运用机器学习(含深度学习)方法处理数据问题的完备流程总结+实践经验细节+代码工具书(4):神经网络机器学习模型的搭建与训练阶段
本篇为《机器学习完备流程总结+实践经验细节+代码工具书(4)》,使用经过数据处理阶段处理过的数据,进行神经网络机器学习模型的搭建及训练阶段的相关流程(代码基于pytorch):
什么是好的机器学习模型/如何得到好的模型+数据分析阶段:https://blog.csdn.net/weixin_44563688/article/details/86535274
前置数据处理阶段: https://blog.csdn.net/weixin_44563688/article/details/86558939
非神经网络机器学习模型的搭建,训练及评价阶段: https://blog.csdn.net/weixin_44563688/article/details/86568400
神经网络模型的搭建,训练及评价阶段:(you are here)
神经网络模型的特点,适用数据类型,使用时的推荐策略与实践经验
1.神经网络的特点
神经网络的独特性在于能力十分强大,模型上限很高,理论上可以对任意复杂的函数在任意精度上进行模拟,因此在处理复杂,庞大的数据时神经网络有着其他机器学习模型无法匹敌的优越性。
同时神经网络还有着灵活性高,方便自主设计,改进和添加模块实现特定功能的特点,通过设计不同的神经网络结构,我们可以处理各种不同复杂结构的数据(图像,自然语言,3D点云…),对数据中的信息进行高效的抓取和利用。这是大多其他机器学习模型所不具备的。
而神经网络模型在实际应用中最大的优势或许就是可以十分方便地使用迁移学习(transfer learning)策略,关于这部分在推荐策略里进行详细的解释。
2.神经网络的适用数据类型
由于神经网络高variance低bias的特点,神经网络模型一般更适用于处理结构式数据(暂不清楚这种类型数据的学术名称,因此使用结构式数据代替),比如图像,视频或者自然语言,这种类型的数据有一个典型特征就是数据的信息主要以feature和feature之间的某种结构来体现。单个数据feature数量巨大,feature和feature之间没有本质不同,我们要挖掘的信息更多存在于feature和feature之间的关系结构中,而这种复杂的结构信息往往难以被其他机器学习模型发现和利用,因此对于结构式数据,我们应首先尝试使用神经网络技术进行处理。比如对于图像数据,所有的feature均为以特定color space表示的颜色,单个pixel(feature)的值并不能提供给我们太多的信息,我们真正感兴趣的地方在于pixel和pixel之间以什么样结构组织在一起从而形成了这个图像。
对于feature与feature之间互不相同的一般数据(比如典型的房价估计数据等)我们使用单纯全连接神经网络也可以进行处理。但是需要意识到神经网络是一种十分强力的模型,非结构式数据往往包含的信息并不足够复杂,一般的机器学习模型对于非结构性数据也可以十分高效地进行利用,而对这种简单非结构性数据内在的条件概率分布使用神经网络进行拟合很容易会产生比较严重的过拟合问题。因此对于不足够复杂的非结构性数据,相比于集成其他机器学习模型的方法,神经网络并无明显优越性。
3.神经网络搭建和训练的推荐策略:
在上一节介绍传统机器学习模型时,推荐使用soft-voting(boosting,stacking的集成方式也可以尝试)的方式集成多个不同的机器学习模型来降低模型的Bias,在显著提高模型表现的同时节省了大量用于尝试不同模型与精调模型参数的时间。而对于神经网络模型一般情况下不推荐使用任何的复杂集成方式。这是由于神经网络模型的本质就是众多感知机通过多连接(对于FCN则是全连接)Stacking的集成方式组成的巨型集成模型,因此天生具有着low bias high variance的特性,使用集成学习的方式进一步降低神经网络的bias一般情况下不如单纯的加深加宽神经网络或者加入某些module(使用Auxiliary classifiers结构的神经网络可以通过self-to-self集成方式在提高模型性能同时不显著提高过拟合风险)。
神经网络模型的搭建与训练的推荐策略:使用迁移学习+尽量使用现成经典神经网络结构(不要随意进行网络DIY)
迁移学习即是使用其他人训练的现成的神经网络模型和参数来训练自己的神经网络,根据原数据集和自身数据集的分布差距情况采取不同方法进行模型训练,达到使用少量训练数据也可以又快又好地获得优秀神经网络模型的训练策略。具体使用迁移学习的方法有两种:
- fine-tune:使用某一经典模型,并下载其他团队(一般为知名实验室或者大型公司研究团队)在这个模型上针对其他数据集训练完毕的模型参数,将这些参数作为自己模型的初始参数然后通过一定的策略(详细可见实践经验部分)训练自己的模型。
- use convolutional layers as feature extractor:卷积层是神经网络用于处理图像,大气张量数据等张量形式数据的有效结构,在神经网络中发挥着提取数据高级特征的作用,因此如果先前已经有团队在类似于ImageNet等超大型数据集上进行过卷积神经网络的训练,我们大可直接下载他们使用的卷积层结构和参数,然后在卷积层之后接上我们自己设计的分类层再以一定策略进行训练。这种方法的优势和背后的原因会详细介绍于下方实践经验部分。
为什么使用迁移学习:
推荐使用迁移学习和现成经典神经网络结构来搭建和训练神经网络模型的原因总结如下:
- 经典神经网络结构大都出自于机器学习领域的顶尖科学家,科研团队和实验室,是融合了顶尖从业者们无数的尝试与思考的产物,2015年之后的大多经典神经网络不存在明显的结构浪费和设计缺陷(比如卷积层和FCL的比例合理,各个层神经元的数量配比正确等)。这种结构的合理直接提高了模型的训练效率和平衡了模型的bias-variance。同时,经典的结构一般都有着开源的参数可供直接下载,为迁移学习提供了方便,哪怕实际情况要求我们自己DIY网络,也推荐尽量使用经典网络的部分结构和参数。对于深度学习模型而言,很多时候模型参数的价值是大于模型结构的:举个例子,无人车领域知名的目标识别网络voxelNet在原paper中可以达到非常不错的效果,但是由于参数未开源,后续大多团队很难自己训练得到精度足够高的模型。
- 迁移学习提供了非常好参数初始点,极大加速了网络收敛速度的同时,也有大概率使参数落入很不错的局部最优点。我们知道神经网络模型的训练充满着随机性,最后模型收敛的局部最优点的好坏决定了模型的性能(局部最优点的好坏在深度学习中并不重要,具体原因之后会详细论述),而整个模型训练的过程就是从初始点一步一步走向局部最优点的过程,很可能我们的模型花了很多时间,走了很长路才发现终点并不足够满意。使用迁移学习,有很大概率从一开始我们就在某个十分不错的局部最优点附近,哪怕我们手头的数据和用于获得这些现成参数的源数据有着很大的不同,使用现成参数作为初始点也不会比通过某个任意分布完全随机产生的在0左右的初始参数差。这就意味着我们不仅可以花更少的时间训练模型,同时训练完毕的模型也会有更好的表现。
