Mac单机Hadoop2.7下安装Spark2.2+配置SparkSQL查询Hive表+spark-sql CLI 查询
下面简单记录mac单机spark安装测试的过程
- 已安装好单机的伪分布式Hadoop,见Mac单机Hadoop安装备忘
- 已安装好单机的hive,见Mac-单机Hive安装与测试
- 单机Mac安装spark并做简单yarn模式shell测试
- 配置SparkSQL查询Hive
- spark-sql CLI 查询Hive
一、安装Spark
1-下载安装scala
https://www.scala-lang.org/download/
移动至/Users/用户名xxx/Software/scala-2.10.4下
tar -zxvf scala-2.10.4.tgz
配置环境变量
vi ~/.bash_profile
export SCALA_HOME=/Users/用户名xxx/Software/scala-2.10.4
export PATH=PATH:PATH:{SCALA_HOME}/bin
source
测试
scala -version
2-下载安装Spark
http://spark.apache.org/downloads.html
下载spark-2.2.1-bin-hadoop2.7.tgz.
解压至/Users/用户名xxx/Documents/software/spark
spark-2.2.1 文件夹及子文件的和用户设为hadoop的安装用户如用户名xxx
chown -R 用户名xxx spark-2.2.1
修改conf文件夹spark-env.sh和slaves
cp spark-env.sh.template spark-env.sh
在spark-env.sh添加
export SCALA_HOME=/Users/用户名xxx/Software/scala-2.10.4
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.121-2.6.8.0.el7_3.x86_64
export SPARK_MASTER_IP=localhost
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/data/hadoop-2.7.3/etc/hadoop
具体可以执行下面的命令
chown -R 用户名比如用户名xxx spark2.2.1
cp spark-env.sh.template spark-env.sh
echo "export SCALA_HOME=/Users/用户名xxx/Software/scala-2.10.4" >> spark-env.sh
echo "export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_151.jdk/Contents/home" >> spark-env.sh
echo "export SPARK_MASTER_IP=localhost" >> spark-env.sh
echo "export SPARK_WORKER_MEMORY=1g" >> spark-env.sh
echo "export HADOOP_CONF_DIR=/Users/用户名xxx/Documents/software/hadoop/hadoop-2.7.4/etc/hadoop" >> spark-env.sh
这里单机不用配置slaves
将hadoop的core-site.xml和hdfs-site.xml拷贝到spark的conf目录,以便可以访问hdfs文件
二、启动Spark并做简单yarn模式的shell测试
1-启动Spark
在sbin文件夹下执行, start-all.sh
localhost:~/Documents/software/spark/spark2.2.1/sbin$ jps.
39793 Master
39826 Worker
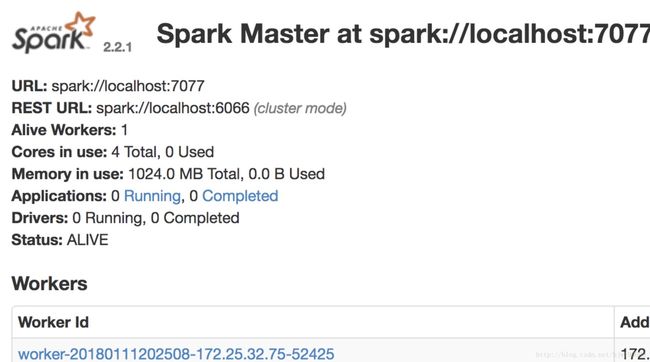
2-WebUI
访问:http://localhost:8080/
已经向student表中load数据,详细见Mac-单机Hive安装与测试
hive> load data local inpath '/Users/hjw/Documents/software/hive/student.txt' into table hive_test.student;
Loading data to table hive_test.student
OK
Time taken: 0.386 seconds
查询数据
hive> select * from hive_test.student;
OK
1001 zhangsan
1002 lisi
Time taken: 1.068 seconds, Fetched: 2 row(s)
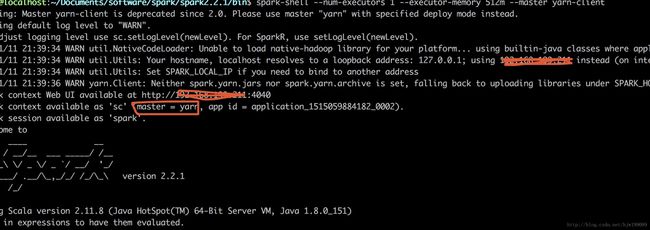
3-启动yarn mode的spark-shell
yarn模式启动spark-shell
spark2.2.1/bin$ spark-shell --num-executors 1 --executor-memory 512m --master yarn-client
以上如有问题使用:spark-shell --master yarn --deploy-mode client --num-executors 1 --executor-memory 512m
参见:Running Spark on YARN
4-执行测试
在spark-shell中执行
val file=sc.textFile("hdfs://localhost:9000/user/hive/warehouse/hive_test.db/student")
val rdd = file.flatMap(line => line.split("\t")).map(word => (word,1)).reduceByKey(_+_)
rdd.take(10)
scala> val file=sc.textFile("hdfs://localhost:9000/user/hive/warehouse/hive_test.db/student")
file: org.apache.spark.rdd.RDD[String] = hdfs://localhost:9000/user/hive/warehouse/hive_test.db/student MapPartitionsRDD[39] at textFile at <console>:24
scala> val rdd = file.flatMap(line => line.split("\t")).map(word => (word,1)).reduceByKey(_+_)
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[42] at reduceByKey at <console>:26
scala> rdd.take(10)
res12: Array[(String, Int)] = Array((zhangsan,1), (1001,1), (1002,1), (lisi,1))
5-退出spark-shell
退出spark-shell,输入 “:quit”
###6-关闭spark
/software/spark/spark2.2.1/sbin$ ./stop-all.sh
localhost: stopping org.apache.spark.deploy.worker.Worker
stopping org.apache.spark.deploy.master.Master
三、配置SparkSQL读取Hive数据
为了让Spark能够连接到Hive数据仓库,需要将Hive中的hive-site.xml文件拷贝到Spark的conf目录下,Spark通过这个配置文件找到Hive的元数据,完成数据读取。
1-已安装单机Hive
见Mac-单机Hive安装与测试
启动hive的meta sever
hive --service metastore &
启动hive shell查询数据
hive> select * from student;
OK
1001 zhangsan
1002 lisi
Time taken: 1.164 seconds, Fetched: 2 row(s)
2-将Hive中hive-site.xml文件拷贝到Spark的conf目录
- 将Hive中的hive-site.xml文件拷贝到Spark的conf目录
- 重新启动spark,在sbin文件夹下 执行:start-all.sh
3-启动spark-shell
yarn模式启动spark-shell,spark2.2.1/bin$ spark-shell --num-executors 1 --executor-memory 512m --master yarn-client
4-SparkSQL查询Hive数据
scala> val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
sqlContext: org.apache.spark.sql.hive.HiveContext = org.apache.spark.sql.hive.HiveContext@27210a3b
scala> sqlContext.sql(" SELECT * FROM hive_test.student")
18/01/11 22:15:00 WARN conf.HiveConf: HiveConf of name hive.metastore.hbase.aggregate.stats.false.positive.probability does not exist
18/01/11 22:15:00 WARN conf.HiveConf: HiveConf of name hive.llap.io.orc.time.counters does not exist
18/01/11 22:15:00 WARN conf.HiveConf: HiveConf of name hive.tez.task.scale.memory.reserve-fraction.min does not exist
18/01/11 22:15:00 WARN conf.HiveConf: HiveConf of name hive.orc.splits.ms.footer.cache.ppd.enabled does not exist
18/01/11 22:15:00 WARN conf.HiveConf: HiveConf of name hive.server2.metrics.enabled does not exist
。。。。。
18/01/11 22:15:01 WARN conf.HiveConf: HiveConf of name hive.msck.path.validation does not exist
18/01/11 22:15:01 WARN conf.HiveConf: HiveConf of name hive.tez.task.scale.memory.reserve.fraction does not exist
18/01/11 22:15:01 WARN conf.HiveConf: HiveConf of name hive.compactor.history.reaper.interval does not exist
18/01/11 22:15:01 WARN conf.HiveConf: HiveConf of name hive.tez.input.generate.consistent.splits does not exist
18/01/11 22:15:01 WARN conf.HiveConf: HiveConf of name hive.server2.xsrf.filter.enabled does not exist
18/01/11 22:15:01 WARN conf.HiveConf: HiveConf of name hive.llap.io.allocator.alloc.max does not exist
res0: org.apache.spark.sql.DataFrame = [id: int, name: string]
以上有错误,报错没有启动hive server,另开一个终端执行:hive --service hiveserver2 &,启动hiveserver2
t:~$ hive --service hiveserver2 &
[1] 43667
spark-shell,重新查询Hive
scala> sqlContext.sql(" SELECT * FROM hive_test.student")
res1: org.apache.spark.sql.DataFrame = [id: int, name: string]
scala> sqlContext.sql(" SELECT * FROM hive_test.student").collect().foreach(println)
[1001,zhangsan]
[1002,lisi]
四、spark-sql CLI 查询
将hive-site.xml复制到spark的conf下,执行
下载mysql-connector-java-5.1.45-bin.jar,
https://dev.mysql.com/downloads/file/?id=474257
放在了/Users/xxx/Documents/software/spark/spark2.2.1/classpath
.spark2.2.1/bin$ spark-sql --driver-class-path /Users/xxx/Documents/software/spark/spark2.2.1/classpath/mysql-connector-java-5.1.45-bin.jar
尝试添加--driver-class-path 也可以,比如直接执行spark-sql,或者spark-sql --master yarn
在启动spark-sql时,如果不指定master,则以local的方式运行,master既可以指定standalone的地址,也可以指定yarn;
当设定master为yarn时(spark-sql --master yarn)时,可以通过http://hadoop000:8088页面监控到整个job的执行过程;
注:如果在$SPARK_HOME/conf/spark-defaults.conf中配置了spark.master spark://hadoop000:7077,那么在启动spark-sql时不指定master也是运行在standalone集群之上。
进入spark-sql
spark-sql> select * from hive_test.student;
。。。
1001 zhangsan
1002 lisi
Time taken: 3.306 seconds, Fetched 2 row(s)
Hive 2.x 可能出现的问题
启动spark-sql报错Caused by: MetaException(message:Version information not found
开始报can not access hivemeta
后来多次尝试可以了,什么原因???
INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
---------------
原文:https://blog.csdn.net/wqhlmark64/article/details/77962263
WARN metadata.Hive: Failed to access metastore. This class should not accessed in runtime.
org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
.......
Caused by: java.lang.reflect.InvocationTargetException
Caused by: MetaException(message:Version information not found in metastore. )
因为版本信息原因,sqark-sql不能访问hive的metastore。回顾环境和所做过的配置,
将hive的hive-site.xml 拷贝到了spark/conf下,并在spark-env.sh中设置了$HIVE_HOME,
只可能出现在spark与hive的兼容方面。定位到了hive-site.xml中的这个配置项,默认是true,即要做hive metastore schema的验证。改为false后,spark-sql启动正常,不再报错。
hive.metastore.schema.verification
true
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
同时,注意到spark-sql启动后的一句日志,对应的hive版本是1.2.1,看来确实是现在使用的spark版本是基于hive 1.2.1兼容的,而环境中安装的hive是2.1.1的,确实是兼容性所致。