安全容器在边缘计算场景下的实践
**导读:**随着云计算边界不断向边缘侧延展,传统 RunC 容器已无法满足用户对不可信、异构工作负载的运行安全诉求,边缘 Serverless、边缘服务网格等更是对容器安全隔离提出了严苛的要求。本文将介绍边缘计算场景如何构建安全运行时技术基座,以及安全容器在架构、网络、监控、日志、存储、以及 K8s API 兼容等方面的遇到的困难挑战和最佳实践。
正文:
本文主要分为四个部分,首先前两个部分会分别介绍一下ACK安全沙箱容器和边缘容器(Edge Kubernetes),这两个方向内容目前大部分人接触并不是很多。第三部着重分享安全沙箱容器在边缘这边的解决方案与实践经验,最后会介绍一下我们在安全容器方向新的探索和实践-可信/机密计算。
安全容器运行时
据 Gartner 预测,2019 年一半以上的企业会在其开发和生产环境中使用容器部署应用,容器技术日趋成熟稳定,然而在未容器化的企业或用户中,42% 以上的受访者表示容器安全成为其容器化的最大障碍之一,主要包括容器运行时安全、镜像安全和数据安全加密等。
端到端的云原生安全架构

在讲安全沙箱容器之前简单介绍下端到端云原生安全架构,主要分为三部分:
1.基础架构安全
基础架构安全依赖于云厂商或者是专有云一些基础设施安全能力,也包括 RAM认证,细粒度RAM授权,支持审计能力等等。
2.安全软件供应链
这部分包括镜像签名,镜像扫描,安全合规等等,甚至包括有一些静态加密BYOK,DevSecOps,安全分发等。
3.容器运行时的安全
这部分包括安全沙箱隔离,还包括了容器运行时其它方面一些安全机制,如KMS(秘钥管理服务)集成、多租户的管理和隔离等等。
安全容器运行时对比

接下来分享下业界在安全容器运行时的一些方案对比,业界安全容器运行时分为四大类:
- OS容器+安全机制
主要原理是在传统 OS 容器之上增加一些辅助安全辅助手段来增加安全性,如SELinux、AppArmor、Seccomp等,还有docker 19.03+可以让Docker运行在 Rootless 的模式之下,其实这些都是通过辅助的工具手段来增强OS容器的安全性,但依然没有解决容器与Host共享内核利用内核漏洞逃逸带来的安全隐患问题;而且这些安全访问控制工具对管理员认知和技能要求比较高,安全性也相对最差。
- 用户态内核
此类典型代表是 Google 的 gVisor,通过实现独立的用户态内核去补获和代理应用的所有系统调用,隔离非安全的系统调用,间接性达到安全目的,它是一种进程虚拟化增强。但系统调用的代理和过滤的这种机制,导致它的应用兼容性以及系统调用方面性能相对传统OS容器较差。由于并不支持 virt-io 等虚拟框架,扩展性较差,不支持设备热插拔。
- LibraryOS
基于 LibOS 技术的这种安全容器运行时,比较有代表 UniKernel、Nabla-Containers,LibOS技术本质是针对应用对内核的一个深度裁剪和定制,需要把 LibOS 与应用编译打包在一起。因为需要打包拼在一起,本身兼容性比较差,应用和 LibOS 的捆绑编译和部署为传统的 DevOPS 带来挑战。
- MicroVM
我们知道业界虚拟化(机)本身已经非常的成熟,MicroVM轻量虚拟化技术是对传统虚拟化的裁剪和,比较有代表性的就是 Kata-Containers、Firecracker,扩展能力非常优秀。VM GuestOS 包括内核均可自由定制,由于具备完整的OS和内核它的应用兼容性及其优秀;独立内核的好处是即便出现安全漏洞问题也会把安全影响范围限制到一个 VM 里面,当然它也有自己的缺点,Overhead 可能会略大一点,启动速度相对较慢一点。
完全杜绝安全问题的发生-不可能!
