我把代码和爬好的数据放在了git上,欢迎大家来参考
https://github.com/linyi0604/linyiSearcher
我是在 manjaro linux下做的, 使用python3 语言, 爬虫部分涉及到 安装ChromeDriver 可以参考我之前写的博文。
建立索引部分参考: https://baijiahao.baidu.com/s?id=1597426056496128414&wfr=spider&for=pc
检索过程,衡量文档相似度使用了余弦相似度,参考:https://www.cnblogs.com/liangjf/p/8283519.html
为了完成我的信息检索选修课大作业,写下了这个简单的小项目。
这里是一个python3 实现的简易的搜索引擎
我把它取名叫linyiSearcher
--------
所需要的python依赖包在requirements.txt中
可以使用 pip install -r requirements.txt 一次性安装全部
--------
一共分成3部分完成(后面有稍微详细点的解读)
1_spider.py 是一个爬虫, 爬取搜索引擎的语料库
2_clean_data_and_make_index 是对爬下来的数据 进行一些清晰工作,并且将数据存入数据库,建立索引
这里使用了 sqlite数据库,为了方便数据和项目一同携带
3_searcher.py 简易的web后端, 实现了
1 在网页输入搜索关键字, 在后端接收到关键字
2 对关键字进行分词
3 在索引中查找和关键字有关的文档
4 按照余弦相似度 对文档进行排序
5 把相近的文档展示出来
--------
自己的知识储备和代码能力都捉襟见肘。
大神来看,还望海涵~欢迎大家批评指正共同学习
--------
1 爬虫:
因为没有数据,只能写爬虫来做, 又只有自己的笔记本来跑,所以数据量也做不到非常大
在这里 写了1程序 爬了百度贴吧 娱乐明星分类下面的所有1级页面帖子的标题 当做语料库
爬取下来的数据存在了 ./data/database.csv 下
数据有2列 分别是 title 和url
2 数据清洗 并 建立索引:
database.db 是一个sqlite数据库文件
首先将每个文档存到了数据库当中
数据库表为 page_info(id,keyword, title, url)
id 自增主键
keyword: 存了该文档文字用jieba分词打散后的词汇列表(用空格隔开所有词语的字符串)
title: 文档的文字内容
url: 该文档的网页链接
然后 把每个文档 使用jieba分词工具, 打散成词语,把所有词语放到一个集合中(集合能去重)
把所有词 存入数据库 建立索引
索引这样理解:
关键词: 你好 包含关键词的文档: <1,2,6,8,9>
表为 page_index(id, word, page_id)
id: 自增 主键
word: 当前关键词
page_id: 包含该关键词的文档id 也就是page_info.id
3 实现检索:
首先 使用了bottle框架,是一个非常轻巧的web后端框架,实现了一个简单的web后端
前端页面使用了bootstrap 的css样式,,毕竟自己什么垃圾的一p
检索的实现过程:
1 后端拿到检索的关键词,用jieba分词 把拿到的语句打散成词汇 形成关键词keyword_list
2 在建立的索引表page_index中,搜关keyword_list中出现的词汇的page_id
3 在包含所有keyword的文档上 计算和keyword的余弦相似度,然后降序排列
4 返回给前端显示搜索结果
看看检索结果:
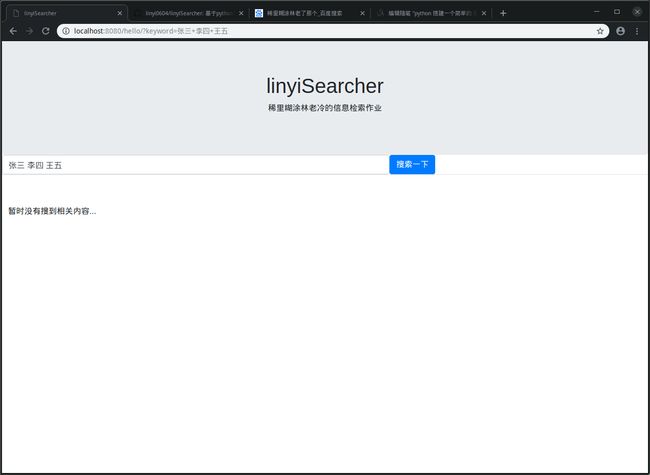
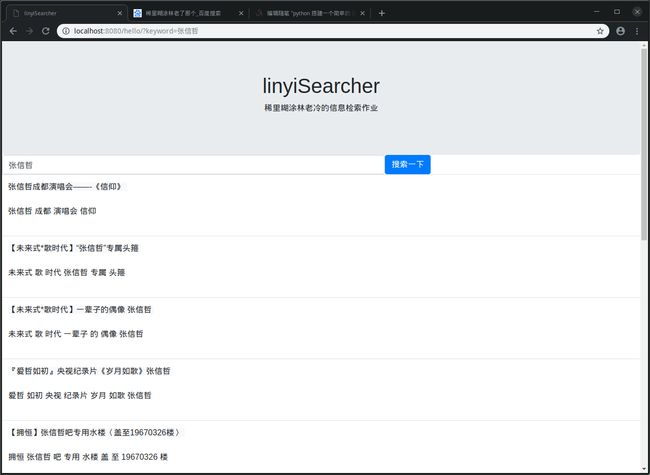
1_spider.py 爬虫的代码
1 import requests
2 from lxml import etree
3 import random
4 import COMMON
5 import os
6 from selenium import webdriver
7 import pandas as pd
8 """
9 这里是建立搜索引擎的第一步
10 """
11
12
13 class Spider_BaiduTieba(object):
14
15 def __init__(self):
16 self.start_url = "/f/index/forumpark?pcn=娱乐明星&pci=0&ct=1&rn=20&pn=1"
17 self.base_url = "http://tieba.baidu.com"
18 self.headers = COMMON.HEADERS
19 self.driver = webdriver.Chrome()
20 self.urlset = set()
21 self.titleset = set()
22
23 def get(self, url):
24 header = random.choice(self.headers)
25 response = requests.get(url=url, headers=header, timeout=10)
26 return response.content
27
28 def parse_url(self, url):
29 """通过url 拿到xpath对象"""
30 print(url)
31 header = random.choice(self.headers)
32 response = requests.get(url=url, headers=header, timeout=10)
33 # 如果获取的状态码不是200 则抛出异常
34 assert response.status_code == 200
35 xhtml = etree.HTML(response.content)
