人脸静默活体检测最新综述

©PaperWeekly 原创 · 作者|燕皖
单位|渊亭科技
研究方向|计算机视觉、CNN
活体检测在人脸识别中的重要环节。以前的大多数方法都将面部防欺骗人脸活体检测作为监督学习问题来检测各种预定义的演示攻击,这种方法需要大规模的训练数据才能涵盖尽可能多的攻击。
但是,训练好的模型很容易过度拟合几种常见的攻击,仍然容易受到看不见的攻击。为了克服这些问题,活体检测算法应该:1)学习 discriminative features,可以从预定义的攻击样本中泛化出没有见到的攻击样本;2)快速适应新的攻击类型。
本文总结了在静默活体检测领域中提出的最新方法,并将它们分为六大类。如下,并对每一类中经典的算法进行了介绍。当然,除了静默活体检测,还有炫光、动作等,其他方法不再本文的讨论范围。
Auxiliary supervision
rPPG
Depth
Temporal
fft
De-spoofing
Domain Generalization
Meta learning
NAS

Auxiliary supervision
仅仅使用 binary classification 监督不够合理,因为也不能说明模型是否学习到真正的活体与攻击之间差异。因此,出现了 rPPG、Depth、Temporal、fft 等等监督。

论文标题:Learning Deep Models for Face Anti-Spoofing Binary or Auxiliary Supervision
论文来源:CVPR 2018
论文链接:https://arxiv.org/abs/1803.11097
本文探讨了辅助监督(auxiliary supervision)的重要性。这些辅助信息是基于我们关于真实人脸和欺诈面部之间关键差异的知识获得的,其中包括两个视角:空间和时间。其中空间就是图像的深度(face-depth),而时间就是使用时序 rPPG 信号作为辅助监督。
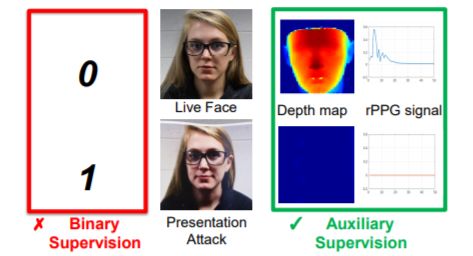
本文的三个主要贡献:
建议利用新颖的辅助信息(即深度图和 rPPG)来监督 CNN 学习以改进泛化。
提出了一种新颖的 CNN-RNN 架构,用于端到端学习深度图和 rPPG 信号。
发布了一个新的数据库:Spoof in the Wild Database(SiW)。
What is rPPG?
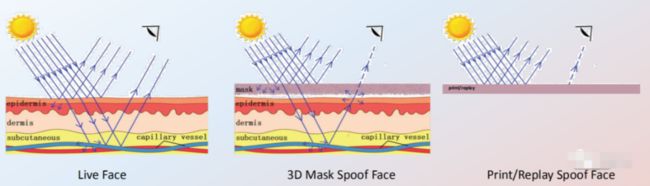
简单说就是发射光强度不一样。当一定波长的光束照射到指端皮肤表面时,光束将通过透射或反射方式传送到光电接收器,在此过程中由于受到指端皮肤肌肉和血液的吸收衰减作用,检测器检测到的光强度将减弱。
如下图所示,如果是 live face,会有部分周围光穿过皮层到达血管,然后反射出来,故相机是能从人体皮肤检测到心跳;而对于 spoof face,由于材料不同,吸收及反射到相机的信息就很不同。

论文标题:Exploiting temporal and depth information for multi-frame face anti-spoofing
论文来源:CVPR 2018
论文链接:https://arxiv.org/abs/1811.05118
以往关于活体的深度学习研究都提取了单帧的深度信息作为辅助监督。不同于这些方法,这篇文章提出了一种通过结合时序运动和单帧面部深度的时序深度度信息。具体的,光流引导特征模块(OFFB)和时序卷积单元(ConvGRU)分别用于提取短时和长时运动信息。

如图所示,输入是固定间隔内的连续帧。单帧框架部是为了提取不同层次的特征,输出单帧估计的面部深度。OFFB 使用连续两帧作为输入,计算短期运动特征。然后将最终的 OFFB 特性输入 ConvGRUs 以获得长期运动信息,输出单帧面部深度的残差。最后,整个网络由估计多帧深度的深度损失和二元损失进行监督。