- 使用迁移学习,可以确保各个神经元有着独立的发展方向,相互之间uncorrelated程度大。神经网络训练中的一个常见问题就是,很多神经元在训练之后高度相似,其实是在完成相似的任务。这种现象的部分原因在于神经元初始化的方法不当:一般的初始化参数方法是选择某个均值为0的分布,然后从这个分布中进行随机取样来对参数进行初始化,使用这种方法进行神经元初始化后很可能部分神经元会有着比较类似的初始参数分配,导致他们在后续的更新中沿着类似的发展方向进行更新。这种情况可以使用dropout来进行一定的改善,但是对于卷积层或者浅层神经网络dropout并不适用(原因会在之后进行讨论。)。而开源下载的训练完毕的模型中,由于模型往往经过研究者大量反复训练和调节有着出色的实际效果,因此神经元之间往往correlated程度较低,降低了模型overfitting的程度,同时提高了模型的结构空间利用效率。
- 在训练数据不足够多的时候,使用迁移学习策略也可以获得表现优秀的较深神经网络模型。神经网络模型由于具有较高的variance,因此一般需要使用较多的训练数据才可以避免或者减轻overfitting的发生。但是在数据量不足够多的情况下(不足够多:至少小几千few thousand的量级),通过迁移学习也可以获得效果十分不错的神经网络模型,但是这里需要一些策略指导(对于下载好的网络,我们只训练最能体现不同数据差异的那一小部分网络结构,同时fine-tune部分剩余网络即可),具体会在实践经验环节详细介绍。
- 一般的经典网络的开源参数均训练自类别变量非常之多的巨型数据集,比如ImageNet。模型可以对上千个类别的图片进行十分准确的分类,因此单纯使用迁移学习获得的参数,模型就可以捕捉和区分非常之广的目标特征。你要分类的图片类别很可能原本就包含于这个既成模型的分类对象中,即使不包含,对应的特征一般也不会相差太多,经过简单快速的fine-tune也可以直接进行转化。比如你要对图片中的交通工具进行分类,imageNet本身就包含汽车,火车,船,飞机等类别,即使模型不经过fine-tune拿来直接使用也会有着非常不错的表现。
4.实践经验:
实践经验分为两部分,搭建/训练经验与经典神经网络和学术前沿(将持续更新),主要面向CNN类模型。
搭建/训练经验与经典神经网络
0.简单的神经网络能力也足够强大,如无必要尽量不要使用resNet,inception-resNet等超级网络。在使用神经网络模型前要对自己数据的复杂程度和完成任务目标所需要从数据中抽象出的特征的高级程度有一个大概的感觉,然后使用复杂度相匹配的机器学习模型(神经网络模型),在一个简单的图像分类问题上使用深度学习是不明智的做法,不仅过拟合问题严重,模型的训练难度也很大。
1.尽可能使用经典网络结构并采用迁移学习的方式来进行模型的搭建和训练。具体原因可见上方推荐策略的部分,需要注意的是使用2015年之前的网络时需对网络进行加入BN等改进。主要代码会提供于下方代码部分,这里主要介绍下在具体实施迁移学习时应采用的策略(主要针对结构性数据作为输入时的网络):
- 数据量较少时:在数据量较少时应谨记的原则是,任何的过激fine-tune都有让神经网络overfitting的风险,因此我们应该尽可能少的调节网络参数,或者说只调节那些最能体现数据差异性的参数,同时应使用较小的起始学习率(<0.001),应该清楚我们离最优点并不会很远而且过多的训练会有overfitting的可能,同时我们的源数据和使用数据差别越大,我们就应该fine tune越多的层。而正如之前所说,由于神经网络是层级结构,越后面的层提取的特征越高级,也越能体现出不同目标的具体差异,因此我们应固定前方层的参数,从最后一层向前开始逐步尝试fine-tune。同时最后的那一层网络一般体现着具体的任务目标,一般是需要完全删除之后重新训练的(比如如果我们的分类任务是分4类,那么最后一层就只有4个输出,但是原来的网络输出很可能不是这个数字),所以对于最后一层,学习率可以适当提高(exp:0.01)。
- 数据量较多时:可以单纯使用迁移学习的参数当作模型的初始参数然后进行常规训练(学习率不应过大)。
- 若含有卷积层:fine tune主要使用于卷积层之后的分类器(全连接层),在数据量不足够的时候,一般只考虑fine tune全连接层即可,若数量足够可以尝试fine tune位于特征提取器后部用于组织高级抽象特征的卷积层,对于低级的卷积层一般没有fine-tune的必要。这也是可以使用现成的卷积层当作特征提取器直接进行迁移学习背后的原因。
2.需要增强神经网络性能的时候,加深网络深度的性价比优于加宽网络宽度。这里的深度指神经网络的层数,宽度指神经网络每一层的神经元数量。简单来说,如果我们的数据比较复杂,需要设计(不推荐自己设计)一个强大的神经网络时,那么我们应该尽量加深这个网络的深度而不是增多网络每一层的神经元数量。背后的原因主要有三点:
- 更多的层数可以使模型有更多的非线性处理单元。非线性激活单元(函数)的数量是影响神经网络性能的最关键因素,虽然使用一个简单的二层神经网络,只要有着足够多的神经元就可以模拟任何函数(在任何精度上),但是如果使用多层神经网络, 进行相同精度的函数模拟我们需要的神经元总数远远少于二层神经网络。
- 当神经网络深度加大时,局部最优点和全局最优点的差距会变小,意味着我们的模型在收敛后抵达的大多数局部最优点并不比全局最优点差太多。梯度法优化的机器学习模型大多存在着无法确保收敛于全局最优的缺点,但是在深度学习领域中,是否收敛于全局最优点并不重要。深度学习模型训练多次最终的表现也不会相差太多的原因,也正在于此。
- 神经网络是层级结构,对于卷积层等特征提取器来说,层数的加深也意味着模型可以提取抽象出更高级的特征,而往往更高级的特征才能反应出数据的特性,如果可视化在不同训练集上训练得到的低级卷积层参数,会发现其实这些卷积层在寻找着类似的特征,这是因为大多数物体的低级特征是一样的:物体都由类似的线,角,edge组成,所以当神经网络不足够深,没有办法提取物体的高级特征的时候,物体和物体之间的差异将会变得模糊,最后经过进入神经网络分类器(全连接层)的特征的可分性也就较低。