Linus Torvalds 曾在 2015年的 LinuxCon 上说过 "The only real solution to security is to admit that bugs happen, and then mitigate them by having multiple layers.” ,我们无法杜绝安全问题,软件总会有 Bug、Kernel 总会有漏洞,我们需要去面对这些现实问题,既然无法杜绝那我们需要就给它(应用)加上隔离层(沙箱)。
安全容器运行时选择
用户选择安全容器运行时需要考虑三方面:安全隔离、通用性以及资源效率。
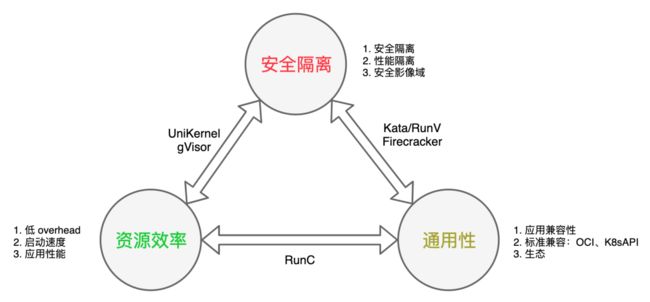
- 安全隔离
主要包括安全隔离和性能隔离。安全隔离主要是安全问题影响的范围,性能隔离主要是降低容器间的相互干扰和影响。
- 通用性
通用性,首先是应用兼容性,应用是否可以在不修改或者小量修改的前提下运行在上面;其次是标准性兼容,包括 OCI 兼容、K8sAPI 兼容等;最后“生态”保证它可持续性和健壮性。
- 资源效率
资源效率讲究更低 Overhead,更快的启动速度,更好的应用性能。
总结
其实目前没有任何一种容器运行时技术可以同时满足以上三点,而我们需要做的就是根据具体的场景和业务需求合理选择适合自己的容器运行时。
在「资源效率」和「通用性」做的比较好的是传统的OS容器、runC等,但安全性最差;在「资源效率」和「安全隔离」做的比较好的是 UniKernel、gVisor 等,但应用兼容和通用性较差;在「安全隔离」和「通用性」方面做的比较的是 Kata-containers、Firecracker等,但 overhead 开销稍大启动速度稍慢,应用性能也相对传统OS容器较差。
ACK安全沙箱容器
我们阿里云容器服务 ACK 产品基于 Alibaba Cloud Sandbox 技术在 2019 年 09 月份推出了安全沙箱容器运行时的支持,它是在原有Docker容器之外提供的一种全新的容器运行时选项,它可以让应用运行在一个轻量虚拟机沙箱环境中,拥有独立的内核,具备更好的安全隔离能力,特别适合于多租户间负载隔离、对不可信应用隔离等场景。它在提升安全性的同时,对性能影响非常小,并且具备与Docker容器一样的用户体验,如日志、监控、弹性等。
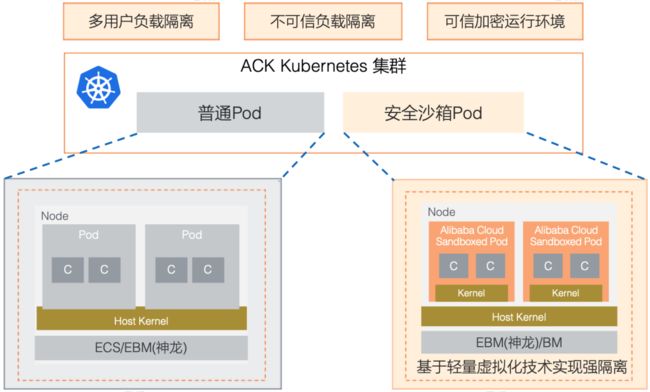
对于我们场景来说,「安全性」和「通用性」是无疑最重要的,当然性能和效率我们也做了大量的优化:
- 轻量虚拟机沙箱;
- 独立 kernel,强隔离,安全故障域影响最小;
- 兼容 OCI 标准,几乎兼容所有 K8s API;
- 约 25 MB 的极低 Overhead 开销;
- 500ms 极速启动,拥有原生传统OS容器约 90% 的优秀性能;
- 适合多租负载隔离、不可信三方应用隔离、多方计算、Serverless 等场景。
ACK边缘容器(ACK@Edge)
随着万物互联时代的到来,智慧城市、智能制造、智能交通、智能家居,5G时代、宽带提速、IPv6的不断普及,导致数百亿的设备接入网络,在网络边缘产生ZB级数据,传统云计算难以满足物联网时代大带宽、低时延、大连接的诉求,边缘云计算便应运而生。
边缘计算设施服务越来越难以满足边端日益膨胀的诉求,因而云上服务下沉,边缘 Serverless、边缘侧隔离不可信负载等日趋强烈…
所以,为了满足我们边缘云计算场景需求,我们 ACK 推出了 Kubernetes 边缘版。
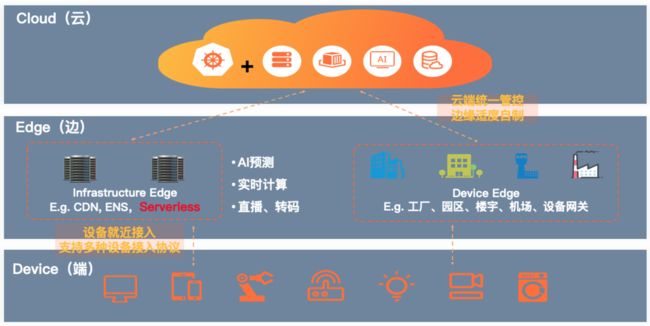
先来看下典型的边缘云模型,它由云(侧)、边(侧)、端(侧)三部分共同组成,三者相互协同,并提供统一的交付、运维和管控标准。云侧统一管控,是整个模型的中枢大脑;边侧由一定计算/存储能力的节点组成,是距离设备和用户最近的计算/存储资源;亿万端侧设备就近计入“边缘节点”。