论文标题:Deep Spatial Gradient and Temporal Depth Learning for Face Anti-spoofing
论文来源:CVPR 2020
论文链接:https://arxiv.org/abs/2003.08061
代码链接:https://github.com/clks-wzz/FAS-SGTD
本文提出了一种新的深度监督体系结构,利用残差空间梯度块(RSGB)捕获区分性细节,并通过时空传播模块(STPM)从单目帧序列有效地编码时空信息。具体细节参考原文。
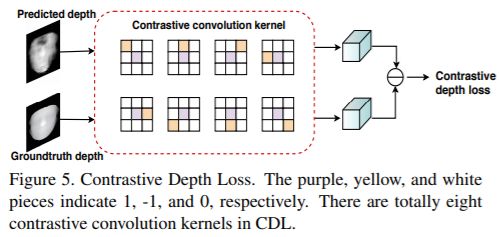
此外,本文还提出对比深度损失(CDL)。Euclidean Distance Loss(EDL)只是协助网络学习摄像机上的物体,只是对像素的逐一进行深度判断监督,而忽略相邻像素之间的深度差异。
然而,物体的深度关系也很重要。因此,对比深度损失(CDL)以提供额外的强有力的监督。如下图,CDL 共有 8 个对比卷积核,其中紫色、黄色和白色片段分别表示 1、-1 和 0。

De-spoofing

论文标题:Face De-Spoofing Anti-Spoofing via Noise Modeling
论文来源:ECCV 2018
论文链接:https://arxiv.org/abs/1807.09968
代码链接:https://github.com/yaojieliu/ECCV2018-FaceDeSpoofing
本文把欺诈检测问题定义为了新问题,将一张欺诈图片分为两部分,一部分是真图片,一部分是欺诈噪声,所以原问题就转化为了 de-X 问题。因为这个方向比较小众,就不做详细的介绍了。


Domain Generalization
一般的,在深度学习算法中, 通常假设训练样本和测试样本来自同一概率分布, 然后设计相应的模型和判别准则对待测试的样例的输出进行预测。
但是实际上当前很多学习场景下训练样本的概率分布和测试样本的概率分布是不同的,而活体检测也正是如此,由于目标域和源域是具有不同的概率分布的,如果在训练过程中我们无法获得目标域的任何信息就代表着训练出的分类器可能无法在目标域上取得良好的表现。
而且在现实应用中,目标域往往出现一些不可知的 case,在这种背景下,domain generalization 应运而生。

论文标题:Multi-adversarial Discriminative Deep Domain Generalization for Face Presentation Attack Detection
论文来源:CVPR 2019
论文链接:https://openaccess.thecvf.com/content_CVPR_2019/papers/Shao_Multi-Adversarial_Discriminative_Deep_Domain_Generalization_for_Face_Presentation_Attack_Detection_CVPR_2019_paper.pdf
代码链接:https://github.com/rshaojimmy/CVPR2019-MADDoG
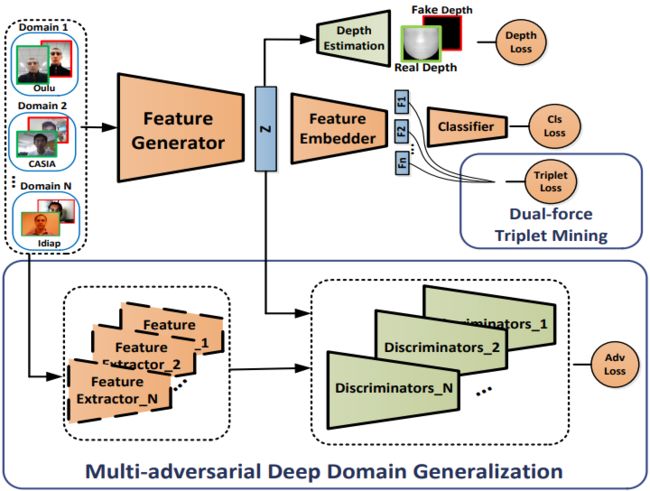
本文重点研究如何提高人脸反欺骗方法的泛化能力。主要流程如下:
1. Multi-adversarial:先在不同 domain 数据集下训练得到各自 domain 的模型,然后通过各个 domain 训练好网络来提特征,用于训练特征生成器和 domain 的判别器,直到生成器输出的特征能成功骗过各个 domian 的判别器,就算学到了 generalized feature space 的表达了。
2. Dual-force Triplet Mining:除了同一个 domain 下的 triplet loss,还设计了 domain 间的 triplet loss,即对于每个 subject 希望其 cross-domain 的 postive 距离要小于 cross-domian 的 negative
3. Auxiliary Face Depth:还增加了预测 depth 的 task,以增强可判别性。

