详解 TensorFlow 2.0 的符号式 API 和命令式 API
日前,Josh Gordon 在 TensorFlow 官网上发布了一篇博客,详细介绍了符号式 API(symbolic API)和命令式 API(imperative API),并详细介绍了两种样式各自的优点和局限性,以及各自适用于哪些场景。雷锋网 AI 科技评论编译如下。
TensorFlow 2.0 中,我最喜欢的一点就是它提供了多个抽象化(abstraction)级别,让你可以根据自己的项目,挑选出最适合的级别。本文中,我将解读如何权衡创建神经网络的两种样式:
第一种是符号式(symbolic),即你通过操作层次图来创建模型;
第二种是一种命令式(imperative),即你通过扩展类来创建模型。
除了介绍这两种样式,我还会分享关于重要设计和适用性方面需要注意的事项,并在文章最后给大家提供一些有助于选择正确样式的建议。
符号式(Symbolic)API
符号式 API,也称作声明式(Declarative) API。
当我们想到一个神经网络时,我们通常会将心智模型(mental model)用如下图所示的「层次图」来表示:

当我们想到一个神经网络时,我们通常会将心智模型(mental model)用「层次图」来表示(图像是 Inception-ResNet 的图式)
该图可以是有向无环图(DAG),如左边所示;也可以是堆栈图(stack),如右边所示。当我们用符号来创建模型,我们通过对该图的架构进行描述来创建。虽然这个操作听起来带有技术性,但是如果你曾经使用过 Keras 的话,就会惊讶地发现你已经拥有了相关的经验。这里有一个关于用符号来创建模型的简单示例,这个示例中使用的是 Keras 的 Sequential API。

使用 Keras 的 Sequential API 符号式地创建神经网络。你可以点击这里运行这个示例。
在上面这个示例中,我们定义了一个堆栈(a stack of layers),然后使用内置的训练循环(training loop)——model.fit 来对它进行训练。
使用 Keras 创建模型感觉与「把乐高积木拼装在一起」一样简单。为什么这么说?除了匹配心智模型,针对后面将介绍到的技术原因,由于框架能够提供详细错误,使用这种方法来创建模型能够轻易地排除故障。
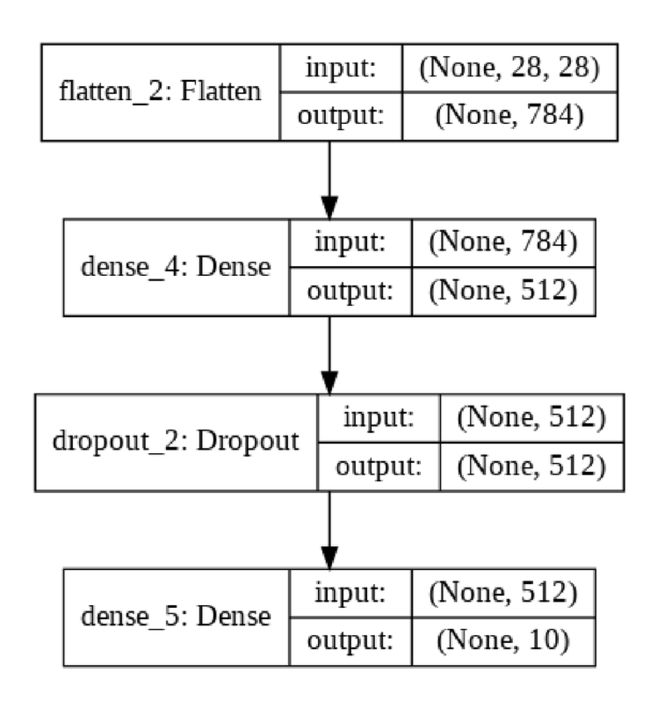
该图展示了通过上述代码创建的模型(使用plot_model创建,你在本文的下一个示例中可以重用该代码片段)
TensorFlow 2.0 还提供了另一个符号式 API :Keras Functional。Sequential 是针对堆栈图的 API;而 Functional,如你所想,是针对 DAG 的 API。

使用 Functional API 创建多输入/多输出模型。
Functional API 是一种创建更灵活的模型的方法,可以操作非线性拓扑、共享层的模型以及有多个输入或输出的模型。一般来说,Functional API 是一个用来创建这些层次图的工具集,我们现在也正在为大家准备一些新教程,来教大家使用这些 API。
另外也有一些其他的符号式 API,这些 API 你们可能也使用过。例如,TensorFlow v1 (及 Theano) 提供了一个层级更低得多的 API。当进行编译并执行时,你可以通过设计一个 ops 图来创建模型。有时候,使用这种 API 可能会让你感觉像是在与一个编译器进行直接的互动。对于很多人(包括作者)来说,该 API 是比较难使用的。
相比之下,使用 Keras 的 Functional API,抽象化级别可以匹配心智模型:像乐高拼图一样将层次图拼接起来。这种 API 使用起来感觉会比较自然,它也是我们在 TensorFlow 2.0 中进行标准化的模型创建方法之一。接下来我将介绍另一种 API 样式(同时,这种样式你也可能使用过,或者你可能不久后会尝试这种 API)。
命令式(Imperative)API
命令式 API,也称作模型子类化(Model Subclassing) API。
在命令式 API 中,你要像编写 NumPy 一样编写模型。用这种 API 创建模型感觉像是在开发面向对象的 Python。这里有一个关于子类化模型的简单示例:

使用命令式 API 为一个有文字说明的图片创建模型(注意:该示例目前正在更新)。
从一个开发者的角度,它工作的方法就是扩展由框架定义的模型类别,将模型中的层实例化,然后命令式地编写下模型的正向传递(forward pass),而反向传递(backward pass)是自动生成的。
TensorFlow 2.0 支持使用现成的 Keras 的子类化 API 来创建模型。与 Sequential API 和 Functional API 一样,它也是使用 TensorFlow 2.0 创建模型时推荐使用的方法之一。
虽然这种方法在 TensorFlow 来说还比较新,但是你会惊讶地发现早在 2015 年 Chainer 就对它进行了介绍(时光飞逝!)自那以后,许多框架都采用了相似的方法,包括 Gluon、PyTorch 和 TensorFlow (以及 Keras Subclassing)。令人惊讶地是,在不同的框架中使用这种样式所编写的代码看上去非常相似,研究者可能都难以分清哪些代码是哪个框架的!
这种样式能给开发人员带来巨大的灵活性,不过也会带来一些不明显的适用性和维护成本。稍后我们会更详细地讨论这一点。
训练循环(Training Lloop)
自定义的模型无论是使用 Sequential API、Functional API 还是使用子类化样式,都可以用两种方式进行训练:
一种是使用内建的训练路径和损失函数(第一个示例讲到的,我们使用的是 model.fit 和 model.compile);
另一种是定制更复杂的训练循环(例如,当你想要自行编写梯度裁剪代码时)或损失函数,你可以按照以下方法轻易实现:
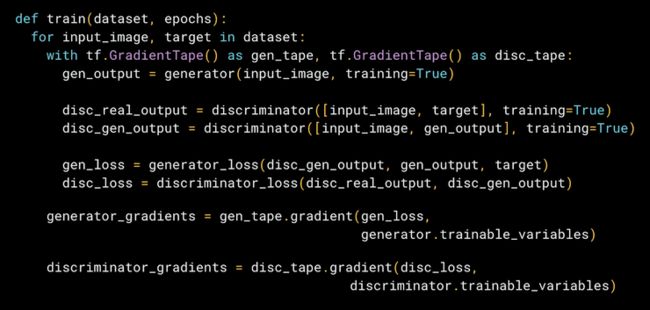
为 Pix2Pix 定制训练循环和损失函数的示例
将这些方法对外开放是非常重要的,使用它们来降低代码复杂性以及维护成本都非常方便。一般而言,如果增加复杂度是有帮助的,那你就增加并将其利用起来;没必要的话,就直接使用内建的方法,将你的时间更多地花在你的研究或者项目上。
既然我们已经对符号式 API 和命令式 API 都建立起了认知,接下来就让我们看一下两者各自的优劣势。
符号式 API 的优势和局限性
优势
使用符号式 API 创建的模型,就是一个类似图形的数据架构,这就意味着你的模型可以接受监测或者进行汇总。
-
你可以将模型当成图像来为其绘制图表(使用 keras.utils.plot_model);或者简单地使用 model.summary() 来呈现层、权重以及形状的描述。
同样地,在将层拼接在一起时,开发库的设计者可以运行扩展的层兼容性检查(在创建模型时和执行模型之前)。
这类似于在编译器中进行类型检查,可以极大地减少开发者的错误。
大多数的故障排除都会在模型自定义阶段而不是执行期间进行。你可以保障所有编译的模型都能正常运行,这也加速了迭代,并让故障排除变得更简单。
符号式模型提供了一个一致的 API,这就使得这些模型的重复使用和共享变得简单。例如,在迁移学习中,你可以访问中间层的神经元,从而从现有的神经元中创建新的模型,就像这样:

符号式模型由可自然地进行复制和克隆的数据架构进行定义。
例如,Sequential API 和 Functional API 可以提供 model.get_config(),model.to_json(),model.save(),clone_model(model),同时仅凭借数据架构就能够重新创建同样地模型(而不需要访问用来定义和训练模型的原始代码)。
虽然精心设计的 API 应该跟神经网络的心智模型匹配,但是跟我们作为一个程序员所有的心智模型进行匹配也同样重要。对于我们大多数程序员来说,这种心智模型就是命令式的编程样式。在符号式 API 中,你操作「声明式的张量」(这些张量是没有值的)来创建图表。Keras 的 Sequential API 和 Functional API「感觉像」命令性的,它们是在开发者没有意识到他们在用符号定义模型的情况下被设计出来的。
局限性
符号式 API 的当前一代,可以很好地适用于有向无环图的模型创建,这可以满足绝大多数实际应用的需要,然而现在也有一些特例无法匹配这个简洁的抽象化,例如,树形循环神经网络和递归神经网络等动态网络。
这也是为什么 TensorFlow 要同时还提供命令式的模型创建 API 样式(上文中提到的子类化 API)。无论是使用 Sequential API 还是 Functional API,你都会用到所有熟悉的层、初始化器以及优化器。同时,这两类 API 是完全互操作的,因此你可以混合并且搭配两者使用(例如将一种模型嵌套到另一种模型中)。你可以采用一个符号式模型并在子类化模型中将它用作层,反之亦然。
命令式 API 的优势和局限性
优势
正向传递(forward pass)以命令式的方法编写,这就使得用自己的实现来替换掉通过开发库实现的部分(例如一层、一个神经元后者一个损失函数)变得很容易。这种方式的编程也非常自然,并且是深入了解深度学习的基本要点的不错的方法。
这也让你快速地尝试新想法变得很容易(深度学习开发工作流会变得与面向对象的 Python 一样),同时对于研究人员来说尤其有帮助。
也可以很轻易地使用 Python 指定模型正向传递中的任意控制流。
命令式 API 给予了你最大的灵活性,但同时也要付出代价。我喜欢用这种样式来写代码,但还是想花点时间来强调一下它的局限性(意识到要对这种方法的优势和局限性进行权衡是很不错的)。
局限性
当使用命令式 API 使,模型是由某个类别方法来进行定义的。这样的话,模型就不再是一个清晰的数据架构,而是一个不透明的字节码。这种 API 样式所获得的灵活性是以可用性和可重用性换来的。
故障排除发生在执行期间,而不是在定义模型之时。
使用这一 API 样式时,由于几乎不会对输入或者层间兼容性进行检查,因此大量的故障排除压力就从框架上转移到了开发者身上。
命令式模型很难进行重复利用。例如你无法使用一个一致的 API 去访问中间层或神经元。
相反地,提取神经元的方法就是采用一种新的调用(或者前进)方法来编写一个新的类别。最开始的时候可能会觉得这个操作有趣又简单,但是如果没有标准的话就会积累成技术债(tech debt)。
命令式模型也很难进行检测、复制和克隆。
例如,model.save(), model.get_config(),以及 clone_model 对于子类化的模型是不起作用的,而 model.summary() 也只能给你层的列表(并且不会提供任何关于它们怎样进行连接的信息,因为这些信息是访问不了的)。
机器学习系统中的技术债(Technical debt)
记住:模型创建仅仅是机器学习实际应用中的一个小小的部分。关于这个主题,有一个我非常喜欢的描述:模型本身(指定层、训练循环等的代码部分)就是机器学习中央的一个小盒子。

现实中的机器学习系统仅有一小部分是由机器学习代码组成的,就像上图中间的这个小块所显示的一样。来源:Hidden Technical Debt in Machine Learning Systems
符号式定义的模型在可重用性、故障排除以及测试方面具有优势,例如,在教授期间,如果学生使用的是 Sequential API,我立刻就能排除故障;如果他们使用的是子类化的模型(不管框架),排除故障需要花费的时间就更长(故障会更不易察觉,类型也更多)。
总结
TensorFlow 2.0 直接支持符号式 API 和命令式 API 两种样式,因此大家可以选择最适合自己项目的抽象化(复杂性)层级。
如果你的目标是易用、低预算,同时你倾向于将模型考虑称层次图,那就使用 Keras 的 Sequential API 或者 Functional API (就像拼装乐高积木一样) 和内建的训练循环。这种方法适用于大多数问题。
如果你偏好于将模型考虑成面向对象的 Python/Numpy 开发者,同时有限考虑模型的灵活性和可破解性,Keras 的 Subclassing 这样的 API 会比较适合你。
我希望这篇总结文对大家有所帮助,感谢大家的阅读!如果想要了解关于 TensorFlow 2.0 栈以及其他模型创建 API 的更多信息,可前往阅读这篇文章。想要对 TensorFlow 和 Keras 之间的关系有更多了解,可前往这里。
via:https://medium.com/tensorflow/what-are-symbolic-and-imperative-apis-in-tensorflow-2-0-dfccecb01021