建造更强力神经网络的一种思路:增强神经网络性能最显而易见的方式是搭建更加庞大的网络结构—让网络更深更宽。加大网络的深度我们就可以提取和利用抽象程度更高的特征,而深度上的提高可以借助res module来实现;增大网络的宽度,本质是上是希望网络能够更加充分地利用某一指定层级(某一具体抽象程度)特征中的信息,宽度的增加除了单纯使用更多的神经元外,更有效率的一种方式是使用inception module(原始的inception module通过组合比较简单的抽象特征,比较复杂的抽象特征,和简化的简单特征,保留不同层次的高阶特征来丰富网络的表达能力,值得注意的是DIY模型时如需使用inception module,不要在网络太前面使用),inception module + res module的组合使用是目前产生超级网络的主流方式之一,也是我们希望加深加宽网络时的重要选择。(2017年提出的DenseNet脱离了加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能的定式思维,通过特征重用和旁路(Bypass)设置,在大幅度减少了网络的参数量的同时,又在一定程度上缓解了gradient vanishing问题的产生)。
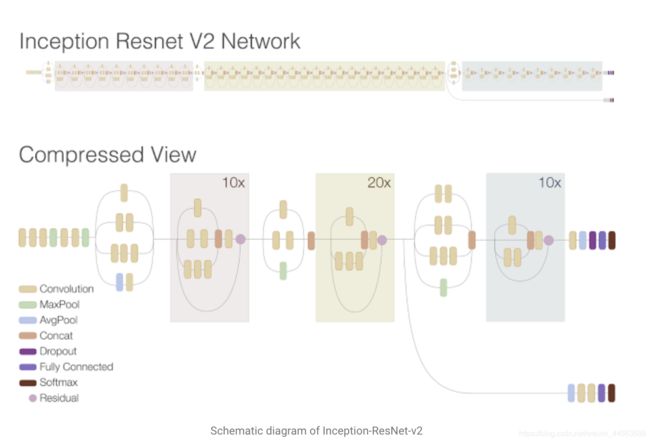
对于巨型网络,存在着容易过拟合和训练速度过慢的问题,因此我们希望在不较大影响模型提取feature的抽象与丰富程度的前提下,尽可能使用更少的参数。一个常常使用的有效方法是将卷积层中的filter进行拆解,将一个N * N的fitler拆解成为一个N * 1的filter后接一个1 * N的filter(交换顺序也可),如此一来,这个filter在感受野不变的前提下有效降低了参数数量,减少了过拟合风险的同时加速了模型训练,同时把一个filter分解成了两个,增加了非线性激活的次数,有助于提高模型的表现。但是有研究指出,多层小size filter的计算量其实是要多于单层大size filter的,我们不应该仅仅用总的参数数量衡量模型的计算成本。
最后插句题外话,resNet的本质或许并不能单纯理解成一般的线性深度神经网络, resNet可能只是很多浅层网络的集成:《Residual Networks Behave Like Ensembles of Relatively Shallow Networks》:
https://arxiv.org/abs/1605.06431
3.adam(Nadam)与SGD的取舍:先说结论,不考虑训练速度的时候,adam一般不如加入动量或者Nesterov的SGD,adam训练速度一般更快但是收敛效果不好(very poor solution),SGD训练速度可能不如adam但是往往收敛效果更好(结论来自于《Improving Generalization Performance by Switching from Adam to SGD》)。
关于adam和sgd的对比,UC Berkeley的文章《The Marginal Value of Adaptive Gradient Methods in Machine Learning》中有着这样的结论:
Despite the fact that our experimental evidence demonstrates that adaptive methods are not advantageous for machine learning, the Adam algorithm remains incredibly popular. We are not sure exactly as to why
目前TSoA(The-State-of-Art)级别的神经网络模型也基本都采用最基本的SGD训练获得,大家不用adam而更喜欢选择SGD的主要原因在于:
- adam未必收敛:由于adam在每一个更新时刻采用的梯度是在固定时间窗口内的梯度累积值,随着时间窗口的变化,遇到的数据可能发生巨变,使得梯度值可能会时大时小,不是单调变化。这就可能在训练后期引起学习率的震荡,导致模型无法收敛。
- adam会错过局部最优:adam中加入的动量方法让使用adam更新的神经网络不会陷于某一局部最优解的同时,也为模型跳出最优解提供了可能,同时adam在训练后期的学习率太小,在训练末期的更新步长往往不足以让模型重新下到最优点。
但是需要注意的是,在部分研究中,研究者们用adam也可以获得非常不错的收敛效果,尤其是在稀疏的数据中,adam常常有着十分不错的综合表现。因此adam与SGD孰优孰劣并没有定论。
那么一般情况如何使神经网络又快又好地进行训练呢?这里提供两种前沿深度学习的常用方法:
- 在训练初期使用adam加快训练,基本收敛后改用小learning rate,大batch size的SGD。
- 为adam的学习率设置下界,使得学习率在在训练后期不至于太小。
4.积极跟踪训练进展:确保我们的模型训练正常,具体的方式有:
- 重要:每隔固定次数的更新后plot模型在validation set上的loss曲线,确保validation set的loss曲线在稳步下降同时没有抬头(变大)的倾向。抬头倾向出现的时候应该停止训练避免模型overfitting(early stopping)。
- 重要: 确保loss变小的时候准确率在变高。loss变小的时候准确率不变或变大缓慢的问题其实不时会发生,发生的一般原因在于使用了不合适的loss function或者模型没有采用BN/没有使用Xavier,He等参数初始化方法。
- 不重要:每隔固定次数的更新后可视化各个神经元的参数,确保各个神经元的参数低噪音,各有差异,同时神经元确确实实在做一些有价值的事(比如可视化CNN中的filter参数,得到的图像应该类似于图像中的某些物体特征)。同时可以对输入进行求导,确定模型是在利用正确的信息(比如卷积核参数:因为2d卷积实际上是在进行1d向量的内积,我们希望filter捕捉有用信息,因此filter中的参数应该与它想捕捉的信息相似,对于一个好的filter我们应该能从它的参数中发现一些‘规律’。)(原因见博客(1)“机器学习的习惯”部分)。
- 不重要:对于CNN等网络,模型可以分为两部分,特征提取层与特征分类层,模型的最终表现应视为两部分性能的乘积,我们可以通过判断经过特征提取层之后特征的可分性来决定模型的改进方向,这里介绍一个理想情形:如果模型的表现一般,但是经过特征分类层之后的数据有着较强的可分性,那么或许我们需要增强的是模型特征分类器的能力,如果模型经过提取的特征可分性差,那么我们应想办法增大提取层的性能(更常见,因为简单的全连接神经网络也有着很强的分类性能,一般模型表现的不理想更多是由于特征提取层的设计与训练问题)。
5.根据激活函数使用Xavier(sigmoid),He(ReLU)等初始化方法,默认使用BN,谨慎使用dropout,非最终层的所有层使用ReLU作为激活函数。
- ReLU:实际情况中除了需要将结果转换为概率或运用门思想之外情况不考虑使用除了ReLU之外的任何激活函数,ReLU作为激活函数有着太多无可替代的优点(计算高效,非饱和区域大),哪怕伴随着dead ReLU现象的发生,只要不使用太大的学习率,略大于0的bias并结合使用BN和特殊初始化方法一般不会成为问题,而且适量dead ReLU的出现也体现了大脑神经元连接稀疏性的特点,反而增加了模型的泛性。
- Xavier(sigmoid),He(ReLU)初始化参数:对于稍微深一点(4-5层)的神经网络,在不使用BN的情况下随性的初始化会导致梯度消失,模型基本无法更新,因此使用Xavier,He初始化网络是必要的,当然如果使用BN,初始化的影响或许不是那么大。同时,若不使用Xaiver等特殊初始化方法,使用正态分布给参数初始化,均应使用截断正态分布来初始化参数。
- BN:BN可以视为神经网络的必备组件,可以无条件直接使用,对于神经网络训练速度的提高,训练的稳定性和最终收敛时的表现(BN有着regularization的效果)有着决定性的作用,BN原paper中建议BN的位置应放于激活函数之前,但是也有研究者提出使用Xavier(sigmoid),He(ReLU)初始化参数 + 将BN后置于激活函数之后的方式会提高模型的表现,从理论上个人更同意这种做法,但是具体怎么做最好目前仍然处于争论之中。同时若使用BN,则在数据增强中不使用光学畸变等可以较大改变数据‘真实程度’的方法,因为达到相同的效果,使用bn的模型对于数据集中的每个模型使用的次数更少,因此更真实的训练集效果更好。
- Dropout:关于Dropout的使用建议是,在不使用BN的情况下,应该积极尝试使用dropout于全连接层的前几层(一般不要轻易用于FCL的最后一两层,不要尝试用于卷积层,因为对最后一两层神经元的drop带来的消极影响神经网络较难恢复;卷积层参数较少,一般不会有过拟合的问题,不需要使用dropout)来确保神经元可以独立地学习到互不相同的东西来降低过拟合,但是在使用BN时不要使用dropout。目前大多研究开始渐渐放弃dropout,主要原因在于BN的不可替代性以及当使用BN时,BN在替代了dropout部分作用(降低overfitting)的同时,存在着某些与dropout同时使用时不好协调的问题:《Understanding the Disharmony between Dropout and Batch Normalization by
Variance Shift》 https://arxiv.org/pdf/1801.05134.pdf。根据这篇文章中的结论,如果一定要同时使用BN和dropout,应该将dropout添加于所有BN之后。最终值得注意的是在测试时应关闭网络中的所有dropout和BN,在pytorch之中使用如下代码来打开和关闭网络中的BN与dropout:
model.train()
model.eval()
6.跟踪模型在validation set上的loss曲线,每当曲线趋于收敛时降低学习率1/3并适当加大batchsize来加快训练同时更好地收敛。从SGD的原理出发,这么做的原因显而易见,因此这里不做过多解释。
7.在数据噪音较大,或者希望模型只利用数据中的部分信息来进行分类或者回归的时候可以使用attention module:加入attention module(对于CNN分为channel-wise和map-wise两类attention module)可以降低模型对于无用信息的利用率,使用真正重要的信息来处理数据问题,具体有两个好处:
- 在数据噪音较大的时候,通过加入attention module可以让模型在分类时受到较少的噪音影响(不利用包含较大噪音的无用数据),有效避免了过拟合的发生。使用纯净数据时attention module对于模型准确率的提高作用有限。
- 提高了模型的可靠性与安全性:使用我在博客part1中举的那个例子来说明:训练一个简单的CNN来对图像中人物的发色进行分类时,通过对输入进行梯度计算发现模型很多时候在提取和利用人物肤色的信息,但是肤色和发色并无任何的因果性(染发)因此借助肤色来对发色进行分类是不安全可靠的。为了提高模型的安全性和可靠性,我们可以训练一个attention module,让模型可以先锁定图片中人物头发的位置,然后只利用头发的信息对发色进行分类。
8.在CNN中使用spatial transform来使得模型更加transform invariant:在无人驾驶,手写数字,签名识别等要求模型精度较高的使用场合,STN(Spatial Transformer Network)是十分有效的模型组件,可以显著提高模型的表现。具体原理是通过一部分额外的挂件网络可以让模型学习到一个2D仿射变换,将输入中的物体旋转拉伸平移至模型更‘熟悉’的样子,降低模型的特征提取难度。
9.对于分类问题使用cross-entropy,对于回归问题推荐使用smoothL1loss:
- 分类模型通过训练在降低cross-entropy loss的时候其实是在尝试缩小通过模型模拟的分布和训练数据集数据真实分布的KL divergence,一般情况下KL divergence是一个很好的衡量分布差异程度的统计量(但是在部分经过巧妙设计的数据中,度量并减少其他F-divergence会有更好的效果),关于不同统计divergence的考虑更多地会在GAN的设计中进行,这里不进行过多介绍。
- 推荐对回归问题使用smoothL1loss的原因:L2回归不太倾向预测过大值,因为预测较大值时产生的误差带来的L2-loss一般较大,而模型为了避免产生较大的L2-loss会在应该产生大预测值的时候倾向于产生更小的预测值,这点在随机森林等算法的实践中尤其明显,对于神经网络的影响较小。而使用L1loss则存在函数在0处不连续的情况。smoothL1loss结合了L2和L1的优点,在预测值不大时使用L2,在预测值较大时使用L1,即不会对压抑大预测值的产生,也不会存在求导的奇点问题。
10.改变feature map的大小(长宽与channel数量):
- 改变channel数量:在CNN中如果我们需要进行相同大小,不同channel数量的feature maps的直接相加(比如res module),那么可以通过1 * 1 * C的卷积核来单纯地对feature maps的维度进行改变。同时1 * 1 * C的卷积核也是一种可以十分高效(较少参数)组织局部信息的结构,在现代神经网络结构被广泛运用(res module,inception module等中)。
- 改变feature map长宽:如果希望feature map的长宽变小只需要使用pooling等各种downsampling方法即可,若希望feature map的长宽变大,一般可以使用反卷积技术实现上采样。
11.一般使用Max pooling,最后一层卷机层可以采用平均池化:池化层的使用可以增加后续神经元的感受野,简化计算,同时提高模型对于噪音的抵抗能力和对局部关键信息的提取能力。一般推荐使用max pooling即可,但是也有研究者指出对最后一层卷积层使用平均池化可以获得更好的效果。
前沿
下方提到的方法均来自于比较前沿(2015 - present)的神经网络研究,不是神经网络的常规结构,但是我自己比较欣赏它们背后的学术原理,因此这里进行简单介绍,这部分将作为之后持续更新的重点。