论文标题:Deep Transfer Across Domains for Face Anti-spoofing
论文链接:https://arxiv.org/abs/1901.05633
文中指出目前方法通用性差的主要原因是欺骗设备中材料的多样性,新环境的背景/光照条件会使真实人脸和欺骗攻击有所不同、以及有限的数据集。在本文中提出了一个网络结构,利用目标域中的稀疏标记数据来学习跨域不变的特征,从而实现人脸反欺骗。
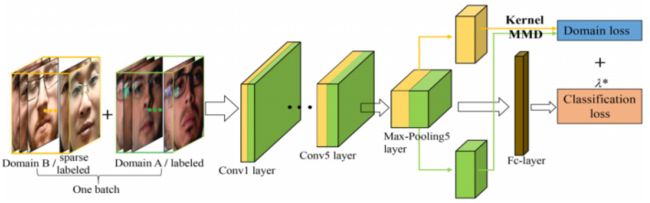
如上图所示,其中每个 batch 包含一半源图像和一半目标图像,最后一个池层输出的两个域的特征用于计算分布距离,计算使用 kernel based MMD,最后的损失函数是分类损失和 domain 损失组成组成。

Meta learning
当遇到新的应用场景,面对中训练样本分布外的攻击类型时,数据驱动的模型往往会产生不可预测的结果。如果要调整活体检测模型以适应新的攻击,就需要收集足够的样本进行训练,然而收集有标签的数据的成本是昂贵的。因此,对于 anti spoofing 这类问题,data-driven 这条路很被动,而且很难看到头。

论文标题:Regularized Fine-grained Meta Face Anti-spoofing
论文来源:AAAI 2020
论文链接:https://arxiv.org/abs/1911.10771
代码链接:https://github.com/rshaojimmy/AAAI2020-RFMetaFAS
如果我们将现有的元学习算法直接应用于人脸反欺骗任务,会由于以下两个问题而降低性能:
1. 人脸反欺骗模型仅具有二进制类监督,会出现泛化效果差。如下图(a)所示,如果仅在二元类别标签的监督下,将常见的元学习算法应用于面部反欺骗,则 meta train 和 meta test 的学习方向将是有偏见的,这使得 meta learning 难以训练并最终找到广义的学习方向。
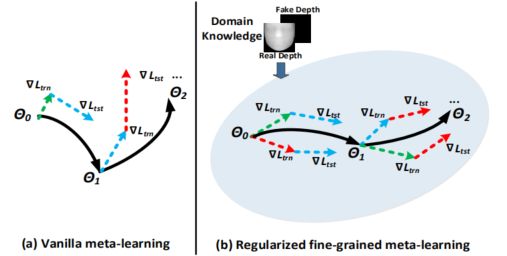
2. 对于 domain generalization 方法的 meta learning,其在每次元学习迭代中将多个源域粗略地划分为两组 meta train 和 meta test。因此,在每次迭代中仅模拟了单个 domain shift,这对于人脸反欺骗任务是效果较差的。
为了解决上述两个问题,如下图所示,本文提出了一种新颖的正则化细粒度元学习框架。
对于第一个问题,与二元类别标签相比,特定于面部反欺骗任务的领域知识可以提供更通用的区分信息。因此,将人脸反欺骗领域知识作为正则化方法纳入特征学习过程中,这样,这种正则化元学习可以针对脸部反欺骗任务,在元训练和元测试中专注于更协调,更通用的学习方向。
对于第二个问题,提出的框架采用了如上图(b)所示的细粒度学习策略。该策略将源域划分为多个元训练域和元测试域,并在每次迭代中在它们之间的每对之间共同进行元学习。这样,可以同时模拟多 domain shift,因此可以在元学习中利用更丰富的域移位信息来训练广义的面部反欺骗模型。
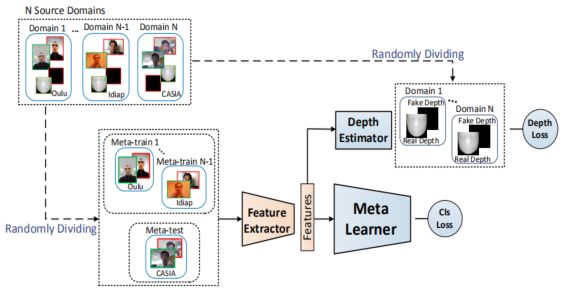
这篇文章的网络由特征抽取器、元学习器和深度估计器组成。在 Meta-Train 过程中,我们从 N 个训练集中随机选择 N-1 个,使用 binary loss 进行训练,使用了深度监督加强对模型的监督。剩余的一个训练集用于 Meta-Test,Meta-Optimization 过程就是对上述 meta-train and meta-test 中的 model 进行更新。