36 return xhtml
37
38 def get_base_url_list(self):
39 """获得第一层url列表"""
40 if os.path.exists(COMMON.BASE_URL_LIST_FILE):
41 li = self.read_base_url_list()
42 return li
43 next_page = [self.start_url]
44 url_list = []
45 while next_page:
46 next_page = next_page[0]
47 xhtml = self.parse_url(self.base_url + next_page)
48 tmp_list = xhtml.xpath('//div[@id="ba_list"]/div/a/@href')
49 url_list += tmp_list
50 next_page = xhtml.xpath('//div[@class="pagination"]/a[@class="next"]/@href')
51 print(next_page)
52 self.save_base_url_list(url_list)
53 return url_list
54
55 def save_base_url_list(self, base_url_list):
56 with open(COMMON.BASE_URL_LIST_FILE, "w") as f:
57 for u in base_url_list:
58 f.write(self.base_url + u + "\n")
59
60 def read_base_url_list(self):
61 with open(COMMON.BASE_URL_LIST_FILE, "r") as f:
62 line = f.readlines()
63 li = [s.strip() for s in line]
64 return li
65
66 def driver_get(self, url):
67 try:
68 self.driver.set_script_timeout(5)
69 self.driver.get(url)
70 except:
71 self.driver_get(url)
72 def run(self):
73 """爬虫程序入口"""
74 # 爬取根网页地址
75 base_url_list = self.get_base_url_list()
76 data_list = []
77 for url in base_url_list:
78 self.driver_get(url)
79 html = self.driver.page_source
80 xhtml = etree.HTML(html)
81 a_list = xhtml.xpath('//ul[@id="thread_list"]//a[@rel="noreferrer"]')
82 for a in a_list:
83 title = a.xpath(".//@title")
84 url = a.xpath(".//@href")
85 if not url or not title or title[0]=="点击隐藏本贴":
86 continue
87 url = self.base_url + url[0]
88 title = title[0]
89
90 if url in self.urlset:
91 continue
92
93 data_list.append([title, url])
94 self.urlset.add(url)
95 data = pd.DataFrame(data_list, columns=["title,", "url"])
96 data.to_csv("./data/database.csv")
97
98
99
100
101 if __name__ == '__main__':
102 s = Spider_BaiduTieba()
103 s.run()
2 清晰数据 和 建立索引部分代码 这里是notebook 完成的, 所以看起来有点奇怪
1 #%%
2 import pandas as pd
3 import sqlite3
4 import jieba
5 #%%
6 data = pd.read_csv("./data/database.csv")
7 #%%
8 def check_contain_chinese(check_str):
9 for ch in check_str:
10 if u'\u4e00' <= ch <= u'\u9fff':
11 return True
12 if "a" <= ch <= "z" or "A" <= ch <= "X":
13 return True
14 if "0" <= ch <= "9":
15 return True
16 return False
17 #%%
18 data2 = []
19 for d in data.itertuples():
20 title = d[1]
21 url = d[2]
22 cut = jieba.cut(title)
23 keyword = ""
24 for c in cut:
25 if check_contain_chinese(c):
26 keyword += " " + c
27 keyword = keyword.strip()
28 data2.append([title, keyword, url])
29 #%%
30 data3 = pd.DataFrame(data2, columns=["title", "keyword", "url"])
31 data3
32 #%%