“边”又分为两大类;一个是工业级的边,这类比较典型代表是云厂商提供的 CDN 节点计算资源、服务或者 Serverless 等,工业级的边也可提供 AI 预测、实时计算、转码等服务能力,把云上的服务下沉到边侧。第二类是用户或者工厂、园区、楼宇、机场等自己提供计算资源服务器或者网关服务器,如一个家庭网关可以作为边缘节点接入到集群中从而可以纳管控制家庭中的智能电器设备。
那边缘 Serverless 如何解决多租户负载隔离?工程如何在自己的内网环境安全运行三方提供的应用服务和负载?这也就是我们在边缘侧引入安全沙箱容器的根本原因。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sg2UDTXV-1576138892897)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zT01I1Cj-1576138892897)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw== “点击并拖拽以移动”)]
解决方案
整体方案
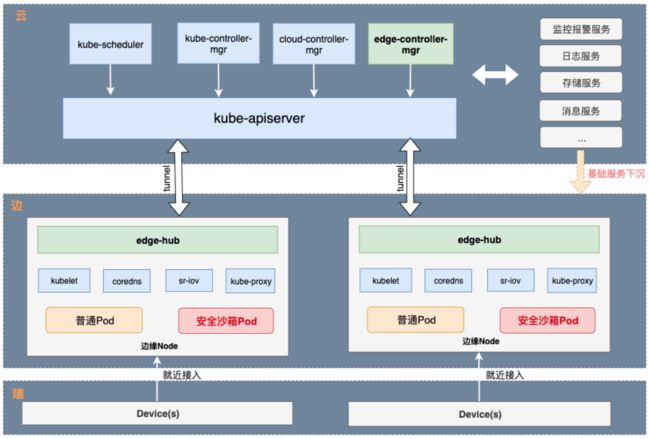
先看下整体解决方案,上面架构完全契合了“云-边-端”模型,我们整个架构是基于 Kubernetes 来开发的。
“云侧”,既“管控端”,提供了整个 K8s 集群的统一管控,托管了 K8s 集群“四大件(master组件)”:kube-apiserver、kube-controller-manager、kube-scheduler以及 cloud-controller-manager,同时我们在“云侧为”增加了 AdminNode 节点用户部署 Addons 组件,如 metrics-server、log-controller 等非核心功能组件;当然,“云侧”也会适配云上的各类服务为自己附能,如监控服务、日志服务、存储服务等等。
“边侧”,既边缘Node节点,我们知道“云侧”到“边侧”的弱网会导致边缘Node失联,失联时间过长会导致 Master 对节点上的 Pod 发出驱逐指令,还有断网期间“边缘节点”主机重启后应用如何恢复和自治,这些都是 Edge Kubernetes 面临的最大挑战之一;当在 K8s 引入安全沙箱容器运行时,会发现 K8s Api 不兼容、部分监控异常、日志无法正常采集、存储性能极差等诸多问题,都给我们带来了极大的挑战。
在分享解决以上问题前,我们先看下云侧安全沙箱容器方案。

上图橙色虚框内是节点运行时的组件分层结构,上面是 kubelet,CRI-Runtime 有 Docker 和 Containerd 两类,其中安全沙箱容器运行时方案(深蓝色背景部分)中我们选择了 Containerd 作为 CRI-Runtime,主要考虑到 Containerd 的结构简洁,调用链更短,资源开销更小,而且它具有及其灵活的多 Runtimes 支持,扩展能力也更优。
我们在一个“安全沙箱节点”上同时提供了 RunC 和 RunV 两种运行时的支持,同时在 K8s 集群中对应的注入了两个 RuntimeClass( runc 和 runv )以便轻松轻易按需调度和选择,“同时提供 RunC 支持” 也是考虑到诸如 kube-proxy 等 Addon 组件没必要运行在安全沙箱中。
OS 我们选择了阿里云的发行版 OS:Aliyun Linux,4.19+ 的 Kernel 对容器的兼容性更优、稳定性更好,同时我们对其进行了极少的定制,以便支持硬件虚拟化。
最下面运行就是我们的裸金属服务器,在云上我们提供了神龙,在边缘侧任何支持硬件虚拟化的裸金属服务器均可。
边缘接节点治理
问题
- K8s 管控端与边缘节点断网维护,如工厂封网内部设备维护等,超过 Pod 容忍时间(默认300s)后会导致管控端发出“驱逐失联节点上所有 Pods”指令,在维护结束网络恢复后,边缘节点收到驱逐指令删除所有应用 Pod,这对于一个工厂来说是灾难性的。
- 在封(断)网期间边缘节点硬件重启,就会导致节点上依赖管控端(如 kube-apiserver)的部分组件或数据无法正常启动或载入。
常见社区方案
社区方案一:

主要原理是基于 kubelet checkpoint 机制把一些资源对象缓冲到本地文件,但 kubelet checkpoint 能力较弱,仅可以魂村 pod 等个别类型对象到本地文件,像常用的 ConfigMap/Secret/PV/PVC 等暂不支持。当然也可以定制修改 kubelet,但后期会带来的大量的升级和维护成本。
社区方案二:

利用集群联邦,把整个 K8s 集群下沉到边缘侧,如每个 EdgeUnit 存在一个或多个 K8s 集群,通过云侧的 K8s Federation 进行多集群/负载管理。但因为 EdgeUnit 分散性且规模较大庞大,会导致集群规模数倍增加,产生大量的 Overhead 成本,很多 EdgeUnit 内通常仅有几台机器。而且这种架构也比较复杂,难以运维,同时,边缘K8s集群也很难复用云上成熟服务,如监控、日志等。
我们的方案
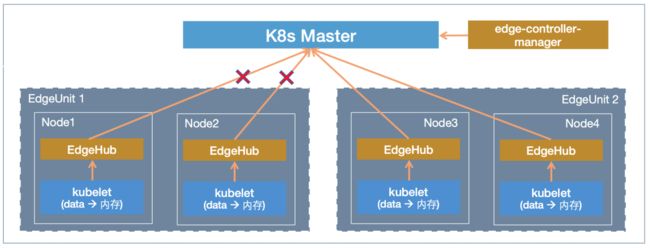
如上图,在我们的边缘治理方案中,我们增加了两个非常重要的组件:
-
ECM(edge-controller-manager):节点自治管理,忽略自治模式节点上的 Pod 驱逐等。
- 基于 node-lifecycle-controller;
- 通过 Annotation 配置开关,表示节点是否开启自治模式;
- 对于自治模式的节点,当节点失联(NotReady等)时忽略对节点上容忍超时的 Pod 驱逐。
-
EdgeHub:边缘节点代理
- 作为 kubelet 和 apiserver 之间的缓存和代理;
- 在网络正常情况下,EdgeHub直接代理转发 Kubelet 请求到 apiserver,并缓存结果到本地;
- 在节点断网的情况下,EdgeHub 利用本地缓存充当 apiserver,但 EdgeHub并未真正的 apiserver,所以须忽略所有过来的写操作请求。
监控方案

上图为整个监控的原理图,流程是:
-
metrics-server 定期主动向所有节点 kubelet 请求监控数据;
-
kubelet 通过 CRI 接口向 containerd 请求监控数据;
-
containerd 通过 Shim API 向所有容器 shim 请求容器的监控数据;
- Shim API 目前有两个版本 v1 和 v2。
- containerd-shim-kata-v2 通过虚拟串口向 VM GuestOS(POD) 内的 kata-agent 请求监控数据,kata-agent 采集 GuestOS 内的容器监控数据并响应。
- 我们 runC shim 用的是 containerd-shim,这个版本虽然比较老,但稳定性非常好,经过大量的生产验证。
-
metrics-server 把监控数据除了 Sink 到云监控上外,自己内存中还存放了最近一段时间的监控数据,用于提供给 K8s Metrics API,这些数据可用于 HPA 等。
我们遇到的问题是 CRI ContainerStats 接口提供的监控指标非常少,缺失了 Network、Block IO等非常重要的API,并且已有的 CPU 和 Memory 的数据项也及其少。
// ContainerStats provides the resource usage statistics for a container.
message ContainerStats {
// Information of the container.
ContainerAttributes attributes = 1;
// CPU usage gathered from the container.
CpuUsage cpu = 2;
// Memory usage gathered from the container.
MemoryUsage memory = 3;
// Usage of the writeable layer.
FilesystemUsage writable_layer = 4;
}
// CpuUsage provides the CPU usage information.
message CpuUsage {
// Timestamp in nanoseconds at which the information were collected. Must be > 0.
int64 timestamp = 1;
// Cumulative CPU usage (sum across all cores) since object creation.
UInt64Value usage_core_nano_seconds = 2;
}
// MemoryUsage provides the memory usage information.
message MemoryUsage {
// Timestamp in nanoseconds at which the information were collected. Must be > 0.
int64 timestamp = 1;
// The amount of working set memory in bytes.
UInt64Value working_set_bytes = 2;
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2rbbfSfU-1576138892900)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RU8nMh8s-1576138892900)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw== “点击并拖拽以移动”)]
那如何补齐监控API?由于我们有着庞大的存量集群,我们的改动既不能影响已有的用户监控,也不能对整个监控设施方案做大的改动,所以改动尽量在靠近底层的地方做适配和修改,我们最终决定定制 kubelet,这样整个监控基础设施不需要做任何变更。
下面是 kubelet 具体修改的原理图:

kubelet 的监控接口分为三大类:
-
summary 类,社区后面主推接口,有Pod语义,既可以适配 CRI Runtime 也可以兼容 Docker。
- /stats/summary。
-
default 类,较老的接口,无Pod语义,社区会逐渐废弃此类接口。
- /stats
- /stats/container
- /stats/{podName}/{containerName}
- /stats/{namespace}/{podName}/{uid}/{containerName}
-
prometheus类,prometheus格式的接口,实际上后端实现复用了 default 类的方法。
- /metrics
- /metrics/cadvisor
为了更好的兼容,我们对三类接口均进行了适配。上图红色部分为新增,黄色虚框部分为修改。
- summary 类
新增为 containerd 专门实现了接口 containerStatsProvider :containerdStatsProvider,因 kubelet 通过 CRI 连接 containerd,故 containerdStatsProvider 在实现上复用了 criStatsProvider, 同时增加了 Network、Block IO 等。
- default 类和 prometheus 类
在入口处增加判断分支,若为 containerd 则直接通过 contaienrdStatsProvider 拿数据。
实际上,只修改 kubelet 还不够,我们发现 containerd 后端返回的监控数据也没有 Network、Block IO等,所以我们推动了社区在 containerd/cgroups 扩展补齐了API。
