自然语言处理-Word2Vector学习笔记
目录
自然语言处理与深度学习
语言模型
词向量
神经网络模型
CBOW和Skip-gram
gensim库的应用简介
自然语言处理与深度学习
word2vec是自然语言处理中的一个非常重要的模型。word2vec是指把一个词转化成向量。我们为什么要把词转化成向量呢?通常情况下我们在做机器学习任务的时候,我们的输入是一个特征数据,特征数据是指数值型的东西,因为我们的机器是认识这些数值型的数据的,但是在我们的任务中,我们拿到的数据不光是数值型的,还有字符型的或者文本型的数据,对于这样的数据来说,为了让计算机认识这些数据,我们需要把这些词转化成向量,再把这些向量拼接在一起,把这些向量输入,那么我们就可以让计算机知道这些文本表达了什么含义了。自然语言处理最常见的几类应用如下图所示:

在自然语言处理中,比较重要的就是深度学习。深度学习基础的模型是神经网络,比如你想让你的机器学到东西,你给它指定了一个网络,在网络里,你给它指定了一个学习目标,比如说你定义好了一个损失函数,那么在神经网络的优化过程当中,它就会不断的朝着一个可优化的方向前进,如下图中的右图所示,最低点就是损失函数优化的目标。
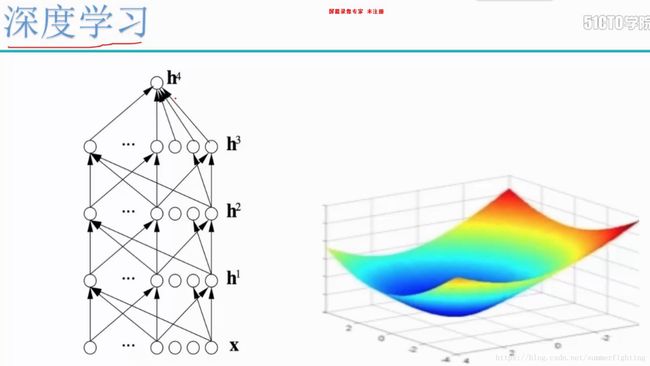
为什么需要研究深度学习,如下图所示:

语言模型
上面简述了自然语言处理和深度学习。下面我们来说一下语言模型,如下图所示:

机器翻译、拼写纠错和智能问答等在做一件事情的时候,都会涉及到语言模型,就是说他们接触的都是一句一句的话或者可能要把这些句子组合在一起,组合成一篇文章。例如下图中的机器翻译,机器翻译在翻译的过程中会从之前学习到的信息中,通常表示价格昂贵的词组是high price 而不是large price ,也就是说high price出现的概率大于large price,所以当你需要机器来翻译价格昂贵的意思的时候,它会翻译成high price。

接下来,我们就围绕概率值来说一下语言模型究竟是怎么一回事。如下图所示:句子“我今天下午打篮球”可以划分成5个词“我”、“今天”、“下午”、“打”和“篮球”。语言模型P(S)等于“我”出现的概率与“今天”在“我”出现的前提下出现的概率与“下午”在“我今天”出现的前提下出现的概率与“打”在“我今天下午”出现的前提下出现的概率与“篮球”在“我今天下午打”出现的前提下出现的概率的乘积。其中的(条件)概率p(w1),p(w2|w1),p(w3|w1,w2),…p(wn|w1,w2,…,wn-1)就是语言模型的参数,若这些参数全部算得,那么对于给定的一个句子,就可以很快地算出相应的p(s)。

这种p(s)的定义使得一句话的概率都跟之前出现过的所有的词有关,但是如果句子过长,可能最后面的词跟最前面的词没有太大的关系了,这就会导致数据过于稀疏和参数空间过大的问题。为了解决这些问题,进行了如下图所示的假设:

通常我们把上面这种假设的模型称为n-gram模型。n-gram的意思就是指当我们指定n=1,就相当于跟前面的1个词相关,指定n=2,就相当于跟前面的2个词相关。比如下图的例子,我们在原始的语料库中统计了所有的单词 “i”、“want”、“to”、“eat”、“chinese”、“food”、“lunch”和“spend”在语料库中出现的次数,如下图所示i在语料库中出现的次数是2533.下图中c(wi-1,wi)部分第一个图的第一行是指在i出现的前提下,后面会出现“i want to eat chinese food lunch spend”中的每一个词的次数。相应的下图中c(wi-1,wi)部分第二个图的第一行是指在i出现的前提下,后面会出现“i want to eat chinese food lunch spend”中的每一个词的概率。比如i在语料库中出现的次数是2533,在i出现的前提下,后面紧跟着出现i的次数是5次,所以,P(i|i)=5/2533约等于0.002。