33 data3.to_csv("./data/cleaned_database.csv", index=False)
34 #%%
35 for line in data3.itertuples():
36 title, keyword, url = line[1],line[2],line[3]
37 print(title)
38 print(keyword)
39 print(url)
40 break
41
42 #%%
43 conn = sqlite3.connect("./data/database.db")
44 c = conn.cursor()
45
46 # 创建数据库
47 sql = "drop table page_info;"
48 c.execute(sql)
49 conn.commit()
50
51 sql = """
52 create table page_info(
53 id INTEGER PRIMARY KEY,
54 keyword text not null,
55 url text not null
56 );
57 """
58 c.execute(sql)
59 conn.commit()
60
61
62 # 创建索引表
63 sql = """
64 create table page_index(
65 id INTEGER PRIMARY KEY,
66 keyword text not null,
67 page_id INTEGER not null
68 );
69 """
70 c.execute(sql)
71 conn.commit()
72 #%%
73 sql = "delete from page_info;"
74 c.execute(sql)
75 conn.commit()
76
77
78 # 插入到数据库
79 i = 0
80 for line in data3.itertuples():
81 title, keyword, url = line[1],line[2],line[3]
82 sql = """
83 insert into page_info (url, keyword)
84 values('%s', '%s')
85 """ % (url, keyword)
86 c.execute(sql)
87 conn.commit()
88 i += 1
89 if i % 50 == 0:
90 print(i, len(data3))
91
92
93
94 sql = "delete from page_index;"
95 c.execute(sql)
96 conn.commit()
97
98 sql = "select * from page_info;"
99 res = c.execute(sql)
100 res = list(res)
101 length = len(res)
102
103 i = 0
104 for line in res:
105 pid, words, url = line[0], line[1], line[2]
106 words = words.split(" ")
107 for w in words:
108 sql = """
109 insert into page_index (keyword, page_id)
110 values('%s', '%s')
111 """ % (w, pid)
112 c.execute(sql)
113 conn.commit()
114 i += 1
115 if i % 100 == 0:
116 print(i, length)
117 #%%
118
119 #%%
120
121
122 #%%
123 titles = list(words)
124 colums = ["title", "url"] + titles
125 word_vector = pd.DataFrame(columns=colums)
126 word_vector
127 #%%
128
129 #%%
130 data = pd.read_csv("./data/database.csv")
131 #%%
132 data
133 #%%
134 sql = "alter table page_info add title text;"
135 conn = sqlite3.connect("./data/database.db")
136 c = conn.cursor()
137 c.execute(sql)
138 conn.commit()
139 #%%
140 conn = sqlite3.connect("./data/database.db")
141 c = conn.cursor()
142 length = len(data)
143 i = 0
144 for line in data.itertuples():
145 pid = line[0]+1
146 title = line[1]
147 sql = "UPDATE page_info SET title = '%s' WHERE id = %s "%(title,pid)
148 try:
149 c.execute(sql)
150 conn.commit()
151 except:
152 continue
153 i += 1
154 if i % 50 == 0:
155 print(i, length)
156
157
158 #%%
159
160 #%%
3 web后端 完成检索功能代码
1 # coding=utf-8
2 import jieba
3 import sqlite3
4 from bottle import route, run, template, request, static_file, redirect
5
6
7 @route('/static/