准确率曲线,是否过拟合
show_train_history(train_history,'acc','val_acc')
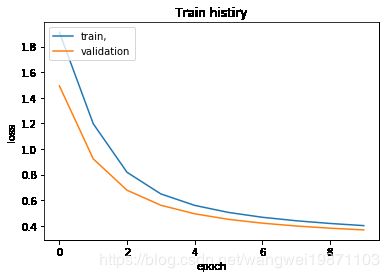
#loss也可以看到
show_train_history(train_history,'loss','val_loss')
def show_images_labels_prediction(images,labels,prediction,idx,num=10):
flig=plt.figure(figsize=(12,14))
if num>25:
num=25
for i in range(0,num):
ax=plt.subplot(5,5,1+i)
ax.imshow(images[idx],cmap='binary')
title='labels='+str(labels[idx])
if len(prediction)>0:
title+=',predict='+str(prediction[idx])
ax.set_title(title,fontsize=10)
ax.set_xticks([])
ax.set_yticks([])
idx+=1
plt.show()
#看下具体训练集和标签
show_images_labels_prediction(x_train_image,y_train_label,[],0,10)
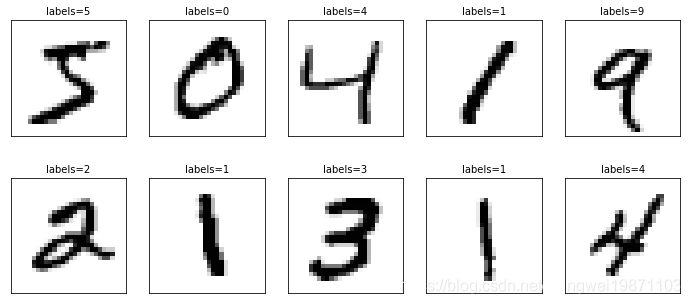
#进行类别预测
prediction=model.predict_classes(x_test_normalize)
prediction
array([7, 2, 1, ..., 4, 5, 6], dtype=int64)
show_images_labels_prediction(x_test_image,y_test_label,prediction,idx=340)

#可以查看预测和标签混淆矩阵,来观察哪些预测有问题,对角线是预测对的,其他就是预测错的
#混淆矩阵
import pandas as pd
pd.crosstab(y_test_label,prediction,rownames=['label'],colnames=['predict'])
| predict | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| label | ||||||||||
| 0 | 952 | 0 | 4 | 2 | 0 | 4 | 12 | 1 | 5 | 0 |
| 1 | 0 | 1108 | 2 | 3 | 1 | 2 | 4 | 1 | 14 | 0 |
| 2 | 12 | 7 | 892 | 17 | 17 | 2 | 21 | 21 | 37 | 6 |
| 3 | 6 | 1 | 18 | 893 | 1 | 41 | 3 | 16 | 22 | 9 |
| 4 | 2 | 3 | 5 | 0 | 901 | 1 | 15 | 2 | 11 | 42 |
| 5 | 15 | 4 | 5 | 48 | 9 | 739 | 17 | 8 | 41 | 6 |
| 6 | 17 | 3 | 9 | 2 | 15 | 18 | 889 | 1 | 4 | 0 |
| 7 | 4 | 20 | 31 | 2 | 12 | 0 | 0 | 919 | 5 | 35 |
| 8 | 8 | 9 | 12 | 34 | 10 | 25 | 14 | 12 | 836 | 14 |
| 9 | 13 | 9 | 7 | 11 | 50 | 14 | 0 | 20 | 8 | 877 |
#上图可以看到5被识别为3的有48个,那我们把他们找几个出来看看
df=pd.DataFrame({'label':y_test_label,'predict':prediction})
data=df[(df.label==5)&(df.predict==3)]
data[0:5]
| label | predict | |
|---|---|---|
| 261 | 5 | 3 |
| 340 | 5 | 3 |
| 502 | 5 | 3 |
| 857 | 5 | 3 |
| 1082 | 5 | 3 |
#显示几个看看
for i in data[0:5].index:
show_images_labels_prediction(x_test_image,y_test_label,prediction,idx=i,num=1)

#上面貌似5的准确率还是有待提高,再来看看2预测成1的吧
data=df[(df.label==2)&(df.predict==1)]
data
| label | predict | |
|---|---|---|
| 536 | 2 | 1 |
| 1409 | 2 | 1 |
| 2269 | 2 | 1 |
| 2433 | 2 | 1 |
| 3946 | 2 | 1 |
| 4812 | 2 | 1 |
| 9168 | 2 | 1 |
#显示几个看看
for i in data[0:5].index:
show_images_labels_prediction(x_test_image,y_test_label,prediction,idx=i,num=1)

可见全连接神经网络识别还是有问题,后面用CNN应该会比较好
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,侵删。