在此,我们知道了语料库中每个单词单独出现的概率以及语料库中的每个单词在其他单词出现的条件下出现的概率,这样就可以计算一个p(s)了。当n=1时,比如我们要计算一句话“I want chinese food”的概率:
P(i want chinese food) =p(i)*p(want|i)*p(chinese|want)*p(food|chinese) =2533/(2533+927+2417+746+158+1093+341+278)*0.33*0.0065*0.52
如上可得若所需参数已经全部算得,那么给定一个句子,我们就可以算出相应的p(s)。看起来好像很简单,但是,具体实现起来还是有点麻烦。例如。先来看看模型参数的个数。刚才是考虑一个给定的长度为L的句子,就需要计算L个参数。在此不妨假设语料库对应词典的大小(即词汇量)为N,那么,如果考虑长度为L的任意句子,理论上就有NL种可能,而每种可能都需要计算L个参数,总共就需要计算LNL个参数。如下图所示,假设词典的大小是2*105,当n=1时,模型参数数量是2*105,当n=2时,模型参数数量是(2*105)2, 当n=n时,模型参数数量是(2*105)n。这个量级还是蛮吓人的。此外,这些概率计算好后,还得保存下来,因此,存储这些信息也需要很大的内存开销。显然n不能取得太大,实际应用中最多的是采用n=3的三元模型。

词向量
上面我们说了一些语言模型和自然语言处理的问题,下面我们来说一下自然语言处理的本质。这个本质是什么呢?我们想一想,无论是一句话还是一篇文章,它都是由一个词一个词组成的,这些词是我们可以利用的最基本的单位,那我们应该怎么让机器利用这个词呢?机器是认识数值型的数据的,所以说我们首先要把词做一个转换,转换成计算机认识的东西。word2vec也叫word embeddings,中文名“词向量”,作用就是将自然语言中的字词转为计算机可以理解的稠密向量(Dense Vector)。在word2vec出现之前,自然语言处理经常把字词转为离散的单独的符号,也就是One-Hot Encoder。

比如上面的这个例子,在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0。但是使用One-Hot Encoder有以下问题。一方面,城市编码是随机的,向量之间相互独立,看不出城市之间可能存在的关联关系。其次,向量维度的大小取决于语料库中字词的多少。如果将世界所有城市名称对应的向量合为一个矩阵的话,那这个矩阵过于稀疏,并且会造成维度灾难。
使用Vector Representations可以有效解决这个问题。Word2Vec可以将One-Hot Encoder转化为低维度的连续值,也就是稠密向量,并且其中意思相近的词将被映射到向量空间中相近的位置。
如果将embed后的城市向量通过PCA降维后可视化展示出来,那就是这个样子。

我们可以发现,华盛顿和纽约聚集在一起,北京上海聚集在一起,且北京到上海的距离与华盛顿到纽约的距离相近。也就是说模型学习到了城市的地理位置,也学习到了城市地位的关系。向量空间模型在NLP(自然语言处理)中主要依赖的假设是Distributional Hypothesis,即在相同语境中出现的词语意也相近。再如下图右边所示,若单词意思是相近的,那么他们会被映射到向量空间中相近的位置。下图左边的expect就是我们期望由词转化成的多少维度的稠密向量,向量的维度和向量里面的数据都是我们可以指定的。如果我们想构建出更复杂的向量,可以让维度大一些,如果我们想构建出简单的向量,可以让维度小一些。一般可以取[-1,1]之间的数字,有正有负。

再比如下面这个例子,可以帮助我们更好的理解词向量的工作原理,特将其介绍如下:
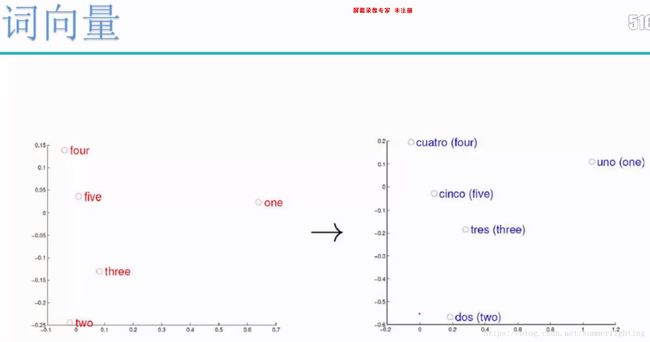
考虑英语和西班牙语两种语言,通过训练分别得到它们对应的词向量空间(左图和右图)。
虽然现在是两种不同的语言,但是观察左、右两幅图,容易发现:五个词在两个向量空间中的相对位置差不多,这说明我们构造出来词向量跟词的拼写是无关的,与语意的环境,语意的逻辑性是相关的,也说明了两种不同语言对应向量空间的结构之间具有相似性,从而进一步说明了在词向量空间中利用距离刻画词之间的相似性的合理性。
神经网络模型
词向量模型跟深度学习是怎样挂钩的呢?我们在这里先来说一下神经网络模型:
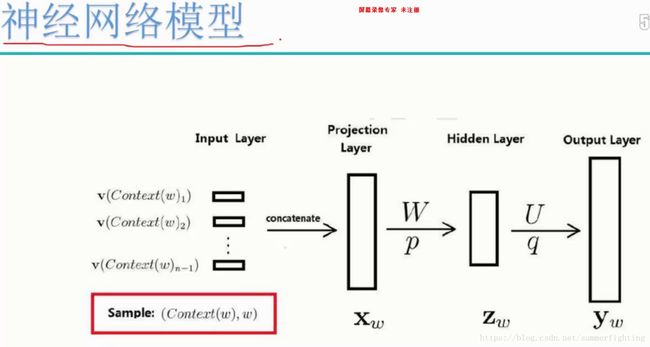
如图所示:
训练样本(Sample):(Context(w),w)包括前n-1个词分别的向量,假定每个词的向量大小为m。随机初始化这些向量,通过神经网络,我们可以不断的优化求解,一方面我们求解的是神经网络中的一系列的参数,另一方面我们求解的是我们的输入层的词向量,随着训练的进行不断被更新,这里跟我们传统的神经网络是不一样的。传统的神经网络优化的只是输入层与隐藏层以及隐藏层与输出层之间的参数。
投影层(Projection Layer):(n-1)*m首尾拼接起来的大向量
输出层:yw = (yw,1, yw,2,…, yw,n)T表示上下文为Context(w)时,下一个词恰好为词典中第i个词的概率
softmax归一化:pwContextw= eyw,iwi=1Neyw,i
与n-gram模型相比,神经网络模型(在此更确切的为神经概率语言模型)有什么优势呢?由于向量空间模型在NLP(自然语言处理)中主要依赖的假设是Distributional Hypothesis,即在相同语境中出现的词语意也相近。所以它的优点如下:

如上图所示:按照n-gram模型的做法,p(S1)肯定会远大于P(S2)。注意,S1和S2的唯一区别在于 “咖”和 “吧”,而这两个词无论是句法还是语义上都扮演了相同的角色,因此,p(S1)和P(S2)应该都很相近才对。然而由神经网络模型算得的p(S1)和P(S2)是大致相等的。原因在于:(1)在神经网络模型中假定了“相似的”词对应的词向量也是相似的;(2)概率函数关于词向量是光滑的,即词向量中的一个小变化对概率的影响也只是一个小变化。这样一来,对于下面这些句子

只要在语料库中出现一个,其他句子的概率也会相应地增大。
CBOW和Skip-gram
有了前面的准备,本节正式开始介绍word2vector中用到的两个重要的模型(Continuous Bag-of-Words Model)和Skip-gram模型(Continuous Skip-gram Model).
由下图可见,两个模型都包含三层:输入层、投影层和输出层。前者是在已知当前词wt的上下文wt-2, wt-1, wt+1, wt+2,的前提下预测当前词wt;而后者恰恰相反,是在已知当前wt的前提下,预测其上下文wt-2, wt-1, wt+1, wt+2。
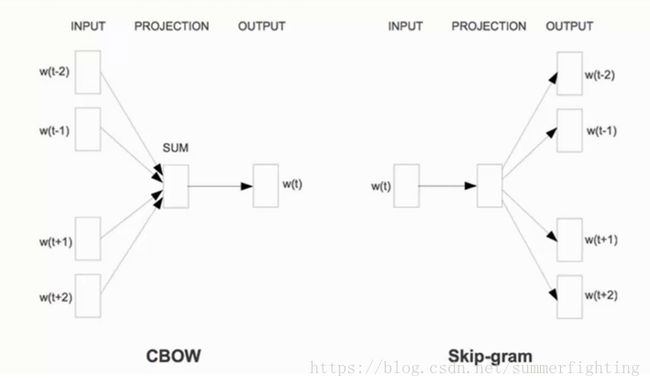
对于CBOW和Skip-gram两个模型,word2vector给出了两套框架,他们分别基于Hierarchical Softmax和Negative Sampling 来进行设计。详细的介绍请参见如下网址:
https://blog.csdn.net/itplus/article/details/37969979
https://blog.csdn.net/itplus/article/details/37998797
gensim库的应用简介
简单介绍一下gensim库。
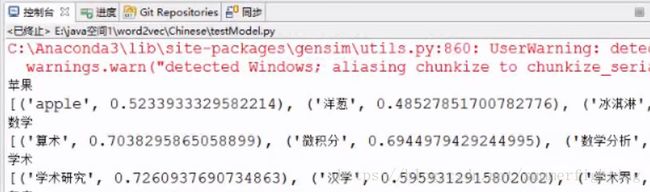
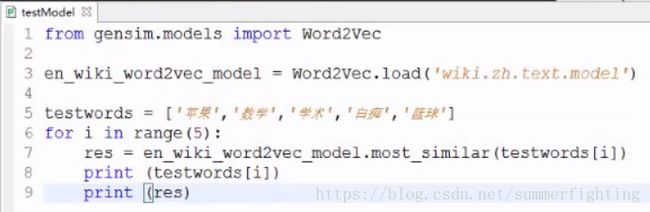
gensim库是一个已经封装好了word2vec模型的强大的库。我们可以直接拿这个库来训练一下从维基百科里面下载下来的中文数据,得到一个训练模型wiki.zh.text.model,如下图所示,通过我们训练好的模型wiki.zh.text.model,当我们拿到列表testwords中的词的向量之后,我们现在就可以拿这个词向量做一个对比,找一下这个词向量跟什么词最相近,从result中可以看出建模结果是不错的。
result: