基于Python框架Scrapy爬虫示例
引言
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。本篇主要介绍基于Scrapy框架对豆瓣电影TOP250:https://movie.douban.com/top250 进行信息抓取:包括电影排名、电影名称、电影介绍、星级、评价数、描述等信息,并存储到txt、json、MySQL数据库。

准备工作
- 安装
Python3.7Scrapy1.5.1(安装过程这里不做介绍) - 安装
pymysql(用于连接MySQL数据库) - 安装
MySQL数据库(存储爬虫信息) - 在谷歌浏览器安装
XPath Helper插件(解析前端页面并获取标签文本) - 开发工具
PyCharm
主要步骤
- 新建项目(创建一个新的
Scrapy工程) - 明确目标(定义所需要要抽取的
Item对象) - 制作爬虫(编写
spider来爬取某个网站并提取出所有的Item对象) - 存储内容(编写
Pipline来存储提取出来的Item对象)
示例操作
1、新建项目
我们以C盘根目录下创建项目douban为例,首先我们在CMD先进入到C盘,然后输入scrapy startproject douban即可,如下图所示:

我们用PyCharm打开创建的douban项目,其项目目录结构如下所示,scrapy.cfg为项目配置文件,定义了配置文件路径和部署信息等;item.py用来定义数据结构;setting.py为项目设置文件,定义全局设置;pipelines.py用于数据清洗和存储;
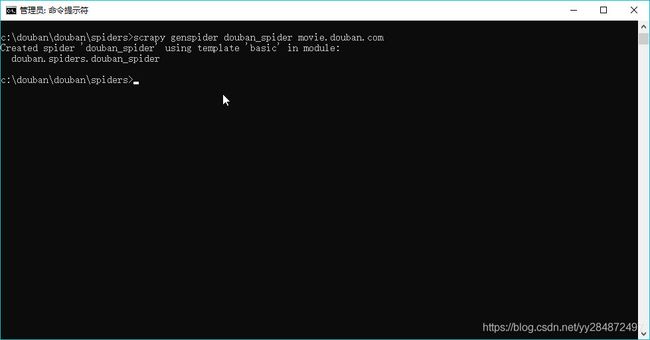
spiders文件夹下主要是我们编写XPath地方,这里我们需要进一步生成,在cmd打开spiders文件,输入scrapy genspider douban_spider movie.douban.com,运行即可,movie.douban.com为我们爬取网站的域名。
在生成的douban_spider中主要编写我们爬虫的逻辑、正则表达式、XPath等

2、定义Item
打开item.py文件,按照提供的示例来定义我们爬取的内容:
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 排名序号
serial_name = scrapy.Field()
# 电影名称
movie_name = scrapy.Field()
# 电影介绍
introduce = scrapy.Field()
# 星级
star = scrapy.Field()
# 评论
evaluate = scrapy.Field()
# 描述
describe = scrapy.Field()
pass
3、编写spider
打开spider文件夹下的doban_spider.py,修改入口URL为https://movie.douban.com/top250,在parse函数中输出返回的内容,然后运行程序测试一下。
class DoubanSpiderSpider(scrapy.Spider):
#爬虫名称
name = 'douban_spider'
#允许的域名
allowed_domains = ['movie.douban.com']
#入口URL
start_urls = ['https://movie.douban.com/top250']
#默认解析方法
def parse(self, response):
print(response.text)
在setting.py中添加USER_AGENT,在浏览器访问https://movie.douban.com/top250,按F12打开开发者工具,在top250的Headers找到USER_AGENT对应的信息:
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36

在CMD命令输入scrapy crawl douban_spider,运行可能会报错缺少某些模块,根据报错信息安装缺少的Python模块,并重新运行爬虫项目,当返回豆瓣首页内容的时候即爬虫程序运行正常。

在douban文件夹下新建一个项目启动文件main.py,运行该文件即可启动爬虫项目。代码如下:
from scrapy import cmdline
cmdline.execute('scrapy crawl douban_spider'.split())
接下来主要是解析返回的代码,这里我们主要通过XPath来解析前端页面代码并获取到文本信息。以排名序号为例,在Elements中可以看出,每个电影的信息存储在一个标签,我们只需要先定位到就可以得到每个电影的具体信息,使用extract_first()来获取到标签里的文本。
#循环条目
move_list=response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
for item in move_list:
#导入item
douban_item = DoubanItem()
#序号
douban_item['serial_name'] = item.xpath(".//em/text()").extract_first()
douban_item['movie_name'] = item.xpath(".//div[@class='info']/div[@class='hd']/a/span[1]/text()").extract_first()
content = item.xpath(".//div[@class='info']/div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s = "".join(i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = item.xpath(".//div[@class='info']//div[@class='star']/span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = item.xpath(".//div[@class='info']//div[@class='star']/span[4]/text()").extract_first()
douban_item['describe'] = item.xpath(".//div[@class='info']//p[@class='quote']/span[@class='inq']/text()").extract_first()
为了继续追踪爬取下一页的内容,我们需要把爬取到的数据yield到item pipelines中,代码如下:
#将数据yield到pipelines
yield douban_item
然后获取到下一页的链接地址next_link,并通过Request来进行下一页的信息抓取:
#解析下一页规则,取后一页xpath
next_link = response.xpath("//span[@class='next']/a/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250" + next_link, callback=self.parse)
运行结果如下:

4、编写pipeline
(1)导出txt
打开pipelines.py文件,新建一个TXTPipeline类,如下所示:
import os
#导出txt
class TXTPipeline(object):
def process_item(self, item, spider):
# 获取当前工作目录
base_dir = os.getcwd()
fiename = base_dir + '/douban.txt'
# 从内存以追加的方式打开文件,并写入对应的数据
with open(fiename, 'a') as f:
f.write(item['serial_name'] + ',')
f.write(item['movie_name'] + ',')
f.write(item['introduce'] + ',')
f.write(item['star'] + ',')
f.write(item['evaluate'] + ',')
f.write(item['describe'] + '\n')
return item
然后在setting中添加ITEM_PIPELINES,如下:
ITEM_PIPELINES = {
'douban.pipelines.TXTPipeline': 300,
}
重新运行main.py文件, 即可在项目根目录下得到一个douban.txt文件,打开可以看到我们爬取到的所有电影信息:

(2)导出json
新建一个JsonPipeline类,如下所示:
#导出json(utf-8)
class JsonPipeline(object):
def process_item(self, item, spider):
base_dir = os.getcwd()
filename = base_dir + '/douban_json.json'
# 打开json文件,向里面以dumps的方式吸入数据
with codecs.open(filename, 'a') as f:
line = json.dumps(dict(item), ensure_ascii=False) + '\n'
f.write(line)
return item
然后在setting中添加ITEM_PIPELINES,如下:
ITEM_PIPELINES = {
'douban.pipelines.JsonPipeline': 200,
}
最终生成的json文件如下:
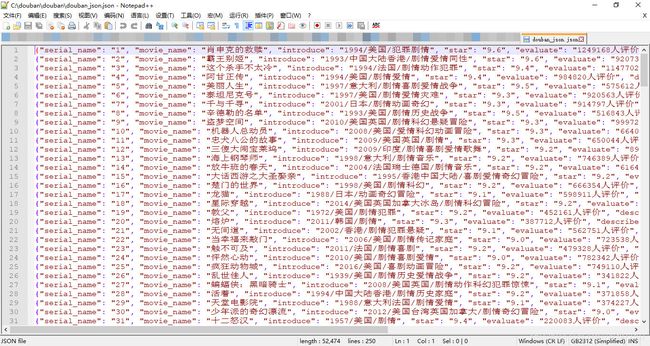
(3)导出到MySQL
新建一个mysqlPipeline类,如下所示:
#导出到MySQL数据库
class mysqlPipeline(object):
def process_item(self,item,spider):
# 取到item里的数据
top = item['serial_name']
moviename = item['movie_name']
introduce = item['introduce']
star = float(item['star'])
evaluate = item['evaluate']
moviedescribe = item['describe']
# 和本地数据库建立连接
db = pymysql.connect(
host='localhost', # 连接的是本地数据库
user='root', # 自己的mysql用户名
passwd='root', # 自己的密码
db='douban', # 数据库的名字
charset='utf8', # 默认的编码方式:
cursorclass=pymysql.cursors.DictCursor)
try:
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 插入语句
sql = "INSERT INTO douban(top,moviename,introduce,star,evaluate,moviedescribe) \
VALUES ('%s', '%s', '%s','%f','%s','%s')" % (top,moviename,introduce,star,evaluate,moviedescribe)
# 执行SQL语句
cursor.execute(sql)
# 提交修改
db.commit()
finally:
# 关闭连接
db.close()
return item
然后在setting中添加ITEM_PIPELINES,如下:
ITEM_PIPELINES = {
'douban.pipelines.mysqlPipeline': 100
}
重新运行程序,打开数据库,结果如下:
