Mybatis源码解析之分页插件pagehelper分析
Mybatis源码解析之核心类分析
Mybatis源码解析之初始化分析
Mybatis源码解析之执行流程解析
Mybatis源码解析之数据库连接和连接池
Mybatis源码解析之事务管理
Mybatis源码解析之缓存机制(一):一级缓存
Mybatis源码解析之缓存机制(二):二级缓存
Mybatis源码解析之插件机制
Mybatis源码解析之mapper接口的代理模式
Mybatis源码解析之DefaultResultSetHandler的handleResultSets方法解析
Mybatis源码解析之Spring集成mybatis-spring分析
Mybatis源码解析之懒加载(一):配置和ResultLoaderMap
Mybatis源码解析之懒加载(二):ProxyFactory
Mybatis源码解析之懒加载(三):序列化
Mybatis源码解析之SpringBoot集成mybatis-spring-boot-starter分析
pagehelper是在日常开发中比较常使用的一个分页插件,本文将针对其实现原理进行简单的分析,若无特殊说明,分析的源码基于com.github.pagehelper:pagehelper:5.1.2。
一、QueryInterceptor 规范
QueryInterceptor是pagehelper分页插件的作者提出的Executor层面的插件规范,其demo代码如下:
@Override
public Object intercept(Invocation invocation) throws Throwable {
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
//由于逻辑关系,只会进入一次
if(args.length == 4){
//4 个参数时
boundSql = ms.getBoundSql(parameter);
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
//6 个参数时
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
//TODO 自己要进行的各种处理
//注:下面的方法可以根据自己的逻辑调用多次,在分页插件中,count 和 page 各调用了一次
return executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
简单的描述一下这个规范。
由于Executor层面的query方法有两个,分别是4个参数的和6个参数的。
Executor是使用delegate委派模式实现的,其内部的query方法的调用顺序一般是这样的:
Executor的4个参数的query方法 —> Executor的6个参数的query方法
如果同时有多个Executor层面的query方法的插件,要保证每个插件都能拦截成功,则必须第一个插件针对4个参数的query方法进行拦截,后续的插件针对6个参数的query方法进行拦截,
也就是说,随着插件在mybatis中设置的执行顺序不同,其需要拦截的query方法是不固定的。
因此,QueryInterceptor规范要求如果要对Executor层面的query方法进行拦截,则必须对两个方法都进行拦截。
对于QueryInterceptor的详细解释,可以查看文档https://github.com/pagehelper/Mybatis-PageHelper/blob/master/wikis/zh/Interceptor.md。
二、pagehelper配置项

其中,除了dialect、countSuffix和msCountCache以外,其它配置都只有在dialect为默认值时生效。
另外,在个人看来,一些配置项实际上很鸡肋。譬如offsetAsPageNum的一参两用,这样反而会混淆了offset参数的概念。reasonable的参数校验和处理正常情况下在业务代码中就处理好了,没有必要在分页插件中去处理。
在大多数的场景下,我们只需要配置了helper-dialect知名数据库类型就可以满足业务需要。
三、PageInterceptor
PageInterceptor是pagehelper插件中正式的拦截类,对Executor层次的两个query方法进行拦截。
其执行流程大致如下:
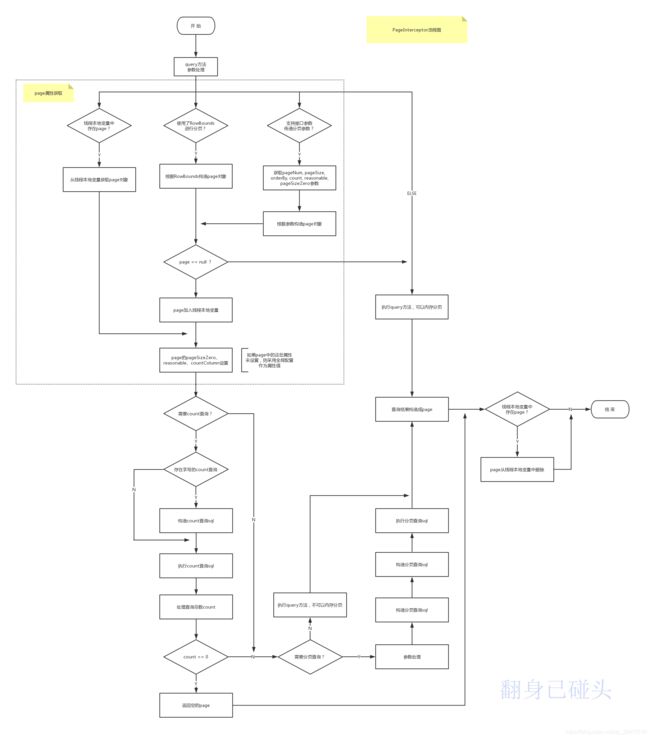
@Override
public Object intercept(Invocation invocation) throws Throwable {
try {
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
//由于逻辑关系,只会进入一次
if(args.length == 4){
//4 个参数时
boundSql = ms.getBoundSql(parameter);
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
//6 个参数时
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
List resultList;
//调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//反射获取动态参数
String msId = ms.getId();
Configuration configuration = ms.getConfiguration();
Map additionalParameters = (Map) additionalParametersField.get(boundSql);
//判断是否需要进行 count 查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
String countMsId = msId + countSuffix;
Long count;
//先判断是否存在手写的 count 查询
MappedStatement countMs = getExistedMappedStatement(configuration, countMsId);
if(countMs != null){
count = executeManualCount(executor, countMs, parameter, boundSql, resultHandler);
} else {
countMs = msCountMap.get(countMsId);
//自动创建
if (countMs == null) {
//根据当前的 ms 创建一个返回值为 Long 类型的 ms
countMs = MSUtils.newCountMappedStatement(ms, countMsId);
msCountMap.put(countMsId, countMs);
}
count = executeAutoCount(executor, countMs, parameter, boundSql, rowBounds, resultHandler);
}
//处理查询总数
//返回 true 时继续分页查询,false 时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
//判断是否需要进行分页查询
if (dialect.beforePage(ms, parameter, rowBounds)) {
//生成分页的缓存 key
CacheKey pageKey = cacheKey;
//处理参数对象
parameter = dialect.processParameterObject(ms, parameter, boundSql, pageKey);
//调用方言获取分页 sql
String pageSql = dialect.getPageSql(ms, boundSql, parameter, rowBounds, pageKey);
BoundSql pageBoundSql = new BoundSql(configuration, pageSql, boundSql.getParameterMappings(), parameter);
//设置动态参数
for (String key : additionalParameters.keySet()) {
pageBoundSql.setAdditionalParameter(key, additionalParameters.get(key));
}
//执行分页查询
resultList = executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, pageKey, pageBoundSql);
} else {
//不执行分页的情况下,也不执行内存分页
resultList = executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, cacheKey, boundSql);
}
} else {
//rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
dialect.afterAll();
}
}
四、注意点
下面针对pagehelper使用过程中的一些注意点进行分析:
(1)id以“_COUNT”结尾的statement
-
需要分页的sql的statementId不要以“_COUNT”结尾
如果需要分页的sql的statementId以“_COUNT”结尾,pagehelper会抛出异常,见PageHelper#skip(MappedStatement, Object, RowBounds)if(ms.getId().endsWith(MSUtils.COUNT)){ throw new RuntimeException("在系统中发现了多个分页插件,请检查系统配置!"); } -
手写的count的sql的statementId = 需要分页的sql的statementId + “_COUNT”
pagehelper以“_COUNT”结尾作为count的sql的标志,见PageInterceptor#intercept(Invocation)String countMsId = msId + countSuffix; Long count; //先判断是否存在手写的 count 查询 MappedStatement countMs = getExistedMappedStatement(configuration, countMsId);
(2)mapper接口的方法参数中含有“pageNum, pageSize, orderBy”等关键字
当supportMethodsArguments时,pagehelper可能会根据mapper接口的方法参数中含有的“pageNum, pageSize, orderBy”等关键字建立Page。
如果不需要pagehelper进行分页,而sql查询中有需要排序或者只读取部分数据,不要在mapper接口中使用pageNum, pageSize, orderBy传递参数。
代码见PageObjectUtils#getPageFromObject(Object, boolean)
public static Page getPageFromObject(Object params, boolean required) {
int pageNum;
int pageSize;
MetaObject paramsObject = null;
if (params == null) {
throw new PageException("无法获取分页查询参数!");
}
if (hasRequest && requestClass.isAssignableFrom(params.getClass())) {
try {
paramsObject = MetaObjectUtil.forObject(getParameterMap.invoke(params, new Object[]{}));
} catch (Exception e) {
//忽略
}
} else {
paramsObject = MetaObjectUtil.forObject(params);
}
if (paramsObject == null) {
throw new PageException("分页查询参数处理失败!");
}
Object orderBy = getParamValue(paramsObject, "orderBy", false);
boolean hasOrderBy = false;
if (orderBy != null && orderBy.toString().length() > 0) {
hasOrderBy = true;
}
try {
Object _pageNum = getParamValue(paramsObject, "pageNum", required);
Object _pageSize = getParamValue(paramsObject, "pageSize", required);
if (_pageNum == null || _pageSize == null) {
if(hasOrderBy){
Page page = new Page();
page.setOrderBy(orderBy.toString());
page.setOrderByOnly(true);
return page;
}
return null;
}
pageNum = Integer.parseInt(String.valueOf(_pageNum));
pageSize = Integer.parseInt(String.valueOf(_pageSize));
} catch (NumberFormatException e) {
throw new PageException("分页参数不是合法的数字类型!");
}
Page page = new Page(pageNum, pageSize);
//count查询
Object _count = getParamValue(paramsObject, "count", false);
if (_count != null) {
page.setCount(Boolean.valueOf(String.valueOf(_count)));
}
//排序
if (hasOrderBy) {
page.setOrderBy(orderBy.toString());
}
//分页合理化
Object reasonable = getParamValue(paramsObject, "reasonable", false);
if (reasonable != null) {
page.setReasonable(Boolean.valueOf(String.valueOf(reasonable)));
}
//查询全部
Object pageSizeZero = getParamValue(paramsObject, "pageSizeZero", false);
if (pageSizeZero != null) {
page.setPageSizeZero(Boolean.valueOf(String.valueOf(pageSizeZero)));
}
return page;
}
(3)除了部分简单sql外,建议手写count查询
在pagehelper中,count查询的sql是根据需要分页的sql拼接而来的,拼接格式为:
select count(0) from (需要分页的sql) tmp_count
代码详见CountSqlParser#getSimpleCountSql(String, String)
public String getSimpleCountSql(final String sql, String name) {
StringBuilder stringBuilder = new StringBuilder(sql.length() + 40);
stringBuilder.append("select count(");
stringBuilder.append(name);
stringBuilder.append(") from (");
stringBuilder.append(sql);
stringBuilder.append(") tmp_count");
return stringBuilder.toString();
}
虽然在CountSqlParser#getSmartCountSql(String, String)中会对一些count sql做优化,但优化的往往是简单sql。
类似select count(0) from (需要分页的sql) tmp_count的格式的sql在很多场景下查询速度都不快,因此有必要手写count查询。
关于pagehelper的更多信息,可以查询文档https://github.com/pagehelper/Mybatis-PageHelper/blob/master/wikis/zh/HowToUse.md