1.Auxiliary classifiers结构使得神经网络可以进行另一种高效地集成学习(self-to-self式集成)。的使用深度学习时,可以使用辅助分类节点auxiliary classifiers来实现模型集成,这种方法不光给网络增加了反向传播的梯度信号,同时也提供了额外的正则化,当然它最厉害的思想在于可以通过自己集成自己的方式实现对于神经网络的集成学习:《Rethinking the Inception Architecture for Computer Vision》
https://arxiv.org/abs/1512.00567
2.Label smooth:我们给一张图片某个label的时候,其实是抹杀了这张照片中的其他类别的成分,是一种hard assignment。比如一只狮子,它其实有部分猫的成分在其中,也有部分狗的成分,如果我们将这只狮子分类成狮子,那么就相当于否认了狮子包含的猫的成分与狗的成分,但是这种成分确是客观存在的,所以hard assignment式的label给模型的分类造成了困难,这个原因可以理解为使用label smooth的部分动机:我们希望获得data的概率表示。
3.Dense→Sparse→Dense (DSD)训练法:简单来说,使用裁剪之后的模型为初始值,再次进行训练调优所有参数。其中使用的稀疏(Sparse)相当于一种正则化,有机会把解从局部极小中解放出来。这种训练方式有点人类学习模式的意味:初次学习知识→复习时回顾加深理解加深记忆。
代码部分(pytorch):
搭建神经网络:
一般可以通过完全自己搭建和使用现成模型搭建(直接使用/微调/只使用现成网络的部分/全部结构)两种方式来获得神经网络模型。
1.完全自己搭建:这里提供了一个基本包含了所有神经网络基本组件的CNN网络模型,在自己搭建模型的时候只用调整组件的位置,数量,替换使用相同功能的其他组件以及改变网络的结构即可获得一个经典的简单CNN网络,网络中各层(layer)与操作(operation)的相对次序已经调整至合理。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv0 = nn.Conv2d (1,32,5,stride = 1,padding = 2)
torch.nn.init.kaiming_normal_(self.conv0.weight)
self.conv0_bn = nn.BatchNorm2d(32)
self.conv1 = nn.Conv2d (32,64,5,stride = 1,padding = 2)
torch.nn.init.kaiming_normal_(self.conv1.weight)
self.conv1_bn = nn.BatchNorm2d(64)
self.fc1 = nn.Linear(3136,1024)
torch.nn.init.kaiming_normal_(self.fc1.weight)
self.fc1_bn = nn.BatchNorm2d(1024)
#使用bn时一般不使用dropout,若使用dropout应该加于bn之后
#self.fc1_drop = nn.Dropout(0.4)
self.fc2 = nn.Linear(1024,10)
torch.nn.init.kaiming_normal_(self.fc2.weight)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv0_bn(self.conv0(x))),(2,2),stride= 2)
x = F.max_pool2d(F.relu(self.conv1_bn(self.conv1(x))),(2,2),stride= 2)
x = x.view(x.shape[0], -1)
x = F.relu(self.fc1_bn(self.fc1(x)))
#x = self.fc1_drop(F.relu(self.fc1(x)))
x = self.fc2(x)
#若使用cross-entropy损失函数则不需要对输出sigmoid或者softmax激活
return x
print(net)
2.使用现成模型搭建:我们一般不需要完全自己进行网络设计,使用现成经典神经网络会让搭建过程高效很多。首先我们需要下载具体网络结构以及参数:我们可以从github中寻找开源网络结构和参数进行下载,也可以直接从torch.models中加载常用结构(使用现成模型需要我们提前了解各个经典网络的大概特性,之后会尝试进行总结,目前来说denseNet和denseNet的后续版本应该是性能最好的CNN深度学习模型):
#torch.models中包含的常用神经网络结构
#models.VGG
#models.AlexNet
#models.resnet
#models.inception_v3
#models.SqueezeNet
#models.densenet
#以models.resnet152为例
#pretrained设置为True,会自动下载模型所对应权重,并加载到模型中
model = models.resnet152(pretrained=True)
print(model)
之后,我们可以直接使用现成网络,对现成网络的部分结构进行更改(替换/删除)或者将现成网络的部分结构作为自己神经网络的部分结构使用。值得一提的是,不论使用哪种策略一般情况下都需要对模型的最后一层进行替换,因为模型的最后一层体现着具体的任务目标,往往不会相同。
若直接使用现成网络,则上一步下载得到的模型除了替换最后一层之外不需要进行任何更改;如果想要修改模型的部分结构后再进行使用,可以先print出网络的结构,找到目标结构的位置和名字后直接进行修改:
#比如:
model.conv1 = nn.Conv2d(4, 64, kernel_size=7, stride=2, padding=3, bias=False)
model.fc = nn.Linear(2048, 21)
如果想加入现成模型的部分结构到我们自己的神经网络中,可以进行类似这样的处理:
class Net(nn.Module):
#传入的model为我们提前下载的resnet
def __init__(self,model):
super(Net, self).__init__()
#取掉model的后两层(fc层和pooling层),并新添加一个反卷积层、池化层和分类层
self.resnet_layer = nn.Sequential(*list(model.children())[:-2])
self.transion_layer = nn.ConvTranspose2d(2048, 2048, kernel_size=14, stride=3)
self.pool_layer = nn.MaxPool2d(32)