日志方案

上图是我们的日志方案,我们需要通过阿里云日志采集 Agent Logtail 采集容器日志,主要有三种使用方式:
-
DaemonSet 部署的 Logtail
- 采集节点上所有容器的标准输出。
- 通过容器环境变量配置的容器内的采集日志路径,在宿主机上拼接容器的 rootfs 路径,可在宿主机上直采容器内日志文件。
-
Sidecar 部署的 Logtail
- 只采集同 Pod 内的其他应用容器日志文件。
我们在containerd/安全沙箱容器遇到的问题:
- Logtail 需要连接容器引擎获取主机上的所有容器信息,但只支持docker,不支持 containerd。
- 所有 runC 和 runV 容器标准输出无法采集。
- Logtail DaemonSet 模式无法直采 runC 和 runV 内。
解法:
- 支持 containerd,同时考虑到通用性,我们在实现上通过 CRI 接口而非 containerd SDK 直接连接 containerd,这样即便以后换了其他 CRI-Runtime,我们 Logtail 可以轻易直接支持。
- 通过 Container Spec 获取容器标准输出日志路径,由于如论 runC 还是 runV 容器的标准输出文件均在 Host 上,所以只要找到这个路径可以直接采集。
- 在 runC 的日志文件路径查找上,我们做了个优化:优先尝试查找 Upper Dir,否则查找 devicemapper 最佳匹配路径,由于 runV 有独立 kernel 无法在 Host 侧直采容器内日志文件。由于 runV 容器和 Host 内核不再共享,导致无法在 Host 上直接采集 runV 容器内的日志文件。
存储方案
安全沙箱容器存储方案涉及到两方面,分别是 RootFS 和 Volume。
- RootFS 可以简单的理解为容器的“系统盘”,每一个容器均有有一个 RootFS,目前主流的 RootFS 有 Overlay2、Devicemapper 等;
- Volume 可以简单的理解为容器的“数据盘”,可以为容器用来作为数据存储扩展。
RootFS
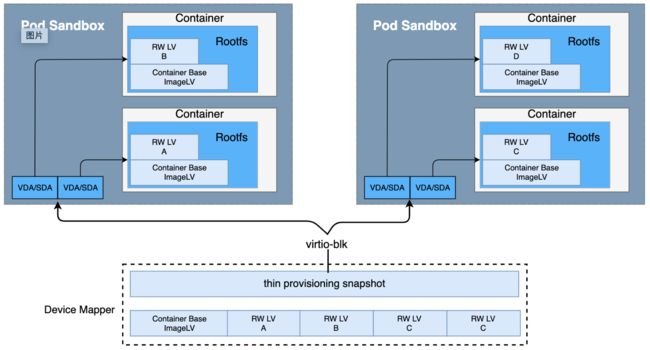
对于安全沙箱容器场景中容器 RootFS 我们并没有采用默认的 overlayfs,主要是因为 overlayfs 属于文件目录类,在 runC 把 rootfs 目录 mount bind 到容器内没有任何问题,但在 安全沙箱容器 kata 上直接 mount bind 到容器内会经过 kata 的 9pfs,会导致 block io 性能下降数十倍,所以 我们采⽤ devicemapper 构建了⾼速、稳定的容器 Graph Driver,由于 devicemapper 的底层基于 LVM,为每个容器分配的 dm 均为一个 block device,把这个设备放入容器内就可以避免了 kata 9pfs 的性能影响,这样就可以实现一个功能、性能指标全⾯对⻬ runC 场景的 RootFS。
优点/特点:
- 采用 devicemapper snapshot 机制,实现镜像分层存储;
- IOPS、Bandwidth 与 RunC overlayfs + ext4 基本持平;
- 基于 snapshot 增强开发,实现容器镜像计算和存储的分离。
Volume

在容器的存储上,我们采用了标准的社区存储插件 FlexVolume 和 CSI Plugin,在云上支持云盘、NAS 以及 OSS,在边缘我们支持了 LocalStorage。
FlexVolume 和 CSI Plugin 在实现上,默认均会将云盘、NAS 等先挂载到本地目录,然后 mount bind 到容器内,这在 runC 容器上并没有任何问题,但在安全沙箱容器中,由于过 9PFS 所以依然严重影响性能。
针对上面的性能问题,我们做了几方面的优化:
-
云上
-
NAS
- 优化 FlexVolume 和 CSI Plugin,针对沙箱(runV) Pod,把 mount bind 的动作下沉到沙箱 GuestOS 内,从而避开了 9PFS;而对 runC Pod 保持原有默认的行为。
-
云盘或本地盘
- 云盘或本地盘会在本地依然格式化,但不会 mount 到本地目录,而是直接把 block device 直通到沙箱中,由沙箱中的 agent 执行挂载动作。
-
-
边缘
- 在边缘侧,我们采用了 Virtio-fs 避开 9PFS 的问题,这种方式更通用,维护起来也更轻便,在性能上基本可以满足边缘侧的需求,当然无法和“云上直通”优化的性能好。
网络方案
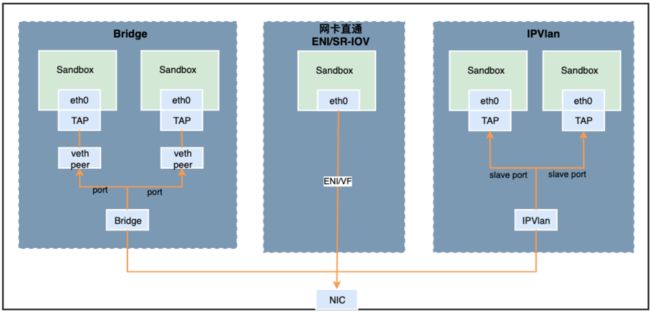
在网络方案中,我们同样既需要考虑“云上”和“边缘”,也需要考虑到“通用性”和“性能”,在 K8s 中还需要考虑到网络方案对 “容器网络” 和 “Service 网络” 的兼容性。
如上图,我们的网络方案中虽然有三种方案。
- Bridge 桥接模式
- 网卡直通模式
- IPVlan 模式
Birdge桥接模式
桥接模式属于比较老的也比较成熟的一种网络方案,它的优点就是通用性比较好,架构非常稳定和成熟,缺点是性能较差,特点是每个 Pod 都需要分配 Veth Pair,其中一端在 Host 测,一端在容器内,这样所有容器内的进出流量都会通过 Veth Pair 回到 Host,无需修改即可同时完美兼容 K8s 的容器网络和 Service 网络。目前这种方案主要应用于云上的节点。
网卡直通模式
顾名思义,就是直接把网卡设备直通到容器内。在云上和边缘由于基础网络设施方案不通,在直通方面略有不同,但原理是相同的。
- 云上,主要用来直通 ENI 弹性网卡到每个 Pod 内。
- 边缘,边缘网络方案基于 SR-IOV,所以主要用来直通 VF 设备。
直通方案的优点是,最优的网络性能,但受限于节点 ENI 网卡 或 VF 设备数量的限制,一般一台裸金属服务商只能直通 二三十个 Pod,Pod密度较低导致节点资源浪费。
IPVlan模式
IPVlan 是我们下一代网络方案,整体性能高于 Bridge 桥接模式,建议内核版本 4.9+,缺点是对 K8s Service 网络支持较差,所以我们在内核、runtime 以及网络插件上做了大量的优化和修复。目前 IPVlan 网络模式已在灰度中,即将全域开放公测。
网络性能对比
下图是各个方案网络性能对比:
Ping 时延
带宽(128B)
带宽(1024B)
TCP_RR
UDP_RR
Host
100%
100%
100%
100%
100%
网卡直通
100%
100%
100%
98%
92%
Bridge
140%
82%
80%
77%
75%
IPVlan
121%
81%
85%
80%
78%
总结
从 Ping 时延、不同带宽、TCP_RR 和 UDP_RR 多个方面同时对比了这几种网络方案,Host作为基准。可以看出,直通网卡的性能可以做到接近host的性能,ipvlan和bridge与直通网卡方式有一定差距,但前两者通用性更好;总体来说 ipvlan 比 bridge 性能普遍更好。
另外,表中 Ping 时延的相对百分比较大,但实际上从数值差距来说只有零点零几毫秒差距。
注:以上为内部数据测试结果,仅供参考。
多运行时(RuntimeClass)调度
Kubernetes 从 1.14.0 版本开始引入了 RuntimeClass API,通过定义 RuntimeClass 对象,可以很方便的通过 pod.Spec.runtimeClassName 把 pod 运行在指定的 runtime 之上,如 runc、runv、runhcs等,但是针对后续不同的 K8s 版本,对 RuntimeClass 调度支持不同,主要分为两大阶段。
1.14.0 <= Kubernetes Version < 1.16.0

apiVersion: node.k8s.io/v1beta1
handler: runv
kind: RuntimeClass
metadata:
name: runv
---
apiVersion: v1
kind: Pod
metadata:
name: my-runv-pod
spec:
runtimeClassName: runv
nodeSelector:
runtime: runv
# ...
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sNWdHhMe-1576138892903)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G0kKq6OZ-1576138892903)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw== “点击并拖拽以移动”)]
低于 1.16.0 版本的 K8s 调度器不支持 RuntimeClass,需要先给节点打上运行时相关的 Label,然后再通过 runtimeClassName 配合 NodeSelector 或 Affinity 完成。
Kubernetes Version >= 1.16.0
从 K8s 1.16.0 版本开始,对 RuntimeClass 调度的支持得以改善,但从实现上,并不是在 kube-scheduler 的新增对 RuntimeClass 支持的算法,而是在 RuntimeClass API 上新增了 nodeSlector 和 tolerations,此时用户的 pod 上只需要指定 runtimeClassName 而无需指定 nodeSelector 或 affinity, kube-apiserver 的 Admission WebHook 新增了 RuntimeClass 的 Mutating,可以自动为 pod 注入 pod.spec.runtimeClassName 所关联的 RuntimeClass 对象里配置的 nodeSelector 和 tolerations ,从而间接地支持调度。

同时,由于很多新的运行时(如 安全沙箱)自身有 overhead,会占用一定的内存和CPU,所以 RuntimeClass API 上新增了 overhead 用于支持此类场景,这部分资源在 Pod 的调度上也会被 kube-scheduler 计算。
参考:
• runtimeclass issue:https://github.com/kubernetes/enhancements/pull/909
• runtimeclass kep:https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/runtime-class-scheduling.md (已加入1.16.0)
• pod-overhead: https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/20190226-pod-overhead.md
新探索-可信/机密计算

很多用户考虑到成本、运维、稳定性等因素去上云,但往往因为对公有云平台安全技术担忧以及信任,很多隐私数据、敏感数据对云“望而却步”;往往现有的安全技术可以帮我们解决存储加密、传输过程中的加密,但无法做到应用运行过程的加密,这些数据在内存中是明文的,入侵者或者云厂商有能力从内存窥探数据。就是在这种背景下,可信/机密计算应运而生,它是基于软硬件技术,为敏感应用/数据在内存中创建一块 Encalve(飞地),它是一块硬件加密的内存,任何其他的应用程序、OS、BIOS、其他硬件甚至云厂商均无法解密这部分内存数据。

在此背景下,我们联合了多个团队,在 ACK 上研发了基于 Intel SGX 硬件加密的 TEE 运行时,可让用户的应用的跑在一个更加安全、可信的运行时环境中,帮助更多的用户破除上云的安全障碍,我们也将在 2020年Q1进行公测。
原文链接
本文为阿里云内容,未经允许不得转载。