论文标题:Learning Meta Model for Zero-Shot and Few-shot Face Anti-spoofing
论文来源:AAAI 2020
论文链接:https://arxiv.org/abs/1904.12490
这篇文章将 FAS 做为一个 Zero-shot 和 Few-shot 的学习问题。本文的主要贡献有:
1. 首先将 FAS 定义为一个 zero- and few-shot 的问题。
2. 为了解决 zero- and few-shot FAS 问题,提出一种新的基于元学习的方法:自适应内更新元面孔反欺骗(AIM-FAS)
3. 我们提出了三个新颖的 zero- and few-shot FAS 基准点,以验证 AIM-FAS 的有效性。
4. 进行了全面的实验,以表明 AIM-FAS 在零和几乎没有反欺骗基准。
Zero-shot learning 旨在学习一般的区别特征,这些特征对可以从已知的假脸中检测未知的新假脸。Few-shot learning 旨在快速适应反欺骗模式,通过学习预先定义的假脸和收集到的少量新攻击的样本。
具体来说,在 zero- or few-shot FAS 任务,meta-learner 的一次训练迭代包括两个阶段。元学习者使用 supper set 更新其权重,然后在 query set 上测试更新后的元学习者,得到元学习者的学习成绩和损失。最后,我们用元学习优化元学习者损失。


NAS

论文标题:Searching Central Difference Convolutional Networks for Face Anti-Spoofifing
论文来源:CVPR 2020
论文链接:https://arxiv.org/abs/2003.04092
首先,这篇文章提出了一部新颖的卷积算子——Central Difference Convolution(CDC,中心差分)卷积,其擅长描述细粒度信息。如下图所示,CDC 更可能提取 intrinsic spoofing patterns(例如,伪影)。

Vanilla Convolution 可以表示为:
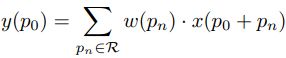
Central Difference Convolution 表示为:
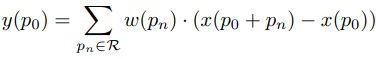
其实,使用了 NAS 方法搜索出了 CDCN++,以及设计了多尺度注意融合模块(MAFM),以有效地聚集了多层次 CDC 特征。
如下所示,搜索空间包括了各种参数形式的 CDC,skip-connet 和 none,采用的是 Differentiable NAS 方法,也就是一个“双层”优化的问题。
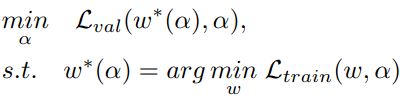
其中, 是 alpha 架构的参数,w 是 alpha对应的模型权重。alpha 利用 validation data 来进行更新,w 利用 training data 来进行更新。
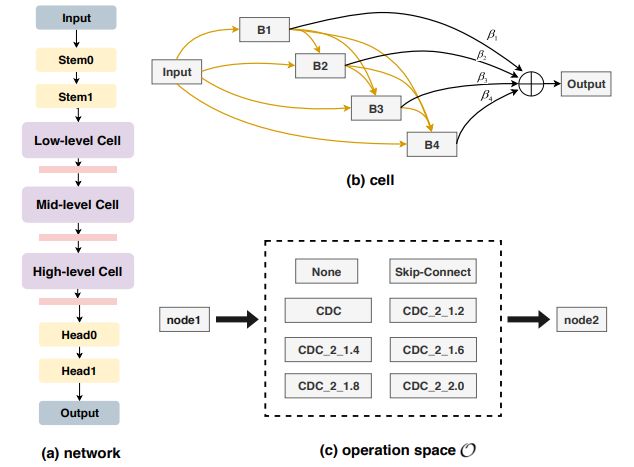
在一个特定的 CDC 搜索空间内,利用神经网络结构搜索(NAS)来发现用于深度监督人脸防欺骗任务的框架级网络。

总结与展望
大多数研究都将活体检测作为一个有监督的学习问题,这样就需要大规模的训练数据来覆盖尽可能多的攻击,然而训练后的模型很容易出现对几种常见的攻击过度拟合,所以,静默活体检测的方法仍有待解决模型的泛化性不足的问题。同时,在研究先进的人脸反欺骗算法的过程中,新的类型的欺骗攻击也被创造出来,并对所有现有算法的造成威胁。
从人类学习识别物体的过程来看,人类认识新的物体并不需要很多的样本作为支撑。这就从某些角度说明,相比机器学习模型,人类在学习一个新任务的时候,学会的不仅仅是先验知识,不妨认为是学会了一个“如何去学习一个新知识"的方法。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
