Hadoop权威指南——天气情况实例
说实话,为了实验这第一个hadoop实例真的是看了很多的视频,实验了很多的博客,大部分的均使用了maven,但是我在看得视频没有用maven,并且是直接在本地系统,也就是hadoop三个模式之一的独立模式下进行的,那么确实有很多的例子均不太能使用,今天给自己记录一下这第一个实例,同时希望能给一些人帮助。
我使用的是Ubuntu16.0.4的系统版本,eclipse作为开发工具,hadoop版本是hadoop2.7.4,在这里只是都说一下,不代表只能使用同样版本才能做到同样的事情。
在项目伊始我了解到要hadoop在eclipse上运行可以使用一个插件,hadoop-eclipse-plugin-2.7.3. jar,这个jar包很多地方都是要积分,并且推荐使用与hadoop版本相同的版本,我没有使用同样的,依然可以使用,不过最好使用相同版本,不同版本的不方便之处我还没有看到,日后看到了会在文后补充。
链接:https://pan.baidu.com/s/1T-YSXtABNv3Hs9URZtwk1w 密码: bhus
而后先将此jar包放在eclipse—>plugins(plugins文件夹里面的jar包是支撑eclipse运行的,我们放进去的称为拓展包或插件)中后再启动eclipse,在window—>preferences中可以看到Hadoop Map/Reduce目录项,在右面输入Hadoop installation directory作为默认hadoop目录。
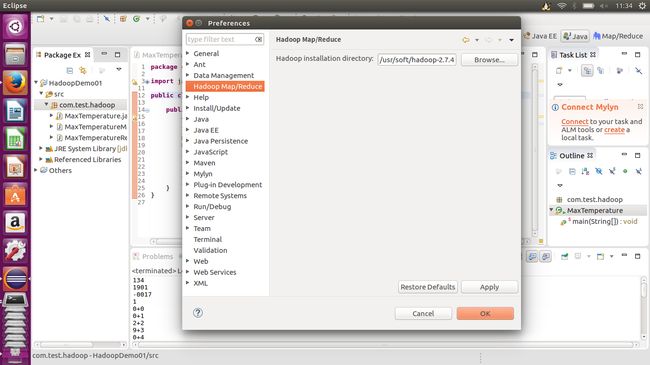
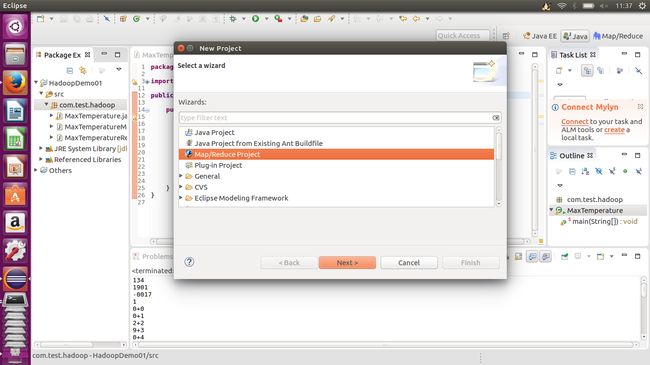
有了这个插件后,在创建项目的时候我们可以选择创建一个Map/Reduce Project。
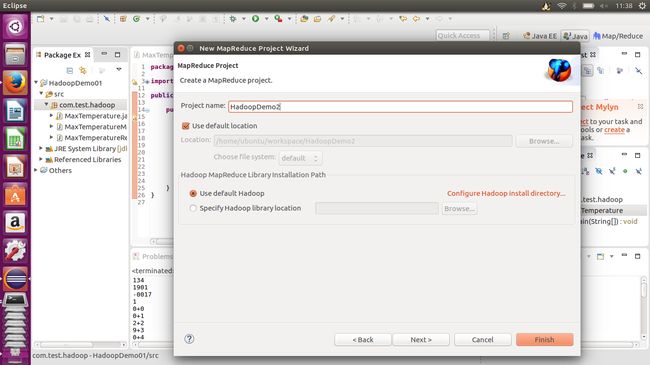
创建后输入Project name并使用默认hadoop包。
点击Finish便可以看到已经创建好的项目,并且可以看到不用自己导入包,插件通过路径已经将hadoop使用的必须包导入。
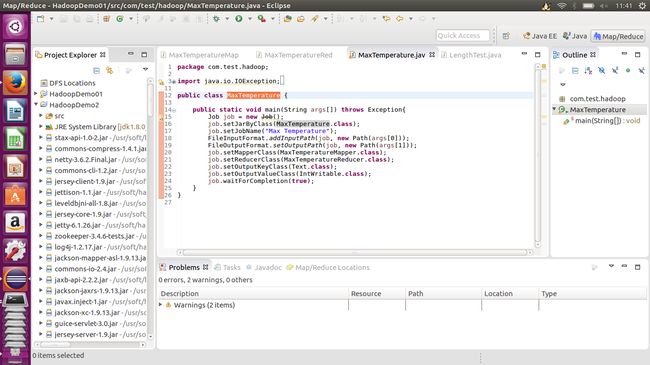
之后的一些操作均属于eclipse使用基础,在src中创建class之类,我就直接贴代码了,不做过多解释。
创建MaxTemperatureMapper类
package com.test.hadoop;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/*
* Mapper
*/
public class MaxTemperatureMapper extends
Mapper {
private static final int MISSING = 9999;
// Map
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(89) == '+') {
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
创建MaxTemperatureReducer类
package com.test.hadoop;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/*
* Reducer
*/
public class MaxTemperatureReducer extends
Reducer {
@Override
protected void reduce(Text keyin,Iterable values,Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for(IntWritable value:values){
maxValue = Math.max(maxValue,value.get());
}
context.write(keyin, new IntWritable(maxValue));
}
}
创建MaxTemperature主类
package com.test.hadoop;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MaxTemperature {
public static void main(String args[]) throws Exception{
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max Temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
}
}
有了这些代码之后便是将这个项目导出成jar包,在项目名上右键export成java—>jar file,而后将文件打包,选择项可以看到自创包中的.java结尾的文件都是在列的,在下面点击browse选择jar file的路径及对应名称。
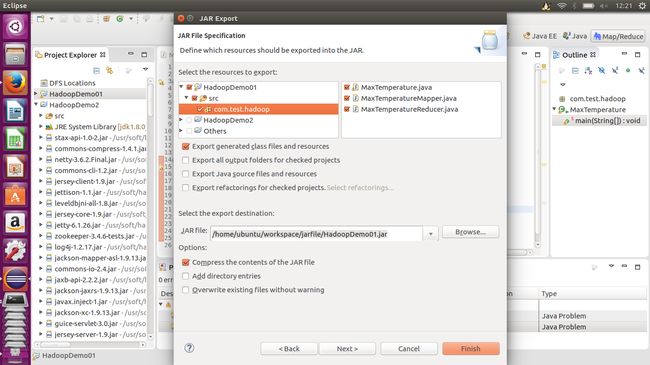
这个页面什么也不做,均为默认选项。

在下面的这个页面选择的是主类,在项目中main函数的所在,然后便是按Finish等待打包完成。
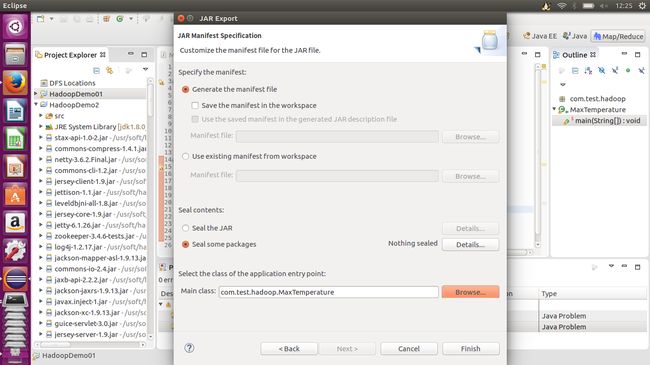
由于使用的是独立模式进行实例,不需要hadoop启动任何进程,在终端使用命令,先导入jar包的路径,注意改为自己的文件名。
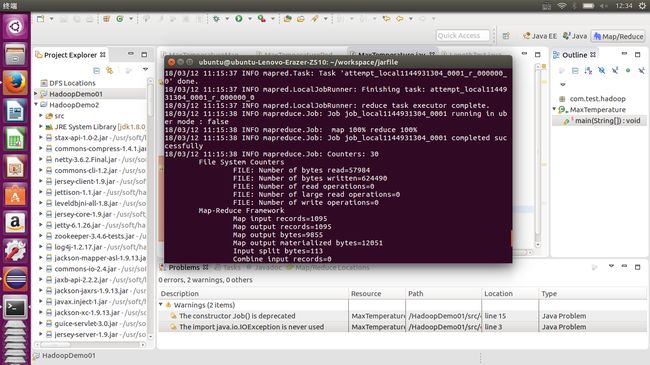
export HADOOP_CLASSPATH=HadoopDemo01.jar hadoop com.test.hadoop.MaxTemperature file:///home/ubuntu/workspace/029070-99999-1901.gz /home/ubuntu/workspace/Output
可以看到hadoop命令后接的是包名和主类名,后面的内容为输入项和输出项,输入内容有一个file:///是因为是本地独立模式,使用的是本地文件。输出文件夹由于hadoop的原因不能自己创建,一定要通过使用项目进行创建,否则会报错。任务完成可以回看终端map和reduce的过程,最终有map100%,reduce100%和job completed successfully字样。
在对应的文件夹中可以看到两个生成文件,part-r-0000是任务结果,_SUCCESS是任务成功标志。
至此hadoop项目的第一个实例完成。
在这整个项目的过程中可以看很多大佬的代码详解,对于每一行代码的解析都很重要,对于初学者的我来说受益匪浅,在此也感谢各位能够将自己的成功项目经验放在博客中供大家学习。望大家能多提意见,我也会在测试后对原文进行更改或补充。