self.Linear_layer = nn.Linear(2048, 8)
def forward(self, x):
x = self.resnet_layer(x)
x = self.transion_layer(x)
x = self.pool_layer(x)
x = x.view(x.size(0), -1)
x = self.Linear_layer(x)
resnet = models.resnet50(pretrained=True)
model = Net(resnet)
训练神经网络:
首先编写一个train函数来方便对训练进行管理,这里提供的train函数可以:
- 训练网络参数并返回历史loss和准确率(trainset & validation set)数据方便跟踪训练,如果传入的init参数为True,说明我们希望重新训练一个模型(同时需要注意在函数外部初始化net),若为False,则读取经过训练的历史模型和保存的历史记录(loss,准确率)后继续训练模型。
- 方便调参
- 保存模型参数和历史记录
- 通过设置to_train来对模型中的参数进行部分更新
def train(trainset,val_set,val_label,net,to_train,lr_step_size,lr_gamma,log_dir = None,opt = 'adam',lr = 0.001,epoch_size = 20,batch_size = 50,init = True):
from tensorboardX import SummaryWriter
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader
if init == True:
losslist = []
acclist=[]
losslist_val = []
acclist_val = []
else:
hist = np.load('histroy.npz')
losslist = hist['loss']
acclist = hist['acc']
losslist_val = hist['loss_val']
acclist_val = hist['acc_val']
net.load_state_dict(torch.load('params.pkl'))
criterion = nn.CrossEntropyLoss()
if opt=='adam':
optimizer = optim.Adam(to_train,lr=lr)
else:
optimizer = optim.SGD(to_train,lr=lr,momentum = 0.5)
#learning rate schedule
scheduler = StepLR(optimizer, step_size=lr_step_size,
gamma=lr_gamma)
loader = Data.DataLoader(
dataset=trainset,
batch_size=batch_size,
shuffle=True,
num_workers=2 # 多线程来读数据
)
#tensorboardx summarywriter
if log_dir != None:
if not os.path.exists(log_dir):
os.mkdir(log_dir)
summary_writer = SummaryWriter(log_dir)
#选择使用的GPU
#with torch.cuda.device(gpu_id):
for epoch in range(epoch_size):
net.train()
net.cuda()
for i, data in enumerate(loader):
inputs,targets = data
inputs = Variable(inputs.float().cuda())
targets = Variable(targets.cuda())
###################
predict = net(inputs.reshape(50,1,28,28))
loss = criterion(predict, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#总的step数
step = epoch * len(loader) + i
if log_dir != None:
#summary_writer
summary_writer.add_scalar('train/loss', loss.data, step)
valid_loss = []
losslist.append(loss.item())
predict = np.argmax(predict.data.cpu().numpy(), 1)
acc = np.mean(predict == targets.cpu().numpy())
acclist.append(acc)
if step%10 == 0:
net.eval()
net.cuda()
inds=np.random.randint(0,len(val_label)-1,batch_size)
inputs = Variable(val_set[inds].float().cuda())
targets = Variable(val_label[inds].long().cuda())
###########################
predict = net(inputs.reshape(50,1,28,28))
loss = criterion(predict, targets)
losslist_val.append(loss.item())
predict = np.argmax(predict.data.cpu().numpy(), 1)
acc = np.mean(predict == targets.cpu().numpy())
acclist_val.append(acc)
print("EPOCH %d valid_loss: %.4f, train_loss: %.4f" %
(epoch, loss.data, losslist[-1]))
print('valid_acc:%f'%acc)
if log_dir != None:
summary_writer.add_scalar('valid/loss',
losslist_val[-1], (epoch+1)*len(loader)+step)
np.savez('histroy',loss = losslist,acc = acclist,loss_val = losslist_val,acc_val = acclist_val)
torch.save(net.cpu().state_dict(), 'params.pkl')
net.train()
net.cuda()
torch.save(net.cpu().state_dict(),
"./params_epoch/net_{}.pth".format(epoch+1))
#lr scheduler
scheduler.step()
return losslist,acclist,losslist_val,acclist_val
class data_():
def __init__(self,data,label):
self.data_train = data
self.data_label = label.long()
def __getitem__(self, index):
return [self.data_train[index],self.data_label[index]]
def __len__(self):
return self.data_train.size(0)
简单的测试代码:
train_set = train_dataset.data.reshape(60000,1,28,28)
train_lab = train_dataset.targets
data_val = test_dataset.data.reshape(10000,1,28,28)
val_label = test_dataset.targets
data = data_(train_set,train_lab)
model = Net()
model = model.cuda()
# Training settings
batch_size = 64
train_dataset = datasets.MNIST(root='./data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='./data/',
train=False,
transform=transforms.ToTensor())
#train funciton:
#trainset:torch.Tensor,[train_data,train_label]
#for exp:
#val_set:torch.Tensor,val_data
#val_label:torch.Tensor,val_label
#to_train:a list contains all parameters you want to update:
#for exp:
to_train = []
for i in model.children():
for j in i.parameters():
to_train.append(j)
#log_dir:存放tensorboard中使用的graph和scalar数据的位置
#lr_step_size:lr_schedule中每过lr_step_size降低lr
#for exp:
log_dir = None
lr_step_size = 50
lr_gamma = 1
#test:
a,b,c,d = train(data,data_val,val_label,model,to_train,lr_step_size,lr_gamma,log_dir,opt = 'adam',lr = 0.001,epoch_size = 100,batch_size = 50,init = True)
#tensorboard --logdir=yourpath/train_dir --port=6008
- 数据增强,如果希望节约内存资源增强数据的产生可在训练过程中动态进行,如果希望加快训练速度可用augmentor库进行提前产生增强数据,推荐的方式是使用augmentor等库提前产生增强数据之后保存在本地,训练时实时调取。
#num:产生的增强数据数量
#path:产生增强图像的原图像路径,之后产生的增强图像会出现在这个路径下的output文件夹中
def augmentor(num,path):
p = Augmentor.Pipeline(path)
p.random_distortion(probability=0.5, grid_width=4, grid_height=4, magnitude=8)
p.rotate(probability=0.7, max_left_rotation=10, max_right_rotation=10)
p.flip_left_right(probability=1)
p.zoom(probability=0.5, min_factor=1.2, max_factor=1.3)
p.gaussian_distortion(probability = 1,grid_width = 5,grid_height = 5,magnitude = 5,corner = 'bell',method = 'in')
p.skew(probability = 0.5)
p.process()
p.sample(num)
类似,我们可以写一个test函数方便对模型表现的检验。
*如果使用迁移学习:使用迁移学习策略时我们不需要更新神经网络中的所有参数:我们需要在训练中fix部分层的参数,在pytorch中我们有两种常用方法来实现参数的冻结:
1.将不需要进行更新的参数的.requires_grad属性设置为False,之后将网络的所有参数传至optimizer中。
2.将需要更新的所有参数放于某个list中,之后将这个list传入optimizer中。
实际情况中两种方法选择一种即可,下方为了方便介绍同时使用了两种方法。
#model.children():返回模型各个‘最外层’(一般是使用同一个sequential搭建的所有层)的生成器
#model.modules():返回模型各个层的生成器,关于这里的层是指所有在网络构造函数中定义的层级结构。
#如果我们只希望更新模型第六个‘最外层’之后的所有参数:
count = 0
para_optim = []
for k in model.children():
count += 1
if count > 6:
for param in k.parameters():
para_optim.append(param)
else:
for param in k.parameters():
param.requires_grad = False
optimizer = optim.RMSprop(para_optim, lr)
使用pytorch我们可以十分方便地对模型中的参数进行提取和管理,一些实用代码可以在这段代码展示的例子中看到:
#若想使用预训练模型中的参数直接更新自己模型的现有层(如果预训练模型中的层数多于自己的模型且有部份层和自己的模型参数完全一样)
vgg16 = models.vgg16(pretrained=True)
pretrained_dict = vgg16.state_dict()
model_dict = model.state_dict()
# 1. filter out unnecessary keys
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
# 2. overwrite entries in the existing state dict
model_dict.update(pretrained_dict)
# 3. load the new state dict
model.load_state_dict(model_dict)
#值得注意的是,optimizer后的params可以接生成器也可以接列表
optimizer = optim.SGD(params=[resnet_model.fc.weight, resnet_model.fc.bias], lr=1e-3)
将训练数据转换为TensorDataset,放入DataLoader中方便后续的使用(validation set不需要放入dataloader,直接传入train函数即可
):pytorch提供了十分方便的Dataloader方法供我们在训练时使用数据,首先需要在函数外部将数据转换为torch能识别的TensorDataset:
# 先转换成torch能识别的 Dataset
torch_dataset = Data.TensorDataset(x,y)
#如果使用经典数据集,以mnist举例:
transform = transforms.ToTensor()
torch_dataset = tv.datasets.MNIST(
root='./data/',
train=True,
download=True,
transform = transform
)
之后只要设置好超参数并调用train()即可。这里提供了部分常用超参数,如之前所说,随着网络的训练每当loss基本收敛时应该:
- 减小学习率
- 增大batchsize
- 从adam转换到sgd
to_train = #你要训练的模型参数,若不使用迁移学习则为model.parameters()
opt = 'adam'
lr = 0.001
epoch_size = 20
batch_size = 50
init = True
loss,acc,loss_val,acc_val = train(torch_dataset,model,to_train,opt,lr,epoch_size,batch_size,init)
跟踪训练:
关于进行跟踪训练的原因与具体分析方法更多说明于上方的实践经验部分,这里主要展示代码。
plot模型在trainset和validation set上的loss与acc曲线
通过train函数返回的四个训练历史数据我们可以直接进行四条曲线的plot。同时,由于在train函数中我们实现了历史数据的实时保存,所以可以通过其他方法读取保存的数据更加方便地进行训练跟踪。
#plot section
plt.plot(range(len(loss)),loss,'b')
plt.plot(range(len(loss_val)),loss_val,'r')
plt.ylim(15,100)
plt.xlabel('number of batchs/##batch_size')
plt.ylabel('averaged loss per sample')
plt.title('the variation of loss with model training')
plt.legend(['training set', 'validation set'])
plt.show()
plt.plot(range(len(acc)),acc,'y')
plt.plot(range(len(acc_val)),acc_val,'r')
plt.ylim(15,100)
plt.xlabel('number of batchs/##batch_size')
plt.ylabel('accuracy')
plt.title('accuracy variation with model training')
plt.legend(['training set', 'validation set'])
plt.show()

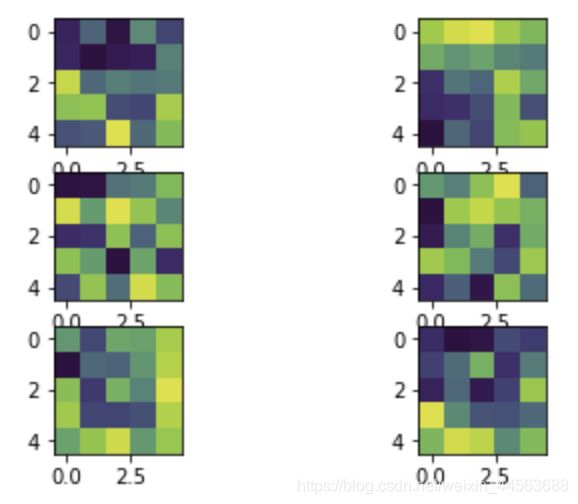
可视化参数
#获得该卷积层所有filter的参数,shape为filter数量 * filter维度 * filter长*宽
dd = list(net.conv1.parameters())[0].detach().numpy()
plt.figure()
for i in range(dd.shape[0]):
plt.subplot(3,2,i+1)
plt.imshow(dd[i,:,:,:].squeeze())
saliency map: 让模型对输入求导,通过累计在各个位置上的梯度大小来定性估计模型对于该部分信息的利用程度,这里提供一段简单代码以及展示部分我在之前项目中利用saliency map技术获得的成果(该模型用于对图像中人物的发色与发型进行分类)。
X_var = Variable(test_1,requires_grad=True)
y_var = Variable(test_1_y)
out = net(X_var)
loss = loss_func(out,y_var)
loss.backward()
grads = X_var.grad
grads = grads.abs()
mx, index_mx = torch.max(grads,1)
saliency = np.moveaxis(mx.data.numpy(),0,-1).squeeze()
plt.imshow(saliency, cmap=plt.get_cmap('gray'))
plt.show()

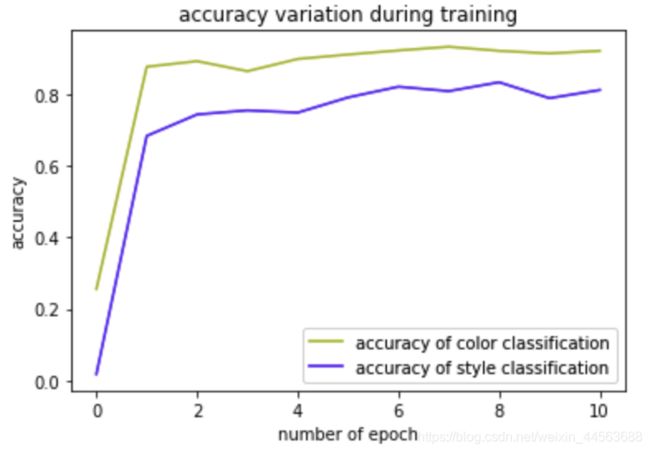
使用降维技术估计模型feature提取层的feature提取能力: 可以运用的降维技术有PCA,LDA,t-SNE等,相关代码与使用经验介绍与博客part(2)中,这里我们只需要将训练后的模型的输出改为分类器的输入,获得这部分特征后使用某种降维手段降至2/3维然后可视化即可。下方展示一部分我对上述发色发型分类模型产生的feature可分性的降维可视化结果(左图/右图为进入发色/发型分类器之中feature的降维可视化图像)。

《机器学习完备流程总结+实践经验细节+代码工具书》博客系列至此完结。之后有计划写类似形式,关于computer vision与图像处理方面技术的系列博客。